

Говорить о распространённости списков не приходится. Список хранит внутри себя данные, которые отображает. Но за редким исключением, список не является первичным источником данных, они в него копируются из такового, а затем, актуальность скопированных данных, то есть их соответствие текущим данным из первичного источника становится сомнительной, поэтому возникает необходимость обновлять список.
Либо напротив списка расположена кнопка «Обновить», либо обновление происходит периодично (например раз в 30 секунд), либо первичный источник (например сервер) сообщает, что пора бы обновить список. Не это важно.
Суть проблемы
К сожалению, большинство программистов делают обновление самым «грязным» и грубым способом: сначала полностью очищают список, затем добавляют в него элементы, полученные от первичного источника.
Давайте разберём, почему это плохо и некрасиво:
- В первую очередь это не соответствует принципу лени. Если список отображает файлы в какой-то папке, и пару файлов кто-то удалил, нет совершенно никакого смысла удалять 1998 элементов списка из 2000 существующих, чтобы потом заново добавить 1998 удалённых элементов. Это много действий, много бесполезных действий. Мало действий — это удалить 2 элемента из 2000. А не удалить 2000 и добавить 1998.
- Если список — графический, пользователь увидит ужасный визуальный спецэффект, заключающийся в мерцании.
- Если ввести такое понятие, как цена действия — то добавление всегда дороже, чем удаление. Почти всегда итеративное добавление требует выделение всё новой и новой памяти. В случае выделения одинакового суммарного объёма, выделение мелкими кусочками всегда неэффективнее, чем одним разом. Потому что память фрагментируется, нужно искать свободные регионы или заниматься дефрагментацией. Удаление не требует ничего такого. Более того, удаление всегда можно оптимизировать, делая вместо самого физического удаления выставление отметки «удалено», и откладыванием самого физ. удаления до благоприятного времени.
- Если список — элемент интерфейса, в котором возможно выделение пунктов, то выделение обычно сбрасывается, потому что сперва список полностью очищается. Сам список не способен догадаться, что элемент, который был выделенным на момент удаления, вот-вот вновь будет добавлен: вновь добавленный элемент не получит выделения.
В общем, этот вариант плох всем: временем выполнения, эффективностью, вычислительной сложностью всей процедуры, графическими спецэффектами и прочими недостатками.
Первый шаг улучшения
Вместо того, чтобы полностью очищать список, а затем запрашивать новые данные и заполнять ими теперь уже пустой список, сделаем кое-что чуть более интеллектуальное. Мы не будем очищать список первым делом. Вместо этого, мы помечаем все элементы списка специальным флагом, например, назовём его «грязный» («dirty»). Далее мы запрашиваем данные из первичного источника. Для каждого пришедшего от первичного источника элемента, мы ищем соответствующий элемент в списке. Если он там уже есть, снимаем с этого элемента флаг «грязный». Если его там нет — добавляем его со снятым флагом. Только когда мы обработали все пришедшие от первичного источника элементы, мы проходимся по всему нашему списку и удаляем все те пункты, у которых флаг «грязный» остался установленным.
Плюсы подхода:
- Мы не удаляем элемент из списка, если соответствующий ему элемент из жизни никуда не делся. Из списка удаляются только те элементы, которые исчезли в жизни, то есть не были получены от первоисточника. Нет лишних трудоёмких действий.
- Как следствие, если какой-то из оставшихся элементом был выделен, он останется выделен. Если это ListView, и привязка к сетке выключена, и элемент был сдвинут относительно сетки, он останется сдвинутым на ту же величину.
Минусы подхода:
- Если в списке на момент начала обновления было M элементов, а при обновлении поступила информация об N элементах, то нужено, в общем случае, произвести M × N операций поиска/сверки.
Я понимаю, что многие не делают так, потому что это требует написать больше кода, и при том, им кажется, что поиск соответствия между элементом нашего списка и элементом, пришедшим от первичного источника, будет отнимать больше вычислительных операций, чем полное обнуление списка с его последующим заполнением новыми актуальным данными с нуля. Это верно разве что для массивов. Для списков (в программистском смысле слова), а особенно для списков в смысле графического элемента пользовательского интерфейса это почти всегда неправда. Внимание: дешевле отметить «устаревшие» элементы и затем их разом удалить, чем обнулять список, и заполнять заново.
В общем, этот способ следует применять всегда, когда операций поиска/сравнения дешевле, чем операция вставки нового элемента. А она почти всегда дешевле. Потому что обычно элемент, это идентификатор, и ещё куча данных. Для поиска/сравнения нужна работа только с идентификатором, а для добавления нужна работа с ним и ещё со всей той кучей данных, которая с идентификатором связана.
Второй шаг улучшения
На самом деле, способ с составлением списка «устаревших элементов» гораздо лучше, чем способ «всё разрушить и построить заново». Но и он плох, потому что составление списка требует много операций поиска/сравнения. Но чаще всего есть обстоятельство, которые позволяют и от этого способа отказаться в пользу чего-то более эффективного.
Делом в том, что гораздо чаще это именно так: данных от первичного источника приходят в упорядоченном виде, а не совершенно случайном. Например, если вы перечисляете файлы в каталоге, и не важно, VB-шной ли функцией Dir(), или WinAPI-функциями, список файлов вам от первичного источника будет приходить в алфавитном порядке. Если первичный источник — БД, а вы делаете SQL-запрос — тем лучше, ибо SQL-запрос позволяет вам упорядочить данные любым удобным образом. Да и хранятся данные обычно упорядоченно, и именно поэтому чаще всего и выдаются в хорошем порядке, а не абы как.
Это обстоятельство даёт нам достаточно большое преимущество: теперь нам не нужно составлять список, для которого приходилось делать много операций поиска/сравнения. То, что мы будем применять, я по-своему называю методом двух курсоров. Один курсор соответствует выборке из первичного источника, и нам мало интересен, а второй курсор соответствует нашему обходу нашего же списка.
Как я у же сказал, способ подходит там, где данные выдаются первичным источником упорядоченно. Строго говоря, способ применим так, где любые два элемента могут быть сравнены, и где отношение порядка транзитивно. Либо сами элементы должны быть легко сравнивыми, либо у элементов должны быть сравнимые идентификаторы, либо в соответствие элементам должно быть легко поставить легко-вычислимый хеш.
Логика работ такая:
- В начале обновления мы устанавливаем наш курсор на первый элемент нашего списка. Начинаем итеративно получать элементы от первичного источника.
- Получаем один элемент от первичного источника.
- Сравниваем с элементом, на который указывает наш курсор:
- Полученный элемент меньше: добавляем его перед курсором, переходим к пункту 2.
- Полученный элемент равен: передвигаем курсор на 1 элемент вперёд, переходим к пункту 2.
- Полученный элемент больше: удаляем элемент, на который указывает курсор, переходим к пункту 3.
- Если данные от первичного источника кончились, а наш курсор не дошёл до конца, удаляем все элементы начиная с текущей позиции курсора.
Или картинкой:
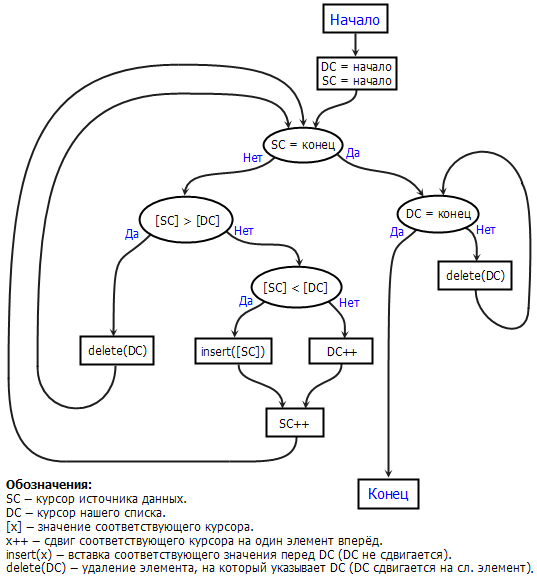
Бонус подхода должен быть очевиден: помимо такого же количества операций вставки/удаления, как и в предыдущем способе, число операций поиска/сравнения уменьшается с M × N до min(M, N) благодаря тому, что из-за упорядоченности исходных данных не нужно вести список кандидатов на уделение, можно удалять их сразу.
Иными словами, если первыми пунктами нашего списка идут «Алина» и «Алла», а от первичного источника приходит «Борис», то первые два элемента Алину и Аллу смело можно удалять уже сейчас — от первичного источника они уже гарантированно не придут.
Круто!
И поскольку упорядоченные данные от первичного источника приходят гораздо чаще, чем неупорядоченные — это именно тот способ, который вы должны по возможности всегда использовать, если нет каких-то особых тонких моментов, которые делают его не самым лучшим. Хотя я с ходу не придумаю такой случай: ваша лень, то есть необходимость писать больше кода, чем требует нулевой «самый некрасивый вариант» — не считаются.
Но и это не идеал.
Приближаясь к идеалу
Я сторонник как минимум двух вещей:
- Event-driven парадигмы, причём, конечно же, не ограничиваясь событиями COM-модели
- Дифференциального подхода
Второй подход гласит: применяйте дифференцирование в широком смысле слова везде, где это возможно. Часто проще не по входным данным вычислять выходные, а по изменению входных вычислить изменение выходных. Даже производные простых мат. функций легче в плане вычисления, чем сами функции.
В нашем случае, с учётом event-driven-подхода, это означает, что вам нужно организовать взаимодействие вашего списка с первичным источником данных так, чтобы список получал уведомления от первичного источника о добавляющихся или удаляемых элементах в точности тогда, когда они добавляются/удаляются.
Поддерживать список в актуальном состоянии постоянно гораздо менее накладно, чем время от времени устранять значительный рассинхрон между нашим списком и первичным источником. Особенно это актуально для клиент-серверных систем, работающих по сети. Во всех предыдущих случаях вам приходилось при обновлении списка пересылать между собой и первичным источником весь набор элементов. Этот очень неэффективно, если элементов много, а обновление достаточно частое. Вы оптимизировали только алгоритм обновления, но не оптимизировали передачу данных. В данном же случае передаются только нужные данные: какие элементы были добавлены, какие были удалены (если были). Никаких данных, относящихся к нетронутым элементам — не передаётся.
Более того, такой подход позволит вам отобразить список в многих местах одновременно: обновляться они все будут тоже одновременно, а не по таймеру, плюс для обновления всех будет достаточно одного уведомления о события, в отличие от предыдущих случаев, где каждый список создавал свой отдельный трафик между первичным источником.
Итак, вот вам нечто похожее на паттерн проектирования. Объект-коллекция с обязательными событиями ItemAdded и ItemRemoved. На события одного такого объекта может подписаться сколько угодно заинтересованных сторон-списков. Причём под списками здесь понимаются как собственно сами списки (чисто программные или графические), так и, например, event-hub-ы, которые будут рассылать информацию об изменении дальше.
И никакой энумерации. Если вы в самом начале, и ваш список вообще пуст, и вам нужна не информация об изменениях списка, а сам список, просто сообщите это источнику (вернее его представителю — объекту с событиями) — все элементы списка должны как бы заново родиться через событие ItemAdded.
Полностью откажитесь от классической энумерации, и вместо этого расширьте возможность получить уведомления об добавляющихся/исчезающих сейчас элементах до возможности получать уведомления об добавившихся/удалившихся элементах с какого-то момента. Просто сделайте так, чтобы вы могли указать источнику данных временную отметку, данными, актуальными на момент которой вы обладаете. Пусть источник сообщит вам через всё тот же механизм событий обо всех изменениях, произошедших с того времени. А после — пусть сообщает об изменениях, происходящих сейчас.
Такой подход максимально эффективен в соответствии с принципом лени.
Единственное исключение, когда этот случай проигрывает классической энумерации, это случай, когда элементы добавляются и сразу же уничтожаются чрезвычайно часто, и сами эти факты имеет очень малое значение. То есть да, энумерация будет лучше, если каждую секунду 1000 элементов успевают добавиться и исчезнуть по 50 раз каждый, и при том важность этих событий — никакая.
Но даже в этом случае куда красивее будет подход с событиями: просто введите фильтр, сделайте так, чтобы уведомления о новых элементах приходили вам только тогда, когда эти элементу просуществовали достаточно долго, не удалившись. Пусть, если персонально вам не нужны «сверхновые элементы», уведомления о них персонально вам высланы не будут (а кому-то другому, то есть какому-то другому агенту взаимодействия — будут). При этом вы полностью избавитесь от шума из нежелательных элементов, в отличие от случая с энумерацией, которая будет включать в себя все существовавшие на момент создания снимка (снапшота) короткоживущие элементы.
Взгляд с другой стороны
Нет, не с противоположенной, а немного сбоку. Помимо алгоритма обновления, выбор между которыми позволяет вам выбирать стратегию того, как и когда какие элементу удалять и добавлять, можно ещё хорошо подумать о том, как подходить к самим операциями удаления добавления. Вернее, к сериям таких операций. Я бы здесь посоветовал «транзактивный подход», но эта тема достойна отдельной статьи.
Итак, правильные приложения обновляют свои списки красиво.

