abonent_2000@inbox.ru
–Ъ–∞–Ї –њ–Њ–±–µ–і–Є—В—М "Out of memory"?
–Я—А–∞–≤–Є–ї–∞ —Д–Њ—А—Г–Љ–∞
–Ґ–µ–Љ—Л, –≤ –Ї–Њ—В–Њ—А—Л—Е –±—Г–і–µ—В —Б–љ–∞—З–∞–ї–∞ –љ–∞–њ–Є—Б–∞–љ–Њ ¬Ђ—З—В–Њ –љ—Г–ґ–љ–Њ —Б–і–µ–ї–∞—В—М¬ї, –∞ –Ј–∞—В–µ–Љ –њ—А–Њ—Б—М–±–∞ ¬Ђ–њ–Њ–Љ–Њ–≥–Є—В–µ¬ї, –±—Г–і—Г—В –Ј–∞–Ї—А—Л—В—Л.
–І–Є—В–∞–є—В–µ —В—А–µ–±–Њ–≤–∞–љ–Є—П –Ї —Б–Њ–Ј–і–∞–≤–∞–µ–Љ—Л–Љ —В–µ–Љ–∞–Љ.
–Ґ–µ–Љ—Л, –≤ –Ї–Њ—В–Њ—А—Л—Е –±—Г–і–µ—В —Б–љ–∞—З–∞–ї–∞ –љ–∞–њ–Є—Б–∞–љ–Њ ¬Ђ—З—В–Њ –љ—Г–ґ–љ–Њ —Б–і–µ–ї–∞—В—М¬ї, –∞ –Ј–∞—В–µ–Љ –њ—А–Њ—Б—М–±–∞ ¬Ђ–њ–Њ–Љ–Њ–≥–Є—В–µ¬ї, –±—Г–і—Г—В –Ј–∞–Ї—А—Л—В—Л.
–І–Є—В–∞–є—В–µ —В—А–µ–±–Њ–≤–∞–љ–Є—П –Ї —Б–Њ–Ј–і–∞–≤–∞–µ–Љ—Л–Љ —В–µ–Љ–∞–Љ.
–°–Њ–Њ–±—Й–µ–љ–Є–є: 11
• –°—В—А–∞–љ–Є—Ж–∞ 1 –Є–Ј 1
- Readers
- –Э–∞—З–Є–љ–∞—О—Й–Є–є

- –°–Њ–Њ–±—Й–µ–љ–Є—П: 2
- –Ч–∞—А–µ–≥–Є—Б—В—А–Є—А–Њ–≤–∞–љ: 03.05.2003 (–°–±) 15:17
–Ъ–∞–Ї –њ–Њ–±–µ–і–Є—В—М "Out of memory"?
![]() Readers » 03.05.2003 (–°–±) 15:30
Readers » 03.05.2003 (–°–±) 15:30
–Я—А–Њ–≥—А–∞–Љ–Љ–Њ–є —Б–Њ–Ј–і–∞—О—В—Б—П 8 –Љ–∞—Б—Б–Є–≤–Њ–≤ Single –њ–Њ 10 –Љ–ї–љ. —Н–ї–µ–Љ–µ–љ—В–Њ–≤. –Т –њ—А–Њ—Ж–µ—Б—Б–µ –≤—Л—Б–Ї–∞–Ї–Є–≤–∞–µ—В –Њ–Ї–љ–Њ "Out of memory". –Ь–Њ–ґ–љ–Њ –ї–Є –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –љ–∞–њ—А–Є–Љ–µ—А –Ї–∞–Ї—Г—О-–љ–Є—В—М –≤–Є—А—В—Г–∞–ї—М–љ—Г—О –њ–∞–Љ—П—В—М ?–Р —В–Њ –≤–Є–і–µ–ї –њ—А–Њ–≥—А–∞–Љ–Љ—Л, –њ–Њ–Ї–∞–Ј—Л–≤–∞—О—Й–Є–µ –µ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ, –∞ –Ї–∞–Ї –µ–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –љ–Є–≥–і–µ –љ–µ –љ–∞–њ–Є—Б–∞–љ–Њ  .
.
abonent_2000@inbox.ru
abonent_2000@inbox.ru
- RayShade
- Scarmarked

-

- –°–Њ–Њ–±—Й–µ–љ–Є—П: 5511
- –Ч–∞—А–µ–≥–Є—Б—В—А–Є—А–Њ–≤–∞–љ: 02.12.2002 (–Я–љ) 17:11
- –Ю—В–Ї—Г–і–∞: Russia, Saint-Petersburg
![]() RayShade » 03.05.2003 (–°–±) 15:39
RayShade » 03.05.2003 (–°–±) 15:39
–І—В–Њ —П –Љ–Њ–≥—Г –Њ—В–≤–µ—В–Є—В—М. –Ф–ї—П —Е—А–∞–љ–µ–љ–Є—П —В–∞–Ї–Њ–≥–Њ –Ї–Њ–ї–Є—З–µ—Б—В–≤–∞ –і–∞–љ–љ—Л—Е –њ–Њ—В—А–µ–±—Г–µ—В—Б—П –Њ–Ї–Њ–ї–Њ 320–Ь –њ–∞–Љ—П—В–Є.
–Э–µ –і—Г–Љ–∞—О, —З—В–Њ —В—Г—В —З–µ–Љ —В–Њ –Љ–Њ–ґ–љ–Њ –њ–Њ–Љ–Њ—З—М. –°–Њ–≤–µ—В –Њ–і–Є–љ - –њ–µ—А–µ–і–µ–ї–∞–є –њ—А–Њ–≥—А–∞–Љ–Љ—Г. –Ю–±—Л—З–љ–Њ —В–∞–Ї–Є–µ –Њ–≥—А–Њ–Љ–љ—Л–µ –Љ–∞—Б—Б–Є–≤—Л –і–∞–љ–љ—Л—Е –≤ –≤–Є–і–µ –Љ–∞—Б—Б–Є–≤–Њ–≤ —Н—В–Њ –њ—А–Є–Ј–љ–∞–Ї —В–Њ–≥–Њ —З—В–Њ –њ—А–Њ–≥–∞ –љ–∞–њ–Є—Б–∞–љ–∞ –Ї—А–Є–≤–Њ–≤–∞—В–Њ.
–Э–µ –і—Г–Љ–∞—О, —З—В–Њ —В—Г—В —З–µ–Љ —В–Њ –Љ–Њ–ґ–љ–Њ –њ–Њ–Љ–Њ—З—М. –°–Њ–≤–µ—В –Њ–і–Є–љ - –њ–µ—А–µ–і–µ–ї–∞–є –њ—А–Њ–≥—А–∞–Љ–Љ—Г. –Ю–±—Л—З–љ–Њ —В–∞–Ї–Є–µ –Њ–≥—А–Њ–Љ–љ—Л–µ –Љ–∞—Б—Б–Є–≤—Л –і–∞–љ–љ—Л—Е –≤ –≤–Є–і–µ –Љ–∞—Б—Б–Є–≤–Њ–≤ —Н—В–Њ –њ—А–Є–Ј–љ–∞–Ї —В–Њ–≥–Њ —З—В–Њ –њ—А–Њ–≥–∞ –љ–∞–њ–Є—Б–∞–љ–∞ –Ї—А–Є–≤–Њ–≤–∞—В–Њ.
- areh
- –Я–Њ—Б—В–Њ—П–ї–µ—Ж

- –°–Њ–Њ–±—Й–µ–љ–Є—П: 530
- –Ч–∞—А–µ–≥–Є—Б—В—А–Є—А–Њ–≤–∞–љ: 02.12.2002 (–Я–љ) 12:28
- –Ю—В–Ї—Г–і–∞: –†–Ю–°–°–Ш–ѓ, –°–∞–ї–µ—Е–∞—А–і
![]() areh » 03.05.2003 (–°–±) 16:35
areh » 03.05.2003 (–°–±) 16:35
–Ґ–µ–Њ—А–Є—В–Є—З–µ—Б–Ї–Є, –і–ї—П –ї—О–±–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ (–≤ 32 —А–∞–Ј—А—П–і–љ–Њ –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ–Њ–є —Б–Є—Б—В–µ–Љ–µ) –і–Њ–ї–ґ–љ–Њ –≤—Л–і–µ–ї—П—В—М—Б—П 4 –У–С –њ–∞–Љ—П—В–Є, —В.–µ. 2^32 -1, –∞ —Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ–Њ —В–µ–Њ—А–Є—В–Є—З–µ—Б–Є, –≤—Б—О —Н—В—Г —Е—А–µ–љ—М –≤ –њ–∞–Љ—П—В—М –Ј–∞–њ–Є—Е–љ—Г—В—М –Љ–Њ–ґ–љ–Њ, –љ–Њ –Ї —Б–Њ–ґ–∞–ї–µ–љ–Є—О –≤ –Т–С —В–µ–Њ—А–Є—В–Є—З–µ—Б–µ–Є –Љ–Њ–ґ–љ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —В–Њ–ї—М–Ї–Њ 2 –У–С –њ–∞–Љ—П—В–Є (—В.–Ї. —Г –љ–∞—Б –љ–µ—В 32 —А–∞–Ј—А—П–і–љ–Њ–≥–Њ –±–µ–Ј–Ј–љ–∞–Ї–Њ–≥–Њ —З–Є—Б–ї–∞).
–Ш—В–∞–Ї —Б–Њ–≤–µ—В:
1. –Я–Њ–њ—А–Њ–±–Њ–≤–∞—В—М –≤—Б—С –Ј–∞—Б—Г–љ—Г—В—М –≤ –њ–∞–Љ—П—В—М —З–µ—А–µ–Ј –њ—А—П–Љ–Њ–µ –Њ–±—А–∞—Й–µ–љ–Є–µ –Ї –Р–Я–Ш
(—А–∞–±–Њ—В–∞ —Б –Ї—Г—З–∞–Љ–Є –њ–∞–Љ—П—В–Є, —В.–µ. —Б HEAP)
–Ш—В–∞–Ї —Б–Њ–≤–µ—В:
1. –Я–Њ–њ—А–Њ–±–Њ–≤–∞—В—М –≤—Б—С –Ј–∞—Б—Г–љ—Г—В—М –≤ –њ–∞–Љ—П—В—М —З–µ—А–µ–Ј –њ—А—П–Љ–Њ–µ –Њ–±—А–∞—Й–µ–љ–Є–µ –Ї –Р–Я–Ш
(—А–∞–±–Њ—В–∞ —Б –Ї—Г—З–∞–Љ–Є –њ–∞–Љ—П—В–Є, —В.–µ. —Б HEAP)
- RayShade
- Scarmarked
-
- –°–Њ–Њ–±—Й–µ–љ–Є—П: 5511
- –Ч–∞—А–µ–≥–Є—Б—В—А–Є—А–Њ–≤–∞–љ: 02.12.2002 (–Я–љ) 17:11
- –Ю—В–Ї—Г–і–∞: Russia, Saint-Petersburg
![]() RayShade » 03.05.2003 (–°–±) 16:38
RayShade » 03.05.2003 (–°–±) 16:38
–Ф–µ–ї–Њ –љ–µ –≤ –њ–∞–Љ—П—В–Є –Є –≤—Л–і–µ–ї–µ–љ–Є –µ–µ –і–ї—П –њ—А–Њ—Ж–µ—Б—Б–∞. –Ш –љ–µ –љ–∞–і–Њ –њ—Л—В–∞—В—М—Б—П –љ–∞—Б–Є–ї–Њ–≤–∞—В—М —Б–Є—Б—В–µ–Љ—Г –Ї—А–Є–≤—Л–Љ —Б–Њ—Д—В–Њ–Љ. VB —А–∞—Б–њ–Њ–ї–∞–≥–∞–µ—В –і–Њ—Б—В–∞—В–Њ—З–љ—Л–Љ–Є —Б—А–µ–і—Б—В–≤–∞–Љ–Є –і–ї—П —А–µ—И–µ–љ–Є—П –њ—А–∞–Ї—В–Є—З–µ—Б–Ї–Є –ї—О–±–Њ–є –Ј–∞–і–∞—З–Є. –Ґ–∞–Ї —З—В–Њ –µ—Б–ї–Є —Н—В–Њ –љ–µ —Г–і–∞–µ—В—Б—П —Б–і–µ–ї–∞—В—М - —В–Њ —Г–≤—Л, —Н—В–Њ –њ—А–Є–Ј–љ–∞–Ї –Ї—А–Є–≤–Є–Ј–љ—Л –∞–ї–≥–Њ—А–Є—В–Љ–∞.
- Readers
- –Э–∞—З–Є–љ–∞—О—Й–Є–є
- –°–Њ–Њ–±—Й–µ–љ–Є—П: 2
- –Ч–∞—А–µ–≥–Є—Б—В—А–Є—А–Њ–≤–∞–љ: 03.05.2003 (–°–±) 15:17
![]() Readers » 03.05.2003 (–°–±) 17:14
Readers » 03.05.2003 (–°–±) 17:14
–Ю—Б—А–µ–і–љ—П–µ—В—Б—П –Њ–±—К–µ–Љ –њ—А–Њ–і–∞–ґ –≤ —Б–µ–Љ–Є–Љ–µ—А–љ–Њ–Љ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–µ. –Ъ–∞–ґ–і–∞—П –Њ—Б—М –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–∞ —А–∞–Ј–±–Є—В–∞ –љ–∞ 10 –Ї–Њ–Њ—А–і–Є–љ–∞—В. –°–Њ–Њ—В–≤–µ—В—Б—В–≤–µ–љ–љ–Њ, –Ї–∞–ґ–і–Њ–µ –Ј–љ–∞—З–µ–љ–Є–µ –Њ–±—К–µ–Љ–∞ –њ—А–Њ–і–∞–ґ –Є–Љ–µ–µ—В —Б–µ–Љ—М –Ї–Њ–Њ—А–і–Є–љ–∞—В, –≤–Њ–Ј–Љ–Њ–ґ–љ—Л—Е —Б–Њ—З–µ—В–∞–љ–Є–є —Н—В–Є—Е –Ї–Њ–Њ—А–і–Є–љ–∞—В –њ–Њ–ї—Г—З–∞–µ—В—Б—П 10^7 , –Є—В–Њ–≥–Њ 7*10^7(–Ј–љ–∞—З–µ–љ–Є–є –Ї–Њ–Њ—А–і–Є–љ–∞—В)+10^7(–Ј–љ–∞—З–µ–љ–Є–є –Њ–±—К–µ–Љ–Њ–≤ –њ—А–Њ–і–∞–ґ)=80 –Љ–ї–љ. –Ј–љ–∞—З–µ–љ–Є–є. –У–і–µ —Е—А–∞–љ–Є—В—М —Н—В—Г –њ—А–Њ—А–≤—Г —Б –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М—О –±—Л—Б—В—А–Њ–є —Б—В–∞—В–Є—Б—В–Є—З–µ—Б–Ї–Њ–є –Њ–±—А–∞–±–Њ—В–Ї–Є? –Ш –њ—А–Є—З–µ–Љ —В—Г—В –∞–ї–≥–Њ—А–Є—В–Љ?
- Sebas
- –Э–µ—Г–ї–Њ–≤–Є–Љ—Л–є –Ф–ґ–Њ
-

- –°–Њ–Њ–±—Й–µ–љ–Є—П: 3626
- –Ч–∞—А–µ–≥–Є—Б—В—А–Є—А–Њ–≤–∞–љ: 12.02.2002 (–Т—В) 17:25
- –Ю—В–Ї—Г–і–∞: —Б—В–Њ–ї—М–Ї–Њ –љ–∞–≥–ї–Њ—Б—В–Є —В–∞–Ї–Є–µ –≤–Њ–њ—А–Њ—Б—Л –Ј–∞–і–∞–≤–∞—В—М
![]() Sebas » 03.05.2003 (–°–±) 19:52
Sebas » 03.05.2003 (–°–±) 19:52
–Х—Б—В—М –Ј–∞–Љ–∞—З–∞—В–µ–ї—М–љ–∞—П –±–Є–±–ї–∞ MultiDimension ADO
- –ѓ –љ–Є–Ї–Њ–≥–і–∞ –љ–µ –њ–Њ–љ–Є–Љ–∞–ї, –њ–Њ—З–µ–Љ—Г –Њ–љ–Є –њ—А–Є—Е–Њ–і—П—В –Ї–Њ –Љ–љ–µ —З—В–Њ–±—Л —Г–Љ–Є—А–∞—В—М?
sebas<-@->mail.ru
sebas<-@->mail.ru
- Urvin
- –Я–Њ—Б—В–Њ—П–ї–µ—Ж
-

- –°–Њ–Њ–±—Й–µ–љ–Є—П: 518
- –Ч–∞—А–µ–≥–Є—Б—В—А–Є—А–Њ–≤–∞–љ: 04.06.2003 (–°—А) 10:47
- –Ю—В–Ї—Г–і–∞: —Б –Ь–∞—А—Б–∞
![]() Urvin » 07.06.2003 (–°–±) 4:17
Urvin » 07.06.2003 (–°–±) 4:17
–Р –Є—Й–µ –Љ–Њ–ґ–љ–∞ —О–Ј–∞—В—М –∞—Б—Б–µ–Љ–±–ї–µ—А - —В–∞–Љ —Б–Ї–Њ–ї—М–Ї–Њ –≤ –Њ–њ–µ—А–∞—В–Є–≤–Ї—Г –≤–ї–µ–Ј–µ—В!
–Э–µ —В–∞–Ї —Б—В—А–∞—И–µ–љ —А—Г—Б—Б–Ї–Є–є —В–∞–љ–Ї, –Ї–∞–Ї –µ–≥–Њ –њ—М—П–љ—Л–є —Н–Ї–Є–њ–∞–ґ
- kugeod
- –Э–∞—З–Є–љ–∞—О—Й–Є–є
- –°–Њ–Њ–±—Й–µ–љ–Є—П: 1
- –Ч–∞—А–µ–≥–Є—Б—В—А–Є—А–Њ–≤–∞–љ: 29.02.2016 (–Я–љ) 16:07
- –Ю—В–Ї—Г–і–∞: –Ґ–≤–µ—А—М
Re: –Ъ–∞–Ї –њ–Њ–±–µ–і–Є—В—М "Out of memory"?
![]() kugeod » 29.02.2016 (–Я–љ) 21:51
kugeod » 29.02.2016 (–Я–љ) 21:51
–Ч–і—А–∞–≤—Б—В–≤—Г–є—В–µ!
–Ь–µ–љ—П –њ–Њ–ї–љ–Њ—Б—В—М—О —Г—Б—В—А–∞–Є–≤–∞–µ—В —А–∞–±–Њ—В–∞ –Љ–∞—Б—Б–Є–≤–Њ–≤ –≤ –њ–∞–Љ—П—В–Є, —П –Є—Е —Д–Њ—А–Љ–Є—А—Г—О —Б—А–∞–Ј—Г –≤ –њ–∞–Љ—П—В—М, –Њ–±—А–∞–±–∞—В—Л–≤–∞—О –Є –њ–Њ–ї—Г—З–∞—О —А–µ–Ј—Г–ї—М—В–∞—В. –С–µ–Ј –њ—А–Њ–Љ–µ–ґ—Г—В–Ї–Њ–≤ –Є –≤—Л–≥—А—Г–Ј–Њ–Ї –Ї—Г–і–∞-–ї–Є–±–Њ. –Э–Њ –≤–Њ—В –њ–Њ—З–µ–Љ—Г Vb –љ–µ –Љ–Њ–ґ–µ—В –і–∞—В—М –Љ–љ–µ –і–∞–ґ–µ –Њ–±—К—П–≤–Є—В—М –Љ–∞—Б—Б–Є–≤, —А–∞–Ј–Љ–µ—А–љ–Њ—Б—В—М—О –Ї–Њ—В–Њ—А–∞—П –Љ–µ–љ—П –Є–љ—В–µ—А–µ—Б—Г–µ—В, –Љ–љ–µ –љ–µ –њ–Њ–љ—П—В–љ–Њ. –Ю–±—К—П—Б–љ–Є—В–µ, –µ—Б–ї–Є –љ–µ —В—П–ґ–µ–ї–Њ. –Ш –µ—Б—В—М –ї–Є —Б–њ–Њ—Б–Њ–± —А–∞–±–Њ—В–∞—В—М —Б —В–∞–Ї–Є–Љ–Є –Љ–∞—Б—Б–Є–≤–∞–Љ–Є, –љ–µ —Г—Е–Њ–і—П —Б –љ–Є–Љ–Є –≤ –С–Ф –Є —А–∞–Ј–љ—Л–µ —В–∞–Љ SQL'–ї–Є.
–Ї –њ—А–Є–Љ–µ—А—Г –Ї–Њ–і:
–≤—Л–і–∞—Б—В –Њ—И–Є–±–Ї—Г "Out of memory".
–Я–µ—А–µ–Љ–µ–љ–љ–∞—П —В–Є–њ–∞ byte, –Ј–∞–љ–Є–Љ–∞–µ—В –≤ –њ–∞–Љ—П—В–Є 1 –±–∞–є—В.
–Ф–∞–ґ–µ –µ—Б–ї–Є –њ–Њ–≤–µ—А–Є—В—М —З—В–Њ VB6 –љ–µ –≤—Л–і–µ–ї—П–µ—В –±–Њ–ї—М—И–µ 2–У–± –Њ–њ–µ—А–∞—В–Є–≤–Ї–Є (–≥–і–µ-—В–Њ –≤—Л—З–Є—В–∞–ї, —Б–Є–ї—М–љ–Њ –љ–µ –±–µ–є—В–µ, –µ—Б–ї–Є –љ–µ —В–∞–Ї), —В–Њ:
2–≥–± —Н—В–Њ 2147483648 –±–∞–є—В. –Ъ–≤–∞–і—А–∞—В–љ—Л–є –Ї–Њ—А–µ–љ—М –Є–Ј 2147483648 –Њ–Ї—А—Г–≥–ї–Є–Љ 46000. –Т—Л—Е–Њ–і–Є—В –і–≤—Г–Љ–µ—А–љ—Л–є –Љ–∞—Б—Б–Є–≤ –Љ–Њ–ґ–µ—В –±—Л—В—М –≤ —В–µ–Њ—А–Є–Є (—Е–Њ—В—П –±—Л) 46000 –љ–∞ 46000. –Э–Њ –Њ–љ –ґ–µ(–Ї–Њ–і), —Б–Ї–Њ–Љ–њ–Є–ї–Є—А–Њ–≤–∞–љ–љ—Л–є, —А–µ–∞–ї—М–љ–Њ –љ–µ –њ—А–µ–≤—Л—И–∞–µ—В –Ј–љ–∞—З–µ–љ–Є—П –Њ–Ї–Њ–ї–Њ 35000 –љ–∞ 35000. –Я–Њ—З–µ–Љ—Г?
–Р —Г–ґ –њ–Њ–Љ–µ—З—В–∞–≤, —П –±—Л —Е–Њ—В–µ–ї –≤—Б—О —Б–≤–Њ—О –Њ–њ–µ—А–∞—В–Є–≤–љ—Г—О –њ–∞–Љ—П—В—М 8 –≥–± –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –њ–Њ–ї–љ–Њ—Б—В—М—О –њ–Њ–і —Б–≤–Њ—О –њ—А–Њ–≥—А–∞–Љ–Љ—Г. –І—В–Њ–±—Л –Њ–±—А–∞–±–∞—В—Л–≤–∞—В—М –Љ–∞—В—А–Є—Ж—Л 80000 –љ–∞ 80000. –Т–Њ–Ј–Љ–Њ–ґ–љ–Њ –ї–Є —Н—В–Њ?
–Х—Б–ї–Є –Ї–Њ–Љ—Г —В–Њ –≤–Њ–њ—А–Њ—Б –њ–Њ–Ї–∞–ґ–µ—В—Б—П –њ—А–Њ—Б—В–Њ "–≤–Њ–і—Г –њ–Њ–Љ—Г—В–Є—В—М", —В–Њ –Ј–∞–≤–µ—А—П—О –Т–∞—Б, —Н—В–Њ –љ–µ —В–∞–Ї. –Ч–∞—А–∞–љ–µ–µ —Б–њ–∞—Б–Є–±–Њ.
–Ь–µ–љ—П –њ–Њ–ї–љ–Њ—Б—В—М—О —Г—Б—В—А–∞–Є–≤–∞–µ—В —А–∞–±–Њ—В–∞ –Љ–∞—Б—Б–Є–≤–Њ–≤ –≤ –њ–∞–Љ—П—В–Є, —П –Є—Е —Д–Њ—А–Љ–Є—А—Г—О —Б—А–∞–Ј—Г –≤ –њ–∞–Љ—П—В—М, –Њ–±—А–∞–±–∞—В—Л–≤–∞—О –Є –њ–Њ–ї—Г—З–∞—О —А–µ–Ј—Г–ї—М—В–∞—В. –С–µ–Ј –њ—А–Њ–Љ–µ–ґ—Г—В–Ї–Њ–≤ –Є –≤—Л–≥—А—Г–Ј–Њ–Ї –Ї—Г–і–∞-–ї–Є–±–Њ. –Э–Њ –≤–Њ—В –њ–Њ—З–µ–Љ—Г Vb –љ–µ –Љ–Њ–ґ–µ—В –і–∞—В—М –Љ–љ–µ –і–∞–ґ–µ –Њ–±—К—П–≤–Є—В—М –Љ–∞—Б—Б–Є–≤, —А–∞–Ј–Љ–µ—А–љ–Њ—Б—В—М—О –Ї–Њ—В–Њ—А–∞—П –Љ–µ–љ—П –Є–љ—В–µ—А–µ—Б—Г–µ—В, –Љ–љ–µ –љ–µ –њ–Њ–љ—П—В–љ–Њ. –Ю–±—К—П—Б–љ–Є—В–µ, –µ—Б–ї–Є –љ–µ —В—П–ґ–µ–ї–Њ. –Ш –µ—Б—В—М –ї–Є —Б–њ–Њ—Б–Њ–± —А–∞–±–Њ—В–∞—В—М —Б —В–∞–Ї–Є–Љ–Є –Љ–∞—Б—Б–Є–≤–∞–Љ–Є, –љ–µ —Г—Е–Њ–і—П —Б –љ–Є–Љ–Є –≤ –С–Ф –Є —А–∞–Ј–љ—Л–µ —В–∞–Љ SQL'–ї–Є.
–Ї –њ—А–Є–Љ–µ—А—Г –Ї–Њ–і:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
dim massive(40000,40000) as byte
–≤—Л–і–∞—Б—В –Њ—И–Є–±–Ї—Г "Out of memory".
–Я–µ—А–µ–Љ–µ–љ–љ–∞—П —В–Є–њ–∞ byte, –Ј–∞–љ–Є–Љ–∞–µ—В –≤ –њ–∞–Љ—П—В–Є 1 –±–∞–є—В.
–Ф–∞–ґ–µ –µ—Б–ї–Є –њ–Њ–≤–µ—А–Є—В—М —З—В–Њ VB6 –љ–µ –≤—Л–і–µ–ї—П–µ—В –±–Њ–ї—М—И–µ 2–У–± –Њ–њ–µ—А–∞—В–Є–≤–Ї–Є (–≥–і–µ-—В–Њ –≤—Л—З–Є—В–∞–ї, —Б–Є–ї—М–љ–Њ –љ–µ –±–µ–є—В–µ, –µ—Б–ї–Є –љ–µ —В–∞–Ї), —В–Њ:
2–≥–± —Н—В–Њ 2147483648 –±–∞–є—В. –Ъ–≤–∞–і—А–∞—В–љ—Л–є –Ї–Њ—А–µ–љ—М –Є–Ј 2147483648 –Њ–Ї—А—Г–≥–ї–Є–Љ 46000. –Т—Л—Е–Њ–і–Є—В –і–≤—Г–Љ–µ—А–љ—Л–є –Љ–∞—Б—Б–Є–≤ –Љ–Њ–ґ–µ—В –±—Л—В—М –≤ —В–µ–Њ—А–Є–Є (—Е–Њ—В—П –±—Л) 46000 –љ–∞ 46000. –Э–Њ –Њ–љ –ґ–µ(–Ї–Њ–і), —Б–Ї–Њ–Љ–њ–Є–ї–Є—А–Њ–≤–∞–љ–љ—Л–є, —А–µ–∞–ї—М–љ–Њ –љ–µ –њ—А–µ–≤—Л—И–∞–µ—В –Ј–љ–∞—З–µ–љ–Є—П –Њ–Ї–Њ–ї–Њ 35000 –љ–∞ 35000. –Я–Њ—З–µ–Љ—Г?
–Р —Г–ґ –њ–Њ–Љ–µ—З—В–∞–≤, —П –±—Л —Е–Њ—В–µ–ї –≤—Б—О —Б–≤–Њ—О –Њ–њ–µ—А–∞—В–Є–≤–љ—Г—О –њ–∞–Љ—П—В—М 8 –≥–± –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –њ–Њ–ї–љ–Њ—Б—В—М—О –њ–Њ–і —Б–≤–Њ—О –њ—А–Њ–≥—А–∞–Љ–Љ—Г. –І—В–Њ–±—Л –Њ–±—А–∞–±–∞—В—Л–≤–∞—В—М –Љ–∞—В—А–Є—Ж—Л 80000 –љ–∞ 80000. –Т–Њ–Ј–Љ–Њ–ґ–љ–Њ –ї–Є —Н—В–Њ?
–Х—Б–ї–Є –Ї–Њ–Љ—Г —В–Њ –≤–Њ–њ—А–Њ—Б –њ–Њ–Ї–∞–ґ–µ—В—Б—П –њ—А–Њ—Б—В–Њ "–≤–Њ–і—Г –њ–Њ–Љ—Г—В–Є—В—М", —В–Њ –Ј–∞–≤–µ—А—П—О –Т–∞—Б, —Н—В–Њ –љ–µ —В–∞–Ї. –Ч–∞—А–∞–љ–µ–µ —Б–њ–∞—Б–Є–±–Њ.
- –•–∞–Ї–µ—А
- –Ґ–µ–ї–µ–њ–∞—В
-

- –°–Њ–Њ–±—Й–µ–љ–Є—П: 16497
- –Ч–∞—А–µ–≥–Є—Б—В—А–Є—А–Њ–≤–∞–љ: 13.11.2005 (–Т—Б) 2:43
- –Ю—В–Ї—Г–і–∞: –Ъ–∞–Ј–∞—Е—Б—В–∞–љ, –Я–µ—В—А–Њ–њ–∞–≤–ї–Њ–≤—Б–Ї
Re: –Ъ–∞–Ї –њ–Њ–±–µ–і–Є—В—М "Out of memory"?
![]() –•–∞–Ї–µ—А » 01.03.2016 (–Т—В) 11:38
–•–∞–Ї–µ—А » 01.03.2016 (–Т—В) 11:38
kugeod –њ–Є—Б–∞–ї(–∞):(–≥–і–µ-—В–Њ –≤—Л—З–Є—В–∞–ї, —Б–Є–ї—М–љ–Њ –љ–µ –±–µ–є—В–µ, –µ—Б–ї–Є –љ–µ —В–∞–Ї)
–Э—Г–ґ–љ–Њ –љ–µ ¬Ђ–≥–і–µ-—В–Њ –≤—Л—З–Є—В—Л–≤–∞—В—М¬ї, –∞ –њ–Њ–љ–Є–Љ–∞—В—М.
–Ґ–∞–Ї –≤–Њ—В, –њ—А–Њ–≤–Њ–ґ—Г –ї–Є–Ї–±–µ–Ј.
–Т 32-–±–Є—В–љ—Л—Е Windows –Ї–∞–ґ–і—Л–є –Ј–∞–њ—Г—Й–µ–љ–љ—Л–є EXE –њ–Њ—А–Њ–ґ–і–∞–µ—В —Б–≤–Њ–є —Б–Њ–±—Б—В–≤–µ–љ–љ—Л–є –њ—А–Њ—Ж–µ—Б—Б. –Я—А–Є —Н—В–Њ–Љ –Ї–∞–ґ–і—Л–є –њ—А–Њ—Ж–µ—Б—Б –њ–Њ–ї—Г—З–∞–µ—В —Б–Њ–±—Б—В–≤–µ–љ–љ–Њ–µ –Є–Ј–Њ–ї–Є—А–Њ–≤–∞–љ–љ–Њ–µ –Њ—В –і—А—Г–≥–Є—Е –њ—А–Њ—Ж–µ—Б—Б–Њ–≤ –Є –љ–µ–Ј–∞–≤–Є—Б–Є–Љ–Њ–µ –Њ—В –љ–Є—Е –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–Њ –∞–і—А–µ—Б–Њ–≤ –њ–∞–Љ—П—В–Є. –≠—В–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–Њ –љ–∞–Ј—Л–≤–∞–µ—В—Б—П –∞–і—А–µ—Б–љ—Л–Љ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–Њ–Љ (–Р–Я).
–Х—Б–ї–Є –Ї–∞–Ї–Њ–є-—В–Њ –њ—А–Њ—Ж–µ—Б—Б –љ–∞—З–љ—С—В —Б–Ї–∞–љ–Є—А–Њ–≤–∞—В—М –њ–∞–Љ—П—В—М –љ–∞—З–Є–љ–∞—П —Б –љ—Г–ї–µ–≤–Њ–≥–Њ –∞–і—А–µ—Б–∞ –Є –і–Њ —Б–∞–Љ–Њ–≥–Њ –њ—А–µ–і–µ–ї–∞, –Њ–љ –љ–µ –љ–∞–є–і—С—В —В–∞–Љ –і–∞–љ–љ—Л—Е, –њ—А–Є–љ–∞–і–ї–µ–ґ–∞—Й–Є—Е –і—А—Г–≥–Є–Љ –њ—А–Њ—Ж–µ—Б—Б–∞–Љ (–Є–Ј —Н—В–Њ–≥–Њ –њ—А–∞–≤–Є–ї–∞ –µ—Б—В—М –Є—Б–Ї–ї—О—З–µ–љ–Є—П, –љ–Њ —Б–µ–є—З–∞—Б –Њ–љ–Є –љ–µ –≤–∞–ґ–љ—Л). –Ґ–Њ—В–∞–ї—М–љ–∞—П –Є–Ј–Њ–ї—П—Ж–Є—П. –Я—А–Є–Љ–µ—А–љ–Њ –Ї–∞–Ї –≤ —Б–ї—Г—З–∞–µ —Б —Д–∞–є–ї–∞–Љ–Є: –µ—Б–ї–Є –µ—Б—В—М –і–≤–∞ —Д–∞–є–ї–∞ –љ–∞ –і–Є—Б–Ї–µ, —В–Њ –Њ–љ–Є —Е—А–∞–љ—П—В —А–∞–Ј–љ—Л–µ –і–∞–љ–љ—Л–µ, –Ї–Њ—В–Њ—А—Л–µ –љ–µ –њ–µ—А–µ—Б–µ–Ї–∞—О—В—Б—П –Љ–µ–ґ–і—Г —Б–Њ–±–Њ–є. –Ш–ї–Є –Ї–∞–Ї –≤ —Б–ї—Г—З–∞–µ —Б –Ї–Њ–Љ–њ—М—О—В–µ—А–љ–Њ–є –Є–≥—А–Њ–є: –µ—Б–ї–Є –і–≤–∞ —З–µ–ї–Њ–≤–µ–Ї–∞ –±—Г–і—Г—В –Є–≥—А–∞—В—М –≤ –Њ–і–љ—Г –Є —В—Г –ґ–µ –Ї–Њ–Љ–њ—М—О—В–µ—А–љ—Г—О –Є–≥—А—Г, –љ–µ –≤ –Љ—Г–ї—М—В–Є–њ–ї–µ–µ—А (–њ–Њ —Б–µ—В–Є), –∞ –њ—А–Њ—Б—В–Њ —В–∞–Ї, —В–Њ –і–∞–ґ–µ –µ—Б–ї–Є –Њ–љ–Є –±—Г–і—Г—В —Е–Њ–і–Є—В—М –њ–Њ –Њ–і–љ–Њ–є –Є —В–Њ–є –ґ–µ –Ї–∞—А—В–µ, –і—А—Г–≥ –і—А—Г–≥–∞ –Њ–љ–Є –љ–µ –≤—Б—В—А–µ—В—П—В, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –Ї–∞–ґ–і—Л–є —Б—Г—Й–µ—Б—В–≤—Г–µ—В –≤ —Б–Њ–±—Б—В–≤–µ–љ–љ–Њ–Љ (–Є–Ј–Њ–ї–Є—А–Њ–≤–∞–љ–љ–Њ–Љ –Њ—В –і—А—Г–≥–Њ–≥–Њ) –≤–Є—А—В—Г–∞–ї—М–љ–Њ–Љ –Љ–Є—А–µ. –Ґ–∞–Ї —З—В–Њ —В–Њ—В–∞–ї—М–љ–∞—П –Є–Ј–Њ–ї—П—Ж–Є—П.
–°–∞–Љ–∞ –њ–Њ —Б–µ–±–µ —В–µ—Е–љ–Њ–ї–Њ–≥–Є—П, –њ–Њ–Ј–≤–Њ–ї—П—О—Й–∞—П —Б–і–µ–ї–∞—В—М —В–∞–Ї, —З—В–Њ –Ї–∞–ґ–і—Л–є –њ—А–Њ—Ж–µ—Б—Б (–њ—А–Њ–≥—А–∞–Љ–Љ–∞) –≤–Є–і–Є—В —Б–≤–Њ—С —Б–Њ–±—Б—В–≤–µ–љ–љ–Њ–µ –∞–і—А–µ—Б–љ–Њ–µ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–Њ, –љ–∞–Ј—Л–≤–∞–µ—В—Б—П –≤–Є—А—В—Г–∞–ї—М–љ–∞—П –њ–∞–Љ—П—В—М, –Є —Н—В–Њ –≤–Њ –Љ–љ–Њ–≥–Њ–Љ –∞–њ–њ–∞—А–∞—В–љ–∞—П —В–µ—Е–љ–Њ–ї–Њ–≥–Є—П (–њ—А–µ–і–Њ—Б—В–∞–≤–ї—П–µ–Љ–∞—П –∞—А—Е–Є—В–µ–Ї—В—Г—А–Њ–є –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞ Intel IA-32), –Ї–Њ—В–Њ—А–Њ–є –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ–∞—П —Б–Є—Б—В–µ–Љ–∞ —Г–Љ–µ–ї–Њ –њ–Њ–ї—М–Ј—Г–µ—В—Б—П.
–Я–Њ–Љ–Є–Љ–Њ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є —Б–і–µ–ї–∞—В—М —В–∞–Ї, —З—В–Њ–±—Л –Ї–∞–ґ–і—Л–є –њ—А–Њ—Ж–µ—Б—Б –Є–Љ–µ–ї —Б–≤–Њ—С —Б–Њ–±—Б—В–≤–µ–љ–љ–Њ–µ –Р–Я, –∞—А—Е–Є—В–µ–Ї—В—Г—А–∞ –њ–Њ–Ј–≤–Њ–ї—П–µ—В —Б–і–µ–ї–∞—В—М –µ—Й—С —В—А–Є –≤–∞–ґ–љ—Л–µ –≤–µ—Й–Є:
- –°—В—А–∞–љ–Є—З–љ–∞—П –Њ—А–≥–∞–љ–Є–Ј–∞—Ж–Є—П
- –Я–Њ–і–Ї–∞—З–Ї–∞
- –Ч–∞—Й–Є—В–∞
–°–µ–є—З–∞—Б –і–Њ –≤—Б–µ–≥–Њ –і–Њ–є–і—С–Љ.
–Ъ–∞–ґ–і—Л–є –њ—А–Њ—Ж–µ—Б—Б –њ–Њ–ї—Г—З–∞–µ—В —Б–≤–Њ—С —Б–Њ–±—Б—В–≤–µ–љ–љ–Њ–µ –∞–і—А–µ—Б–љ–Њ–µ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–Њ –Є –Љ–Њ–ґ–µ—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М 32-–±–Є—В–љ—Л–µ –∞–і—А–µ—Б–∞ –і–ї—П –∞–і—А–µ—Б–∞—Ж–Є–Є –Ї–Њ–љ–Ї—А–µ—В–љ—Л—Е —П—З–µ–µ–Ї —Н—В–Њ–≥–Њ –∞–і—А–µ—Б–љ–Њ–≥–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–∞. –І—В–Њ –і–∞—С—В 2^32 = 4GB вАФ¬†—А–∞–Ј–Љ–µ—А –∞–і—А–µ—Б–љ–Њ–≥–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–∞ –Ї–∞–ґ–і–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ —Б –њ—А–Є–Љ–µ–љ–µ–љ–Є–µ–Љ 32-–±–Є—В–љ—Л—Е –∞–і—А–µ—Б–Њ–≤. –Т–Њ–Њ–±—Й–µ-—В–Њ, –µ—Б–ї–Є –±—Л—В—М —З–µ—Б—В–љ—Л–Љ, –∞—А—Е–Є—В–µ–Ї—В—Г—А–∞ –њ–Њ–Ј–≤–Њ–ї—П–µ—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М 48-–±–Є—В–љ—Л–µ –∞–і—А–µ—Б–∞, —Б–Њ—Б—В–Њ—П—Й–Є–µ –Є–Ј –і–≤—Г—Е —З–∞—Б—В–µ–є: 16-–±–Є—В–љ–Њ–≥–Њ —Б–µ–ї–µ–Ї—В–Њ—А–∞ —Б–µ–≥–Љ–µ–љ—В–∞ –Є 32-–±–Є—В–љ–Њ–≥–Њ –±–ї–Є–ґ–љ–µ–≥–Њ (near) –∞–і—А–µ—Б–∞. –Ґ–∞–Ї–Њ–є 48-–±–Є—В–љ—Л–є –∞–і—А–µ—Б –љ–∞–Ј—Л–≤–∞–µ—В—Б—П –љ–∞–Ј—Л–≤–∞–µ—В—Б—П –і–∞–ї—М–љ–Є–Љ (far). –Э–Њ –±–Њ–ї—М—И–Є–љ—Б—В–≤–Њ –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ—Л—Е —Б–Є—Б—В–µ–Љ –љ–µ –њ–Њ–ї—М–Ј—Г–µ—В—Б—П —Н—В–Њ–є –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М—О, 16-–±–Є—В–љ—Л–µ —Б–µ–ї–µ–Ї—В–Њ—А—Л –Ј–∞–≥—А—Г–ґ–∞—О—В—Б—П –≤ —Б–µ–≥–Љ–µ–љ—В–љ—Л–µ —А–µ–≥–Є—Б—В—А—Л –µ–і–Є–љ–Њ–ґ–і—Л –Є –і–∞–ї—М—И–µ –Є—Е –љ–Є–Ї—В–Њ –љ–µ —В—А–Њ–≥–∞–µ—В, –∞ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П —В–Њ–ї—М–Ї–Њ –±–ї–Є–ґ–љ—П—П –∞–і—А–µ—Б–∞—Ж–Є—П, —В–Њ –µ—Б—В—М 32-–±–Є—В–љ–∞—П –∞–і—А–µ—Б–∞—Ж–Є—П.
–Ґ–∞–Ї –≤–Њ—В, –Ї–∞–ґ–і—Л–є –њ—А–Њ—Ж–µ—Б—Б (–≤ 32-–±–Є—В–љ–Њ–є Windows, —А–∞–±–Њ—В–∞—О—Й–µ–є –љ–∞ 32-–±–Є—В–љ–Њ–Љ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–µ –Є–ї–Є –љ–∞ 64-–±–Є—В–љ–Њ–Љ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–µ, —А–∞–±–Њ—В–∞—О—Й–µ–Љ –≤ 32-–±–Є—В–љ–Њ–Љ —А–µ–ґ–Є–Љ–µ) –Љ–Њ–ґ–µ—В –≤–Є–і–µ—В—М –∞–і—А–µ—Б–љ–Њ–µ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–Њ —А–∞–Ј–Љ–µ—А–Њ–Љ 4 –У–± –Є –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М 32-–±–Є—В–љ—Л–µ –∞–і—А–µ—Б–∞.
–Э–Њ –љ–µ –љ—Г–ґ–љ–Њ –і—Г–Љ–∞—В—М, —З—В–Њ —А–∞–Ј —Г –њ—А–Њ—Ж–µ—Б—Б–∞ –µ—Б—В—М –Р–Я —А–∞–Ј–Љ–µ—А–Њ–Љ 4 –У–±, —В–Њ —Б—Е–Њ–і—Г –Љ–Њ–ґ–љ–Њ –њ–Њ–ї—М–Ј–Њ–≤–∞—В—М—Б—П –ї—О–±—Л–Љ –Љ–µ—Б—В–Њ–Љ –≤ —Н—В–Њ–Љ –Р–Я, –њ–Є—Б–∞—В—М –Є —З–Є—В–∞—В—М –њ–Њ –ї—О–±–Њ–Љ—Г –∞–і—А–µ—Б—Г. –Т–Є—А—В—Г–∞–ї—М–љ–Њ–µ –Р–Я вАФ —Н—В–Њ –∞–±—Б—В—А–∞–Ї—Ж–Є—П, —Д–Є–Ї—Ж–Є—П –Є –Ї—А–∞—Б–Є–≤–∞—П –Є–ї–ї—О–Ј–Є—П, —Б–Њ–Ј–і–∞–≤–∞–µ–Љ–∞—П –і–ї—П —В–Њ–≥–Њ, —З—В–Њ–±—Л —Б–і–µ–ї–∞—В—М –њ—А–Њ–≥—А–∞–Љ–Љ–Є—А–Њ–≤–∞–љ–Є–µ –±–Њ–ї–µ–µ –ї—С–≥–Ї–Є–Љ, —Г–і–Њ–±–љ—Л–Љ, –∞ —Б–Є—Б—В–µ–Љ—Г вАФ –±–Њ–ї–µ–µ –љ–∞–і—С–ґ–љ–Њ–є.
–Ф–∞–љ–љ—Л–µ, –Ї–Њ—В–Њ—А—Л–µ –њ—А–Њ–≥—А–∞–Љ–Љ–∞ —Г–≤–Є–і–Є—В –≤ —Б–≤–Њ–µ–є –њ–∞–Љ—П—В–Є, –љ—Г–ґ–љ–Њ –≥–і–µ-—В–Њ —Е—А–∞–љ–Є—В—М. –Ш —Н—В–Є–Љ ¬Ђ–≥–і–µ-—В–Њ¬ї –≤ –њ–µ—А–≤—Г—О –Њ—З–µ—А–µ–і—М –≤—Л—Б—В—Г–њ–∞–µ—В —Д–Є–Ј–Є—З–µ—Б–Ї–∞—П –њ–∞–Љ—П—В—М.
–Ґ–µ–њ–µ—А—М –њ–Њ–≥–Њ–≤–Њ—А–Є–Љ –Њ —Б—В—А–∞–љ–Є—З–љ–Њ–є –Њ—А–≥–∞–љ–Є–Ј–∞—Ж–Є–Є –Є –њ–Њ–і–Ї–∞—З–Ї–µ.
–Т—Б—П —Д–Є–Ј–Є—З–µ—Б–Ї–∞—П –њ–∞–Љ—П—В—М (—В–Њ –µ—Б—В—М –њ–∞–Љ—П—В—М, –≤ —В–Њ–Љ –µ—С –Њ–±—К—С–Љ–µ, –Ї–Њ—В–Њ—А–∞—П –Њ–±–µ—Б–њ–µ—З–Є–≤–∞–µ—В—Б—П –≤—Б—В–∞–≤–ї–µ–љ–љ—Л–Љ–Є –≤ –Љ–∞—В–µ—А–Є–љ—Б–Ї—Г—О –њ–ї–∞—В—Г –њ–ї–∞–љ–Ї–∞–Љ–Є –њ–∞–Љ—П—В–Є) —Г—Б–ї–Њ–≤–љ–Њ –і–µ–ї–Є—В—Б—П –љ–∞ —Б—В—А–∞–љ–Є—Ж—Л вАФ –±–ї–Њ–Ї–Є —А–∞–Ј–Љ–µ—А–Њ–Љ 4 –Ї–±. –Т–Є—А—В—Г–∞–ї—М–љ–Њ–µ –Р–Я –Ї–∞–ґ–і–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ —В–Њ–ґ–µ —Г—Б–ї–Њ–≤–љ–Њ –і—А–Њ–±–Є—В—Б—П –љ–∞ –±–ї–Њ–Ї–Є —А–∞–Ј–Љ–µ—А–Њ–Љ 4 –Ї–±. –Р—А—Е–Є—В–µ–Ї—В—Г—А–∞ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞ –њ–Њ–Ј–≤–Њ–ї—П–µ—В –њ–Њ–Ј–≤–Њ–ї—П–µ—В –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ–Њ–є —Б–Є—Б—В–µ–Љ–µ –њ–Њ—Б—В—А–Њ–Є—В—М –љ–µ–Ї—Г—О, —Г–њ—А–Њ—Й—С–љ–љ–Њ –≥–Њ–≤–Њ—А—П, –Ї–∞—А—В—Г —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Є—П. –≠—В–∞ –Ї–∞—А—В–∞ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Є—П –Њ–њ—А–µ–і–µ–ї—П–µ—В, –Ї–∞–Ї–∞—П —Б—В—А–∞–љ–Є—Ж–∞ –≤–Є—А—В—Г–∞–ї—М–љ–Њ–≥–Њ –Р–Я –Ї–∞–Ї–Њ–≥–Њ-—В–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ –Ї–∞–Ї–Њ–є —Б—В—А–∞–љ–Є—Ж–µ —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В.
–Ґ–∞–Ї —З—В–Њ, –µ—Б–ї–Є –±—Л –≤—Б—С –±—Л–ї–Њ —В–∞–Ї –њ—А–Њ—Б—В–Њ, —В–Њ –і–∞–ґ–µ –љ–µ—Б–Љ–Њ—В—А—П –љ–∞ —В–Њ—В —Д–∞–Ї—В, —З—В–Њ –Ї–∞–ґ–і—Л–є –њ—А–Њ—Ж–µ—Б—Б –≤–Є–і–Є—В —Б–Њ–±—Б—В–≤–µ–љ–љ–Њ–µ –Р–Я —А–∞–Ј–Љ–µ—А–Њ–Љ 4 –У–±, –Њ–±—Й–µ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Б—В—А–∞–љ–Є—Ж, –Ј–∞–љ—П—В—Л—Е –Ї–∞–Ї–Є–Љ–Є-—В–Њ –і–∞–љ–љ—Л–Љ–Є, –і–ї—П –≤—Б–µ—Е –њ—А–Њ—Ж–µ—Б—Б–Њ–≤ –≤ —Б—Г–Љ–Љ–µ –±—Л–ї –±—Л –Њ–≥—А–∞–љ–Є—З–µ–љ–Њ —А–∞–Ј–Љ–µ—А–Њ–Љ —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є. –Р —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є –≤ –Ї–Њ–Љ–њ—М—О—В–µ—А–µ –Љ–Њ–ґ–µ—В –±—Л—В—М —Г—Б—В–∞–љ–Њ–≤–ї–µ–љ–Њ, –љ–∞–њ—А–Є–Љ–µ—А, 256 –Ь–±. –Ш —Н—В–Њ –Ј–љ–∞—З–Є–ї–Њ –±—Л, —З—В–Њ –Њ–≥—А–∞–љ–Є—З–µ–љ–Є–µ –њ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—О –њ–∞–Љ—П—В–Є –і–ї—П –≤—Б–µ—Е –њ—А–Њ—Ж–µ—Б—Б–Њ–≤ –≤–Љ–µ—Б—В–µ –≤–Ј—П—В—Л—Е вАФ 256 –Ь–±. –Э–Њ –≤—Б—С –љ–µ —В–∞–Ї –њ—А–Њ—Б—В–Њ.
–Э–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ –≤ —Н—В–Њ–є –Ї–∞—А—В–µ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Є—П –і–ї—П –Ї–∞–ґ–і–Њ–є —Б—В—А–∞–љ–Є—Ж—Л –≤–Є—А—В—Г–∞–ї—М–љ–Њ–≥–Њ –Р–Я –µ—Б—В—М —Д–ї–∞–≥, –≥–Њ–≤–Њ—А—П—Й–Є–є, –∞ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –ї–Є –≤–Њ–Њ–±—Й–µ –і–∞–љ–љ–∞—П —Б—В—А–∞–љ–Є—Ж–∞ –≤–Є—А—В—Г–∞–ї—М–љ–Њ–≥–Њ –Р–Я –Ї–∞–Ї–Њ–є-—В–Њ —Б—В—А–∞–љ–Є—Ж–µ —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є. –Ш –Њ–љ–∞ –Љ–Њ–ґ–µ—В –љ–µ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Њ–≤–∞—В—М –≤–Њ–Њ–±—Й–µ –љ–Є–Ї–∞–Ї–Њ–є.
–Т –љ–Њ—А–Љ–µ, –Ї–∞—А—В–∞ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Є—П, –Њ –Ї–Њ—В–Њ—А–Њ–є —П –≥–Њ–≤–Њ—А—О, —Б—В—А–Њ–Є—В—Б—П (—Б–Њ–Ј–і–∞—С—В—Б—П) —Б–Є–ї–∞–Љ–Є –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ–Њ–є —Б–Є—Б—В–µ–Љ–Њ–є, –љ–Њ –њ–Њ–ї—М–Ј—Г–µ—В—Б—П –µ–є –њ—А–Њ—Ж–µ—Б—Б–Њ—А –љ–∞ –∞–њ–њ–∞—А–∞—В–љ–Њ–Љ —Г—А–Њ–≤–љ–µ. –≠—В–Њ –Ј–љ–∞—З–Є—В, —З—В–Њ –Ї–Њ–≥–і–∞ –Ї–Њ–і –Ї–∞–Ї–Њ–є-—В–Њ –њ—А–Њ–≥—А–∞–Љ–Љ—Л –Њ–±—А–∞—Й–∞–µ—В—Б—П –Ї –Ї–∞–Ї–Њ–є-—В–Њ —Б—В—А–∞–љ–Є—Ж–µ –≤–Є—А—В—Г–∞–ї—М–љ–Њ–≥–Њ –Р–Я, —В–Њ –њ—А–Њ—Ж–µ—Б—Б–Њ—А —Б–∞–Љ —Б–Љ–Њ—В—А–Є—В –≤ –Ї–∞—А—В—Г —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Є—П –Є –њ—А–µ–Њ–±—А–∞–Ј—Г–µ—В –≤–Є—А—В—Г–∞–ї—М–љ—Л–є –∞–і—А–µ—Б –≤ —Д–Є–Ј–Є—З–µ—Б–Ї–Є–є –∞–і—А–µ—Б –Є –Њ–±—А–∞—Й–µ–љ–Є–µ –Є–і—С—В –њ—А—П–Љ–Њ –Ї —Б—В—А–∞–љ–Є—Ж–µ —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є. –Ю–њ–µ—А–∞—Ж–Є–Њ–љ–љ–∞—П —Б–Є—Б—В–µ–Љ–∞ –њ—А–Є –Ї–∞–ґ–і–Њ–Љ –Њ–±—А–∞—Й–µ–љ–Є–Є –Ї –њ–∞–Љ—П—В–Є –њ—А–Њ—Ж–µ—Б—Б–∞ –љ–µ –Ј–∞–і–µ–є—Б—В–≤—Г–µ—В—Б—П. –Э–Є–Ї–∞–Ї–Њ–є –Ї–Њ–і –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ–Њ–є —Б–Є—Б—В–µ–Љ—Л –њ—А–Є –Ї–∞–ґ–і–Њ–Љ –Њ–±—А–∞—Й–µ–љ–Є–Є –љ–µ –≤—Л–њ–Њ–ї–љ—П–µ—В—Б—П. –Ч–∞ –њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є–µ –∞–і—А–µ—Б–Њ–≤ –Њ—В–≤–µ—З–∞—О—В —Н–ї–µ–Ї—В—А–Њ–љ–љ—Л–µ —Б—Е–µ–Љ—Л —Б–∞–Љ–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞. –Ґ–Њ –µ—Б—В—М –њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є–µ —З–Є—Б—В–Њ –∞–њ–њ–∞—А–∞—В–љ–Њ–µ, –љ–µ –њ—А–Њ–≥—А–∞–Љ–Љ–љ–Њ–µ. –Ч–∞ —Б—З—С—В —Н—В–Њ–≥–Њ –Њ–±–µ—Б–њ–µ—З–Є–≤–∞–µ—В—Б—П –±—Л—Б—В—А–Њ—В–∞ —А–∞–±–Њ—В—Л. –Э–Њ —Н—В–Њ —В–∞–Ї –і–Њ —В–µ—Е –њ–Њ—А, –њ–Њ–Ї–∞ –≤ –Ї–∞—А—В–µ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Є—П —Б—В–Њ–Є—В —Д–ї–∞–≥, —З—В–Њ, –Љ–Њ–ї, —Н—В–Њ–є —Б—В—А–∞–љ–Є—Ж–µ –≤–Є—А—В—Г–∞–ї—М–љ–Њ–≥–Њ –Р–Я —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В —В–∞–Ї–∞—П-—В–Њ —Б—В—А–∞–љ–Є—Ж–∞ —Д–Є–Ј. –њ–∞–Љ—П—В–Є.
–Х—Б–ї–Є –ґ–µ —Д–ї–∞–≥ –љ–µ —Г—Б—В–∞–љ–Њ–≤–ї–µ–љ, –Є –і–∞–љ–љ–Њ–є —Б—В—А–∞–љ–Є—Ж–µ –≤–Є—А—В. –Р–Я (–Ї –Ї–Њ—В–Њ—А–Њ–є —В–Њ–ї—М–Ї–Њ —З—В–Њ –њ—А–Њ–Є–Ј–Њ—И–ї–Њ –Њ–±—А–∞—Й–µ–љ–Є–µ) –љ–µ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –≤–Њ–Њ–±—Й–µ –љ–Є–Ї–∞–Ї–Њ–є —Б—В—А–∞–љ–Є—Ж—Л —Д–Є–Ј–њ–∞–Љ—П—В–Є, —В–Њ –њ—А–Њ—Ж–µ—Б—Б–Њ—А –і—С—А–≥–∞–µ—В –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ—Г—О —Б–Є—Б—В–µ–Љ—Г. –Ю–љ –≤—Л–Ј—Л–≤–∞–µ—В –Њ–±—А–∞–±–Њ—В—З–Є–Ї, –њ—А–µ–і–Њ—Б—В–∞–≤–ї–µ–љ–љ—Л–є –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ–Њ–є —Б–Є—Б—В–µ–Љ–Њ–є, —З—В–Њ–±—Л –Њ–љ–∞ (–Ю–°), –Ї–∞–Ї-—В–Њ —А–∞–Ј—А—Г–ї–Є–ї–∞ —Б–Є—В—Г–∞—Ж–Є—О.
–†–∞–Ј—А—Г–ї–Є–≤–∞–љ–Є–µ —Б–Є—В—Г–∞—Ж–Є–Є –Ј–∞–Ї–ї—О—З–∞–µ—В—Б—П –≤ —Б–ї–µ–і—Г—О—Й–µ–Љ:
–Ю–° –њ–Њ–ї—М–Ј—Г–µ—В—Б—П –Є–і–µ–µ–є –Њ —В–Њ–Љ, —З—В–Њ –≤ —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є —Е—А–∞–љ–Є—В—Б—П —В–Њ–ї—М–Ї–Њ —З–∞—Б—В—М –і–∞–љ–љ—Л—Е. –Ю—Б—В–∞–ї—М–љ–∞—П —З–∞—Б—В—М —Е—А–∞–љ–Є—В—Б—П –љ–∞ –ґ–µ—Б—В–Ї–Њ–Љ –і–Є—Б–Ї–µ. –Ш —З—В–Њ –µ—Б–ї–Є —Г –Ї–∞–Ї–Њ–≥–Њ-—В–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ –≤ –≤–Є—А—В—Г–∞–ї—М–љ–Њ–Љ –Р–Я –µ—Б—В—М —Б—В—А–∞–љ–Є—Ж–∞, –і–∞–љ–љ—Л–µ –Ї–Њ—В–Њ—А–Њ–є –љ–µ —Е—А–∞–љ—П—В—Б—П –≤ —Д–Є–Ј–њ–∞–Љ—П—В–Є, —В–Њ –Ј–љ–∞—З–Є—В —Н—В–Є –і–∞–љ–љ—Л–µ —Е—А–∞–љ—П—В—Б—П –љ–∞ –і–Є—Б–Ї–µ. –Ґ–∞–Ї —З—В–Њ –Ї–Њ–≥–і–∞ –њ—А–Њ—Ж–µ—Б—Б–Њ—А –љ–∞—В—Л–Ї–∞–µ—В—Б—П –љ–∞ —В–∞–Ї—Г—О —Б—В—А–∞–љ–Є—Ж—Л –Є –≤—Л–Ј—Л–≤–∞–µ—В –Њ–±—А–∞–±–Њ—В—З–Є–Ї —Б–Њ —Б—В–Њ—А–Њ–љ—Л –Ю–°, —В–Њ –Ю–° –Є—Й–µ—В –≤ —Д–Є–Ј–њ–∞–Љ—П—В–Є —Б—В—А–∞–љ–Є—Ж—Г, –і–Њ—Б—В—Г–њ –Ї –Ї–Њ—В–Њ—А–Њ–є –њ—А–Њ–Є—Б—Е–Њ–і–Є–ї –љ–∞–Є–±–Њ–ї–µ–µ —А–µ–і–Ї–Њ. –≠—В–∞ —Б–∞–Љ–∞—П —А–µ–і–Ї–Њ–Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ–∞—П —Б—В—А–∞–љ–Є—Ж—Л –≤—Л–Ї–Є–і—Л–≤–∞–µ—В—Б—П –Є–Ј —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є (–Є —Б–Њ—Е—А–∞–љ—П–µ—В—Б—П –њ–µ—А–µ–і —Н—В–Є–Љ –љ–∞ –і–Є—Б–Ї, –µ—Б–ї–Є –Њ–љ–∞ –±—Л–ї–∞ –Є–Ј–Љ–µ–љ–µ–љ–∞ —Б —В–µ—Е –њ–Њ—А, –Ї–∞–Ї –њ–Њ–њ–∞–ї–∞ –≤ —Д–Є–Ј–њ–∞–Љ—П—В—М —Б –і–Є—Б–Ї–∞), –∞ –љ–∞ –µ—С –Љ–µ—Б—В–Њ –≤ —Д–Є–Ј–њ–∞–Љ—П—В—М –Ј–∞–≥—А—Г–ґ–∞–µ—В—Б—П —В–∞ —Б—В—А–∞–љ–Є—Ж–∞ —Б –і–Є—Б–Ї–∞, –Ї –Ї–Њ—В–Њ—А–Њ–є —В–Њ–ї—М–Ї–Њ —З—В–Њ –њ—А–Њ–Є–Ј–Њ—И–ї–Њ –Њ–±—А–∞—Й–µ–љ–Є–µ. –Ґ–Њ–є —Б—В—А–∞–љ–Є—Ж–µ, –Ї–Њ—В–Њ—А–∞—П –±—Л–ї–∞ –Ј–∞–≥—А—Г–ґ–µ–љ–∞, —Д–ї–∞–≥ –њ—А–Є—Б—Г—В—Б—В–≤–Є—П —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞–µ—В—Б—П. –Р —Г —В–Њ–є, –Ї–Њ—В–Њ—А–∞—П –±—Л–ї–∞ –≤—Л–Ї–Є–љ—Г—В–∞, —Д–ї–∞–≥ —Б–±—А–∞—Б—Л–≤–∞–µ—В—Б—П.
–≠—В–Њ—В –Љ–µ—Е–∞–љ–Є–Ј–Љ, —Б—Г—В—М –Ї–Њ—В–Њ—А–Њ–≥–Њ –≤ —В–Њ–Љ, —З—В–Њ –≤ —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є —Е—А–∞–љ–Є—В—Б—П —В–Њ–ї—М–Ї–Њ —З–∞—Б—В—М —Б—В—А–∞–љ–Є—Ж (—В–µ —Б—В—А–∞–љ–Є—Ж—Л, —Б –Ї–Њ—В–Њ—А—Л–Љ–Є –Є–і—С—В –љ–∞–Є–±–Њ–ї–µ–µ –∞–Ї—В–Є–≤–љ–∞—П —А–∞–±–Њ—В–∞), –∞ –Њ—Б—В–∞–≤—И–∞—П—Б—П —З–∞—Б—В—М —Е—А–∞–љ–Є—В—Б—П –љ–∞ –ґ–µ—Б—В–Ї–Њ–Љ –і–Є—Б–Ї–µ, –Є —З—В–Њ –њ–Њ—Б—В–Њ—П–љ–љ–Њ –Њ–і–љ–Є —Б—В—А–∞–љ–Є—Ж—Л –≤—Л–≥—А—Г–ґ–∞—О—В—Б—П –Є–Ј —Д–Є–Ј.–њ–∞–Љ—П—В–Є –љ–∞ –і–Є—Б–Ї, –∞ –≤–Ј–∞–Љ–µ–љ –њ–Њ–і–≥—А—Г–ґ–∞—О—В—Б—П –і—А—Г–≥–Є–µ вАФ –љ–∞–Ј—Л–≤–∞–µ—В—Б—П –њ–Њ–і–Ї–∞—З–Ї–∞.
–†–∞–љ—М—И–µ —П –љ–∞–њ–Є—Б–∞–ї, —З—В–Њ —Е–Њ—В—М —Г –Ї–∞–ґ–і–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ –Є –µ—Б—В—М 4 –У–±–∞–є—В–љ–Њ–µ –Р–Я, –љ–Њ –≤—Б—С —А–∞–≤–љ–Њ —Б—Г–Љ–Љ–∞—А–љ–Њ–µ –њ–Њ—В—А–µ–±–ї–µ–љ–Є–µ –њ–∞–Љ—П—В–Є –≤—Б–µ–Љ–Є –њ—А–Њ—Ж–µ—Б—Б–∞–Љ –Њ–≥—А–∞–љ–Є—З–µ–љ–Њ —А–∞–Ј–Љ–µ—А–∞–Љ–Є —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є. –Ґ–µ–њ–µ—А—М —Н—В–Њ –љ–µ —В–∞–Ї вАФ –њ–Њ—Б–Ї–Њ–ї—М–Ї—Г —З–∞—Б—В—М –і–∞–љ–љ—Л—Е —Е—А–∞–љ–Є—В—Б—П –љ–∞ –і–Є—Б–Ї–µ, –∞ –љ–µ –≤ —Д–Є–Ј. –њ–∞–Љ—П—В–Є, —В–Њ —Б—Г–Љ–Љ–∞—А–љ–Њ–µ –њ–Њ—В—А–µ–±–ї–µ–љ–Є–µ –њ–∞–Љ—П—В–Є –≤—Б–µ–Љ–Є –њ—А–Њ—Ж–µ—Б—Б–∞–Љ–Є —Г–ґ–µ –љ–µ –Њ–≥—А–∞–љ–Є—З–µ–љ–Њ —А–∞–Ј–Љ–µ—А–∞–Љ–Є —Д–Є–Ј. –њ–∞–Љ—П—В–Є (–љ–Њ —А–∞–Ј–Љ–µ—А —Д–Є–Ј. –њ–∞–Љ—П—В–Є –≤–ї–Є—П–µ—В –љ–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М, –њ–Њ—В–Њ–Љ—Г —З—В–Њ —З–µ–Љ –Љ–µ–љ—М—И–µ —Д–Є–Ј. –њ–∞–Љ—П—В—М, —В–µ–Љ —З–∞—Й–µ –њ—А–Є—Е–Њ–і–Є—В—Б—П —В—Г–і–∞-—Б—О–і–∞ –≥–Њ–љ—П—В—М —Б—В—А–∞–љ–Є—Ж—Л).
–Ґ–µ–њ–µ—А—М, –µ—Б–ї–Є –њ–Њ—Б–Љ–Њ—В—А–µ—В—М –љ–∞ –Њ—В–і–µ–ї—М–љ—Л–є –њ—А–Њ—Ж–µ—Б—Б –Є –њ–Њ—Б–Љ–Њ—В—А–µ—В—М –љ–∞ –µ–≥–Њ –∞–і—А–µ—Б–љ–Њ–µ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–Њ, –ї—О–±–∞—П —Б—В—А–∞–љ–Є—Ж–∞ –≤ –љ—С–Љ –Љ–Њ–ґ–µ—В –±—Л—В—М:
- –Я—Г—Б—В–Њ–є (–љ–µ —А–∞–Ј–Љ–µ—Й—С–љ–љ–Њ–є) вАФ –њ–Њ–њ—Л—В–Ї–∞ –і–Њ—Б—В—Г–њ–∞ –Ї –љ–µ–є –Њ–±–Њ—А–∞—З–Є–≤–∞–µ—В—Б—П –Є—Б–Ї–ї—О—З–µ–љ–Є–µ–Љ (—Б–±–Њ–µ–Љ).
- –Ч–∞–љ—П—В–Њ–є, –Є –љ–∞—Е–Њ–і–Є—В—М—Б—П –≤ –і–∞–љ–љ—Л–є –Љ–Њ–Љ–µ–љ—В –≤—А–µ–Љ–µ–љ–Є –≤ —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є.
- –Ч–∞–љ—П—В–Њ–є, –Є –љ–∞—Е–Њ–і–Є—В—М—Б—П –≤ –і–∞–љ–љ—Л–є –Љ–Њ–Љ–µ–љ—В –≤—А–µ–Љ–µ–љ–Є –љ–∞ –і–Є—Б–Ї–µ.
–Ґ–µ–њ–µ—А—М —Б–∞–Љ–Њ–µ –Є–љ—В–µ—А–µ—Б–љ–Њ–µ.
–Т–Њ–Њ–±—Й–µ-—В–Њ, –Є–Ј —Н—В–Њ–≥–Њ –≤—Б–µ–≥–Њ –љ—Г–ґ–љ–Њ —Б–і–µ–ї–∞—В—М –≤—Л–≤–Њ–і, —З—В–Њ —Д–Є–Ј–Є—З–µ—Б–Ї–∞—П –њ–∞–Љ—П—В—М –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П —В–Њ–ї—М–Ї–Њ –Ї–∞–Ї –≤—А–µ–Љ–µ–љ–љ—Л–є –±—Г—Д–µ—А –і–ї—П —В–µ–Ї—Г—Й–µ–є —А–∞–±–Њ—В—Л —Б–Њ —Б—В—А–∞–љ–Є—Ж–∞–Љ–Є. –Ф–∞–љ–љ—Л–µ, —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й–Є–µ —Б—В—А–∞–љ–Є—Ж–µ –≤–Є—А—В—Г–∞–ї—М–љ–Њ–≥–Њ –Р–Я, –њ–µ—А–µ–љ–Њ—Б—П—В—Б—П –≤ —Д–Є–Ј–Є—З–µ—Б–Ї—Г—О –њ–∞–Љ—П—В—М —В–Њ–ї—М–Ї–Њ —В–Њ–≥–і–∞, –Ї–Њ–≥–і–∞ –њ–Њ–є–і—С—В –Њ–±—А–∞—Й–µ–љ–Є–µ –Ї –і–∞–љ–љ–Њ–є —Б—В—А–∞–љ–Є—Ж–µ (—З—В–µ–љ–Є–µ –Є–ї–Є –Ј–∞–њ–Є—Б—М). –Э–µ –±—Г–і–µ—В –Њ–±—А–∞—Й–µ–љ–Є–є вАФ¬†—Б—В—А–∞–љ–Є—Ж–∞ –±—Г–і–µ—В –≤—Л–Ї–Є–љ—Г—В–∞ –Є–Ј —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є –Њ–±—А–∞—В–љ–Њ –љ–∞ –і–Є—Б–Ї, –∞ –љ–∞ –µ—С –Љ–µ—Б—В–Њ –±—Г–і–µ—В –Ј–∞–≥—А—Г–ґ–µ–љ–∞ –±–Њ–ї–µ–µ –љ—Г–ґ–љ–∞—П —Б—В—А–∞–љ–Є—Ж–∞.
–Ґ–∞–Ї —З—В–Њ –ї—О–±–∞—П —Б—В—А–∞–љ–Є—Ж–∞ –љ–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ –Ї–∞–Ї –Њ—Б–љ–Њ–≤–љ–Њ–µ —Е—А–∞–љ–Є–ї–Є—Й–µ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В –ґ–µ—Б—В–Ї–Є–є –і–Є—Б–Ї. –Ґ–µ–њ–µ—А—М –≤–∞–ґ–љ–Њ –њ–Њ–љ—П—В—М, –≥–і–µ –Є–Љ–µ–љ–љ–Њ –љ–∞ –і–Є—Б–Ї–µ —Е—А–∞–љ—П—В—Б—П —Б—В—А–∞–љ–Є—Ж—Л. –°—Г—Й–µ—Б—В–≤—Г–µ—В –і–≤–∞ –≤–Њ–Ј–Љ–Њ–ґ–љ—Л—Е —Е—А–∞–љ–Є–ї–Є—Й–∞. –≠—В–Њ –Љ–Њ–ґ–µ—В –±—Л—В—М:
- –Я—А–Њ–Є–Ј–≤–Њ–ї—М–љ—Л–є —Д–∞–є–ї –љ–∞ –і–Є—Б–Ї–µ.
- –§–∞–є–ї –њ–Њ–і–Ї–∞—З–Ї–Є
–Ю–њ–µ—А–∞—Ж–Є–Њ–љ–љ–∞—П —Б–Є—Б—В–µ–Љ–∞ –њ–Њ–Ј–≤–Њ–ї—П–µ—В –ї—О–±–Њ–Љ—Г –њ—А–Њ—Ж–µ—Б—Б—Г —Б–њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞—В—М –ї—О–±–Њ–є —Д–∞–є–ї —Б –ї—О–±–Њ–≥–Њ –і–Є—Б–Ї–∞ –≤ —Б–≤–Њ—С –≤–Є—А—В—Г–∞–ї—М–љ–Њ–µ –∞–і—А–µ—Б–љ–Њ–µ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–Њ. –Я—А–Є —Н—В–Њ–Љ –њ—А–Њ–≥—А–∞–Љ–Љ–∞ (–њ—А–Њ—Ж–µ—Б—Б) —Г–≤–Є–і–Є—В –≤ —Б–≤–Њ—С–Љ –Р–Я –і–∞–љ–љ—Л–µ, –Ї–Њ—В–Њ—А—Л–µ —А–∞–Ј–Љ–µ—Й–∞—О—В—Б—П –≤ —Д–∞–є–ї–µ. –Х—Б–ї–Є –њ—А–Њ–≥—А–∞–Љ–Љ–∞ –±—Г–і–µ—В –њ—А—П–Љ–Њ –≤ –њ–∞–Љ—П—В–Є –Љ–Њ–і–Є—Д–Є—Ж–Є—А–Њ–≤–∞—В—М —Н—В–Є –і–∞–љ–љ—Л–µ, –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є–Є –Њ—В—А–∞–Ј—П—В—Б—П –Є –≤ —Д–∞–є–ї–µ. –Э–µ—Б–Ї–Њ–ї—М–Ї–Њ —А–∞–Ј–љ—Л—Е –њ—А–Њ—Ж–µ—Б—Б–Њ–≤ –Љ–Њ–≥—Г—В –Њ–і–Є–љ –Є —В–Њ—В –ґ–µ —Д–∞–є–ї —Б–њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞—В—М –≤ —Б–≤–Њ—С –Р–Я. –Я—А–Є —Н—В–Њ–Љ, –µ—Б–ї–Є –Њ–і–Є–љ –њ—А–Њ—Ж–µ—Б—Б –Љ–Њ–і–Є—Д–Є—Ж–Є—А—Г–µ—В —Б–њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞–љ–љ—Л–µ –і–∞–љ–љ—Л–µ, —В–Њ –і—А—Г–≥–Њ–є –њ—А–Њ—Ж–µ—Б—Б —Г–≤–Є–і–Є—В —Н—В–Є –Є–Ј–Љ–µ–љ–µ–љ–Є—П —Б—А–∞–Ј—Г –ґ–µ (–Є –≤ —Д–∞–є–ї–µ —Н—В–Є –Є–Ј–Љ–µ–љ–µ–љ–Є—П —В–Њ–ґ–µ –Њ—В—А–∞–Ј—П—В—Б—П).
–Ю —В–∞–Ї–Є—Е —Б—В—А–∞–љ–Є—Ж–∞—Е –≥–Њ–≤–Њ—А—П—В, —З—В–Њ –Њ–љ–Є image-backed.
–Ю–њ–µ—А–∞—Ж–Є–Њ–љ–љ–∞—П —Б–Є—Б—В–µ–Љ–∞, –Ї—А–Њ–Љ–µ —В–Њ–≥–Њ, –њ–Њ–Ј–≤–Њ–ї—П–µ—В –ї—О–±–Њ–Љ—Г –њ—А–Њ—Ж–µ—Б—Б—Г –њ—А–Њ—Б—В–Њ –≤—Л–і–µ–ї–Є—В—М –і–ї—П —Б–≤–Њ–Є—Е –љ—Г–ґ–і —Б–Ї–Њ–ї—М–Ї–Њ-—В–Њ –њ—Г—Б—В—Л—Е —Б—В—А–∞–љ–Є—Ж. –Ґ–∞–Ї–Є–µ —Б—В—А–∞–љ–Є—Ж—Л –љ–µ —П–≤–ї—П—О—В—Б—П –њ—А–Њ–µ–Ї—Ж–Є–µ–є –Ї–∞–Ї–Њ–≥–Њ-—В–Њ –Ї–Њ–љ–Ї—А–µ—В–љ–Њ–≥–Њ —Д–∞–є–ї–∞ –љ–∞ –і–Є—Б–Ї–µ –љ–∞ –њ–µ—А–≤—Л–є –≤–Ј–≥–ї—П–і, –љ–Њ –љ–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ –≤ –Ї–∞—З–µ—Б—В–≤–µ —Е—А–∞–љ–Є–ї–Є—Й–∞ –і–ї—П –і–∞–љ–љ—Л—Е —В–∞–Ї–Є—Е —Б—В—А–∞–љ–Є—Ж –≤—Л—Б—В—Г–њ–∞–µ—В —Д–∞–є–ї –њ–Њ–і–Ї–∞—З–Ї–Є. –Ґ–∞–Ї–Є–µ —Б—В—А–∞–љ–Є—Ж—Л –љ–∞–Ј—Л–≤–∞—О—В—Б—П swap-backed (–њ–Њ—В–Њ–Љ—Г —З—В–Њ –Њ–і–љ–Њ –Є–Ј –љ–∞–Ј–≤–∞–љ–Є–є —Д–∞–є–ї–∞ –њ–Њ–і–Ї–∞—З–Ї–Є вАФ¬†swap-file, –Є —Б–∞–Љ –њ—А–Њ—Ж–µ—Б—Б, –њ—А–Є –Ї–Њ—В–Њ—А–Њ–Љ –Є–Ј —Д–Є–Ј–њ–∞–Љ—П—В–Є —Б—В—А–∞–љ–Є—Ж–∞ —Б–±—А–∞—Б—Л–≤–∞–µ—В—Б—П –љ–∞ –і–Є—Б–Ї, –∞ –љ–∞ –µ—С –Љ–µ—Б—В–Њ –њ–Њ–і–≥—А—Г–ґ–∞–µ—В—Б—П —Б –і–Є—Б–Ї–∞ –і—А—Г–≥–∞—П —Б—В—А–∞–љ–Є—Ж–∞, –љ–∞–Ј—Л–≤–∞–µ—В—Б—П swapping).
–Ш —В–µ–њ–µ—А—М –≤–Њ–Ј–љ–Є–Ї–∞–µ—В –≤–Њ–њ—А–Њ—Б? –Ґ–∞–Ї —З–µ–Љ –ґ–µ –Њ–≥—А–∞–љ–Є—З–µ–љ–Њ –њ–Њ—В—А–µ–±–ї–µ–љ–Є–µ –њ–∞–Љ—П—В–Є –Њ—В–і–µ–ї—М–љ–Њ –≤–Ј—П—В—Л–Љ –њ—А–Њ—Ж–µ—Б—Б–Њ–Љ?
–Т–Њ–Ј–≤—А–∞—Й–∞—О—Б—М –Ї –љ–∞—З–∞–ї—Г.
–£ –Ї–∞–ґ–і–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ –µ—Б—В—М —Б–≤–Њ—С –Р–Я —А–∞–Ј–Љ–µ—А–Њ–Љ 4 –У–±. –Ь–Њ–ґ–љ–Њ —Б—З–Є—В–∞—В—М, —З—В–Њ –Є–Ј–љ–∞—З–∞–ї—М–љ–Њ —Н—В–Њ –Р–Я –њ—Г—Б—В–Њ–µ, –њ–Њ–њ—Л—В–Ї–∞ –Њ–±—А–∞—Й–µ–љ–Є—П –Ї –Ї–∞–Ї–Њ–є-–ї–Є–±–Њ —Б—В—А–∞–љ–Є—Ж–µ –њ—А–Є–≤–µ–і—С—В –Ї —Б–±–Њ—О. –Ю—В—Б—О–і–∞ —Б–ї–µ–і—Г–µ—В, —З—В–Њ —В–µ–Њ—А–µ—В–Є—З–µ—Б–Ї–Є –љ–µ–≤–Њ–Ј–Љ–Њ–ґ–љ–Њ –≤ –Њ–і–љ–Њ–Љ –Р–Я –Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ–Њ –Є–Љ–µ—В—М –±–Њ–ї–µ–µ, —З–µ–Љ 4 –У–± –і–∞–љ–љ—Л—Е.
–Я—А–Њ—Ж–µ—Б—Б –Љ–Њ–ґ–µ—В –Ј–∞–њ–Њ–ї–љ—П—В—М —Б–≤–Њ—С –Р–Я –ї–Є–±–Њ –њ—А–Њ—Б—В–Њ –≤—Л–і–µ–ї—П—П –њ—Г—Б—В—Л–µ —Б—В—А–∞–љ–Є—Ж—Л –і–ї—П —Б–µ–±—П (swap-backed), –ї–Є–±–Њ –њ—А–Њ–µ—Ж–Є—А—Г—П –Ї–∞–Ї–Є–µ-—В–Њ —Д–∞–є–ї—Л –≤ —Б–≤–Њ—С –Р–Я (image-backed/file-backed).
–Ю–±—Й–µ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ image-backed —Б—В—А–∞–љ–Є—Ж –і–ї—П –≤—Б–µ—Е –њ—А–Њ—Ж–µ—Б—Б–Њ–≤ –≤–Љ–µ—Б—В–µ –≤–Ј—П—В—Л—Е –њ–Њ –Є–і–µ–µ –љ–µ –Њ–≥—А–∞–љ–Є—З–µ–љ–Њ –љ–Є—З–µ–Љ. –Ф–ї—П –Њ—В–і–µ–ї—М–љ–Њ –≤–Ј—П—В–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ –Њ–≥—А–∞–љ–Є—З–µ–љ–Њ —А–∞–Ј–Љ–µ—А–∞–Љ–Є –Р–Я.
–Ю–±—Й–µ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ swap-backed —Б—В—А–∞–љ–Є—Ж –і–ї—П –≤—Б–µ—Е –њ—А–Њ—Ж–µ—Б—Б–Њ–≤ –≤–Љ–µ—Б—В–µ –≤–Ј—П—В—Л—Е –Њ–≥—А–∞–љ–Є—З–µ–љ–Њ —А–∞–Ј–Љ–µ—А–∞–Љ–Є —Д–∞–є–ї–∞ –њ–Њ–і–Ї–∞—З–Ї–Є (–Є–ї–Є –≤—Б–µ—Е —Д–∞–є–ї–Њ–≤ –њ–Њ–і–Ї–∞—З–Ї–Є –≤–Љ–µ—Б—В–µ –≤–Ј—П—В—Л—Е, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –Є—Е –Љ–Њ–ґ–µ—В –±—Л—В—М –±–Њ–ї–µ–µ –Њ–і–љ–Њ–≥–Њ). –Ф–ї—П –Њ–і–љ–Њ–≥–Њ –Њ—В–і–µ–ї—М–љ–Њ –≤–Ј—П—В–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ –Њ–љ–Њ –Њ–≥—А–∞–љ–Є—З–µ–љ–Њ —А–∞–Ј–Љ–µ—А–∞–Љ–Є –Р–Я.
–Э–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ, –Ї–Њ–љ–µ—З–љ–Њ, –і–ї—П –њ–Њ–і–і–µ—А–ґ–∞–љ–Є—П –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Є –Њ –њ—А–Њ—Ж–µ—Б—Б–∞—Е, –Њ —В–Њ–Љ, –Ї–∞–Ї–Є–µ —Б—В—А–∞–љ–Є—Ж—Л –Є—Е –Р–Я —З–µ–Љ—Г —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—В, —В–Њ–ґ–µ —А–∞—Б—Е–Њ–і—Г–µ—В—Б—П –њ–∞–Љ—П—В—М, —В–∞–Ї —З—В–Њ –љ—Г–ґ–љ–Њ –і–µ–ї–∞—В—М –љ–µ–Ї—Г—О –њ–Њ–њ—А–∞–≤–Ї—Г, –Ї–Њ–≥–і–∞ —П –≥–Њ–≤–Њ—А—О ¬Ђ–љ–µ –Њ–≥—А–∞–љ–Є—З–µ–љ–Њ –љ–Є—З–µ–Љ¬ї.
–ѓ –њ—А–Є–≤–µ–і—Г —В–∞–Ї—Г—О –∞–љ–∞–ї–Њ–≥–Є—О –і–ї—П –ї—Г—З—И–µ–≥–Њ –њ–Њ–љ–Є–Љ–∞–љ–Є—П —В–Њ–≥–Њ, –Ї–∞–Ї –Ї–Њ—А—А–µ–ї–Є—А—Г–µ—В —А–∞–Ј–Љ–µ—А –Р–Я –Є —А–∞–Ј–Љ–µ—А —Д–∞–є–ї–∞ –њ–Њ–і–Ї–∞—З–Ї–Є:
- –Э—Г–ґ–љ–Њ –њ—А–µ–і—Б—В–∞–≤–Є—В—М —Б–µ–±–µ, —З—В–Њ –µ—Б—В—М 10 –≥–Њ—Б—В–Є–љ–Є—Ж –њ–Њ 100 –Љ–µ—Б—В. –£ —Н—В–Є—Е –≥–Њ—Б—В–Є–љ–Є—Ж –Њ–і–Є–љ –Њ–±—Й–Є–є —Е–Њ–Ј—П–Є–љ, —Г –Ї–Њ—В–Њ—А–Њ–≥–Њ –µ—Б—В—М —Б–Ї–ї–∞–і, –љ–∞ –Ї–Њ—В–Њ—А–Њ–Љ —Е—А–∞–љ–Є—В—Б—П 600 –Ї–Њ–Љ–њ–ї–µ–Ї—В–Њ–≤ –њ–Њ—Б—В–µ–ї—М–љ–Њ–≥–Њ –±–µ–ї—М—П.
–Ю—В–і–µ–ї—М–љ–Њ –≤–Ј—П—В–∞—П –≥–Њ—Б—В–Є–љ–Є—Ж–∞ вАФ —Н—В–Њ –њ—А–Њ—Ж–µ—Б—Б.
–Ф–Є–∞–њ–∞–Ј–Њ–љ –≥–Њ—Б—В–Є–љ–Є—З–љ—Л—Е –љ–Њ–Љ–µ—А–Њ–≤ –Њ—В 1 –і–Њ 100 вАФ —Н—В–Њ –∞–і—А–µ—Б–љ–Њ–µ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–Њ –њ—А–Њ—Ж–µ—Б—Б–∞.
–Т–ї–∞–і–µ–ї–µ—Ж –≤—Б–µ—Е –≥–Њ—Б—В–Є–љ–Є—Ж вАФ —Н—В–Њ –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ–∞—П —Б–Є—Б—В–µ–Љ–∞.
–°–Ї–ї–∞–і, –≥–і–µ —Е—А–∞–љ—П—В—Б—П –Ї–Њ–Љ–њ–ї–µ–Ї—В—Л –њ–Њ—Б—В–µ–ї—М–љ–Њ–≥–Њ –±–µ–ї—М—П вАФ —Н—В–Њ —Д–∞–є–ї –њ–Њ–і–Ї–∞—З–Ї–Є.
–Т—Л –њ—А–Є–µ–Ј–ґ–∞–µ—В–µ –≤ –≥–Њ—Б—В–Є–љ–Є—Ж—Г –Є —Б–њ—А–∞—И–Є–≤–∞–µ—В–µ ¬Ђ—Б–Ї–Њ–ї—М–Ї–Њ –≤–Њ–Њ–±—Й–µ —Г –≤–∞—Б –љ–Њ–Љ–µ—А–Њ–≤?¬ї, –Є –≤–∞–Љ –Њ—В–≤–µ—З–∞—О—В ¬Ђ100¬ї. –≠—В–Њ —В–µ–Њ—А–µ—В–Є—З–µ—Б–Ї–Њ–µ –Њ–≥—А–∞–љ–Є–µ–љ–Є–µ, –Њ–њ—А–µ–і–µ–ї—П—О—Й–µ–µ, —Б–Ї–Њ–ї—М–Ї–Њ –≤–Њ–Њ–±—Й–µ —З–µ–ї–Њ–≤–µ–Ї –Љ–Њ–ґ–љ–Њ –Ј–∞—Б–µ–ї–Є—В—М –≤ –Њ–і–љ—Г –≥–Њ—Б—В–Є–љ–Є—Ж—Г. –С–Њ–ї—М—И–µ —Н—В–Њ–≥–Њ вАФ –љ–Є–Ї–∞–Ї –љ–µ –њ–Њ–ї—Г—З–Є—В—Б—П.
–Ъ–∞–ґ–і—Л–є –Њ—В–і–µ–ї—М–љ–Њ –≤–Ј—П—В—Л–є –љ–Њ–Љ–µ—А –≥–Њ—Б—В–Є–љ–Є—Ж—Л –Љ–Њ–ґ–µ—В –±—Л—В—М –ї–Є–±–Њ —Б–≤–Њ–±–Њ–і–µ–љ, –ї–Є–±–Њ –Ј–∞—Б–µ–ї—С–љ. –Я–Њ–і–Њ–±–љ–Њ —Н—В–Њ–Љ—Г, –Ї–∞–ґ–і–∞—П —Б—В—А–∞–љ–Є—Ж–∞ –∞–і—А–µ—Б–љ–Њ–≥–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–∞ –Љ–Њ–ґ–µ—В –±—Л—В—М –ї–Є–±–Њ –љ–µ –Ј–∞–љ—П—В–∞ (—Б–≤–Њ–±–Њ–і–љ–∞), –ї–Є–±–Њ —А–∞–Ј–Љ–µ—Й–µ–љ–∞.
–Т—Л –Љ–Њ–ґ–µ—В–µ –њ—А–Є–µ—Е–∞—В—М –≤ –≥–Њ—Б—В–Є–љ–Є—Ж—Г –Є —Б–њ—А–Њ—Б–Є—В—М ¬Ђ—Б–Ї–Њ–ї—М–Ї–Њ —Г –≤–∞—Б –љ–µ–Ј–∞—Б–µ–ї—С–љ–љ—Л—Е –љ–Њ–Љ–µ—А–Њ–≤?¬ї, –Є –≤–∞–Љ –Њ—В–≤–µ—В—П—В ¬Ђ70¬ї. –Э–Њ –њ—А–Є –њ–Њ–њ—Л—В–Ї–µ –Ј–∞—Б–µ–ї–Є—В—М—Б—П –≤–∞–Љ –Њ—В–Ї–∞–ґ—Г—В, –њ–Њ—В–Њ–Љ—Г —З—В–Њ —Е–Њ—В—М –≤ –≥–Њ—Б—В–Є–љ–Є—Ж–µ –Є –µ—Б—В—М 70 —Б–≤–Њ–±–Њ–і–љ—Л—Е –љ–Њ–Љ–µ—А–Њ–≤, –љ–∞ —Б–Ї–ї–∞–і–µ –љ–µ –Њ—Б—В–∞–ї–Њ—Б—М –љ–Є –Њ–і–љ–Њ–≥–Њ –Ї–Њ–Љ–њ–ї–µ–Ї—В–∞ –њ–Њ—Б—В–µ–ї—М–љ–Њ–≥–Њ –±–µ–ї—М—П. –Ш –µ—Б–ї–Є –≤—Л –њ–Њ–µ–і–µ—В–µ –≤ –і—А—Г–≥—Г—О –≥–Њ—Б—В–Є–љ–Є—Ж—Г, –≥–і–µ —В–Њ–ґ–µ –µ—Б—В—М —Б–≤–Њ–±–Њ–і–љ—Л–µ –љ–Њ–Љ–µ—А–∞, –≤–∞–Љ —В–Њ–ґ–µ –Њ—В–Ї–∞–ґ—Г—В –≤ –Ј–∞—Б–µ–ї–µ–љ–Є–Є вАФ —Е–Њ–Ј—П–Є–љ –Њ–і–Є–љ –Є —В–Њ—В –ґ–µ, –Є –љ–∞ —Б–Ї–ї–∞–і–µ –њ–Њ –њ—А–µ–ґ–љ–µ–Љ—Г –љ–µ—В –љ–Є –Њ–і–љ–Њ–≥–Њ –Ї–Њ–Љ–њ–ї–µ–Ї—В–∞ –њ–Њ—Б—В–µ–ї—М–љ–Њ–≥–Њ –±–µ–ї—М—П. –Ш–Љ–µ–љ–љ–Њ —В–∞–Ї –Є —А–∞–±–Њ—В–∞–µ—В –Њ–±—Й–µ—Б–Є—Б—В–µ–Љ–љ–Њ–µ –Њ–≥—А–∞–љ–Є—З–µ–љ–Є–µ –љ–∞ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –≤—Л–і–µ–ї–µ–љ–љ—Л—Е —Б—В—А–∞–љ–Є—Ж вАФ –Њ–љ–Њ –Њ–≥—А–∞–љ–Є—З–µ–љ–Њ —А–∞–Ј–Љ–µ—А–∞–Љ–Є —Д–∞–є–ї–∞ –њ–Њ–і–Ї–∞—З–Ї–Є. –Т—Б–µ –њ—А–Њ—Ж–µ—Б—Б—Л –≤ —Б—Г–Љ–Љ–µ –љ–µ –Љ–Њ–≥—Г—В –Є–Љ–µ—В—М –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –≤—Л–і–µ–ї–µ–љ–љ—Л—Е —Б—В—А–∞–љ–Є—Ж –±–Њ–ї—М—И–µ, —З–µ–Љ –њ–Њ–Ј–≤–Њ–ї—П–µ—В —А–∞–Ј–Љ–µ—А —Д–∞–є–ї–∞ –њ–Њ–і–Ї–∞—З–Ї–Є, –љ–µ—Б–Љ–Њ—В—А—П –љ–∞ —В–Њ, —З—В–Њ —Г –Ї–∞–ґ–і–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ –≤–µ—Б—М–Љ–∞ –±–Њ–ї—М—И–Њ–µ —Б–Њ–±—Б—В–≤–µ–љ–љ–Њ–µ –∞–і—А–µ—Б–љ–Њ–µ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–Њ. –Я–Њ–і–Њ–±–љ–Њ —В–Њ–Љ—Г, –Ї–∞–Ї –Њ–±—Й–µ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –Ј–∞—Б–µ–ї—С–љ–љ—Л—Е –љ–Њ–Љ–µ—А–Њ–≤ –і–ї—П –≤—Б–µ—Е 10 –≥–Њ—Б—В–Є–љ–Є—Ж –љ–µ –Љ–Њ–ґ–µ—В –±—Л—В—М –±–Њ–ї—М—И–µ, —З–µ–Љ 600 (—З–µ–Љ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Б–њ–∞–ї—М–љ—Л—Е –Ї–Њ–Љ–њ–ї–µ–Ї—В–Њ–≤ –љ–∞ –Њ–±—Й–µ–Љ —Б–Ї–ї–∞–і–µ).
–° –і—А—Г–≥–Њ–є —Б—В–Њ—А–Њ–љ—Л, –µ—Б–ї–Є –њ—А–Є–µ—Е–∞—В—М –≤ —В–∞–Ї—Г—О –≥–Њ—Б—В–Є–љ–Є—Ж—Г —Б–Њ —Б–≤–Њ–Є–Љ —Б–≤–Њ–Є–Љ–Є —Б–Њ–±—Б—В–≤–µ–љ–љ—Л–Љ–Є –Ї–Њ–Љ–њ–ї–µ–Ї—В–∞–Љ–Є –њ–Њ—Б—В–µ–ї—М–љ–Њ–≥–Њ –±–µ–ї—М—П, —В–Њ –≤–∞—Б –Ј–∞—Б–µ–ї—П—В (–њ—А–Є —Г—Б–ї–Њ–≤–Є–Є, —З—В–Њ –µ—Б—В—М —Б–≤–Њ–±–Њ–і–љ—Л–µ –љ–Њ–Љ–µ—А–∞), –Є –Њ—Б—В–∞–≤—И–µ–µ—Б—П –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –Ї–Њ–Љ–њ–ї–µ–Ї—В–Њ–≤ –љ–∞ –Њ–±—Й–µ–Љ —Б–Ї–ї–∞–і–µ –љ–∞ –≤–∞—Б –љ–Є–Ї–∞–Ї –љ–µ –њ–Њ–≤–ї–Є—П–µ—В. –Ч–∞—Б–µ–ї–µ–љ–Є—О –≤ –љ–Њ–Љ–µ—А–∞ —Б —Б–Њ–±—Б—В–≤–µ–љ–љ—Л–Љ –њ–Њ—Б—В–µ–ї—М–љ—Л–Љ –±–µ–ї—М—С–Љ (–≤–Љ–µ—Б—В–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П –±–µ–ї—М—П —Б –Њ–±—Й–µ–≥–Њ —Б–Ї–ї–∞–і–∞) —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞–љ–Є—О –≤ –Р–Я –њ—А–Њ—Ж–µ—Б—Б–∞ —Б—В—А–∞–љ–Є—Ж –Є–Ј –Ї–∞–Ї–Њ–≥–Њ-—В–Њ –њ—А–Њ–Є–Ј–≤–Њ–ї—М–љ–Њ–≥–Њ —Д–∞–є–ї–∞ –љ–∞ –і–Є—Б–Ї–µ (–≤–Љ–µ—Б—В–Њ –≤—Л–і–µ–ї–µ–љ–Є—П –љ–Њ–≤—Л—Е –њ—Г—Б—В—Л—Е —Б—В—А–∞–љ–Є—Ж, –љ–∞ —З—В–Њ —А–∞—Б—Е–Њ–і—Г–µ—В—Б—П —Д–∞–є–ї –њ–Њ–і–Ї–∞—З–Ї–Є).
____________
–Ґ–µ–њ–µ—А—М –Њ –Ј–∞—Й–Є—В–µ. –Я–Њ–Љ–Є–Љ–Њ —В–Њ–≥–Њ, —З—В–Њ –Ї–∞–ґ–і—Л–є –њ—А–Њ—Ж–µ—Б—Б –Є–Љ–µ–µ—В –Є–Ј–Њ–ї–Є—А–Њ–≤–∞–љ–љ–Њ–µ –Њ—В –і—А—Г–≥–Є—Е –њ—А–Њ—Ж–µ—Б—Б–Њ–≤ –Р–Я, –Є –њ–Њ–Љ–Є–Љ–Њ —В–Њ–≥–Њ, —З—В–Њ –Р–Я –і—А–Њ–±–Є—В—Б—П –љ–∞ —Б—В—А–∞–љ–Є—Ж—Л (—А–∞–Ј–Љ–µ—А–Њ–Љ 4 –Ї–±), –Ї–Њ—В–Њ—А—Л–µ –Љ–Њ–≥—Г—В –±—Л—В—М –ї–Є–±–Њ –њ—Г—Б—В—Л–Љ–Є, –ї–Є–±–Њ –±—Л—В—М –њ—А–Њ–µ–Ї—Ж–Є–µ–є –Ї–∞–Ї–Њ–≥–Њ-—В–Њ —Д–∞–є–ї–∞, –ї–Є–±–Њ —Е—А–∞–љ–Є—В—М—Б—П –≤ —Д–∞–є–ї–µ –њ–Њ–і–Ї–∞—З–Ї–Є, –Ї–∞–ґ–і–∞—П —Б—В—А–∞–љ–Є—Ж–∞ –Є–Љ–µ–µ—В –∞—В—А–Є–±—Г—В—Л –Ј–∞—Й–Є—В—Л.
–Р—В—А–Є–±—Г—В—Л –Ј–∞—Й–Є—В—Л —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—О—В, –Љ–Њ–ґ–µ—В –ї–Є —Б–∞–Љ –њ—А–Њ—Ж–µ—Б—Б –Ј–∞–њ–Є—Б—Л–≤–∞—В—М —З—В–Њ-—В–Њ –≤ —Н—В—Г —Б—В—А–∞–љ–Є—Ж—Г, –Љ–Њ–ґ–µ—В –ї–Є –Њ–љ —З–Є—В–∞—В—М —З—В–Њ-—В–Њ –Є–Ј —Н—В–Њ–є —Б—В—А–∞–љ–Є—Ж–µ –Є –Љ–Њ–ґ–µ—В –ї–Є –≤—Л–њ–Њ–ї–љ—П—В—М—Б—П –Ї–Њ–і, —Е—А–∞–љ—П—Й–Є–є—Б—П –≤ —Н—В–Њ–є —Б—В—А–∞–љ–Є—Ж–µ.
–°–Њ–Ї—А–∞—Й—С–љ–љ–Њ –∞—В—А–Є–±—Г—В—Л –і–Њ—Б—В—Г–њ–∞ —Б—В—А–∞–љ–Є—Ж—Л –Њ–њ–Є—Б—Л–≤–∞—О—В—Б—П –±—Г–Ї–≤–∞–Љ–Є RWE (Read/Write/Execute). –Р—В—А–Є–±—Г—В—Л –Ј–∞—Й–Є—В—Л —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—О—В—Б—П –њ–Њ-—Б—В—А–∞–љ–Є—З–љ–Њ вАФ –≤—Б—П —Б—В—А–∞–љ–Є—Ж–∞ —Ж–µ–ї–Є–Ї–Њ–Љ –Є–Љ–µ–µ—В –Њ–і–љ–Є –Є —В–µ –ґ–µ –∞—В—А–Є–±—Г—В—Л. –Э–µ–ї—М–Ј—П –њ–Њ–ї–Њ–≤–Є–љ–µ —Б—В—А–∞–љ–Є—Ж–µ –і–∞—В—М –Њ–і–љ–Є –∞—В—А–Є–±—Г—В—Л, –∞ –≤—В–Њ—А–Њ–є –њ–Њ–ї–Њ–≤–Є–љ–µ вАФ¬†–і—А—Г–≥–Є–µ.
–Р—В—А–Є–±—Г—В—Л –њ–Њ–Ј–≤–Њ–ї—П—О—В –њ–Њ–ї—Г—З–∞—В—М read-only —Б—В—А–∞–љ–Є—Ж—Л, –Ј–∞—Й–Є—Й—С–љ–љ—Л–µ –Њ—В –Ј–∞–њ–Є—Б–Є, –Є–ї–Є —Б—В—А–∞–љ–Є—Ж—Л, –Ј–∞—Й–Є—Й—С–љ–љ—Л–µ –Њ—В —З—В–µ–љ–Є—П, –Є–ї–Є —Б—В—А–∞–љ–Є—Ж—Л, –≤ –Ї–Њ—В–Њ—А—Л—Е –љ–µ –Љ–Њ–ґ–µ —А–∞–Ј–Љ–µ—Й–∞—В—М –Ї–Њ–і.
–Э–∞–њ–Њ–Љ–Є–љ–∞—О, —З—В–Њ Intel IA-32 –Є —Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ–Њ 32-–±–Є—В–љ—Л–µ Windows –Є—Б–њ–Њ–ї—М–Ј—Г—О—В —Д–Њ–љ-–љ–µ–є–Љ–∞–љ–Њ–≤—Б–Ї—Г—О –∞—А—Е–Є—В–µ–Ї—В—Г—А—Г (–≤ –њ—А–Њ—В–Є–≤–Њ–≤–µ—Б –У–∞—А–≤–∞—А–і—Б–Ї–Њ–є). –Р—А—Е–Є—В–µ–Ї—В—Г—А–∞ —Д–Њ–љ –Э–µ–є–Љ–∞–љ–∞ –њ—А–µ–і–њ–Њ–ї–∞–≥–∞–µ—В, —З—В–Њ –Є –і–∞–љ–љ—Л–µ, –Є –Ї–Њ–і —Е—А–∞–љ—П—В—Б—П –≤ –Њ–і–љ–Њ–Љ –Њ–±—Й–µ–Љ –∞–і—А–µ—Б–љ–Њ–Љ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–µ. –У—А—Г–±–Њ –≥–Њ–≤–Њ—А—П вАФ¬†–≤–њ–µ—А–µ–Љ–µ—И–Ї—Г. –Я–Њ —Б–Њ—Б–µ–і—Б—В–≤—Г —Б –Ї–∞–Ї–Є–Љ–Є-—В–Њ –і–∞–љ–љ—Л–Љ–Є –Љ–Њ–ґ–µ—В —Е—А–∞–љ–Є—В—М—Б—П –Ї–∞–Ї–Њ–є-—В–Њ –Ї–Њ–і.
–Х—Б–ї–Є –Ї–Њ–і –њ—А–Њ—Ж–µ—Б—Б–∞ –њ–Њ–њ—Л—В–∞–µ—В—Б—П –њ—А–Њ—З–Є—В–∞—В—М —З—В–Њ-—В–Њ –Є–Ј –љ–µ—А–∞–Ј–Љ–µ—Й—С–љ–љ–Њ–є —Б—В—А–∞–љ–Є—Ж—Л вАФ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –Є—Б–Ї–ї—О—З–µ–љ–Є–µ (—Б–±–Њ–є).
–Х—Б–ї–Є –Ї–Њ–і –њ–Њ–њ—Л—В–∞–µ—В—Б—П –њ—А–Њ—З–Є—В–∞—В—М —З—В–Њ-—В–Њ –Є–Ј —Б—В—А–∞–љ–Є—Ж—Л, —Г –Ї–Њ—В–Њ—А–Њ–є –љ–µ—В R-–∞—В—А–Є–±—Г—В–∞ вАФ¬†–њ—А–Њ–Є—Б—Е–Њ–і–Є—В –Є—Б–Ї–ї—О—З–µ–љ–Є–µ.
–Х—Б–ї–Є –Ї–Њ–і –њ–Њ–њ—Л—В–∞–µ—В—Б—П –Ј–∞–њ–Є—Б–∞—В—М —З—В–Њ-—В–Њ –≤ —Б—В—А–∞–љ–Є—Ж—Г, —Г –Ї–Њ—В–Њ—А–Њ–є –љ–µ—В W-–∞—В—А–Є–±—Г—В–∞ вАФ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –Є—Б–Ї–ї—О—З–µ–љ–Є–µ.
–Х—Б–ї–Є –Ї–Њ–і –њ–Њ–њ—Л—В–∞–µ—В—Б—П –њ–µ—А–µ–і–∞—В—М —Г–њ—А–∞–≤–ї–µ–љ–Є–µ –і—А—Г–≥–Њ–Љ—Г –Ї–Њ–і—Г, –Ї–Њ—В–Њ—А–Њ–є —Е—А–∞–љ–Є—В—Б—П –≤ —Б—В—А–∞–љ–Є—Ж–µ, –љ–µ –Є–Љ–µ—О—Й–µ–є E-–∞—В—А–Є–±—Г—В–∞ вАФ¬†–њ—А–Њ–Є—Б—Е–Њ–і–Є—В –Є—Б–Ї–ї—О—З–µ–љ–Є–µ.
–®–∞–≥ –≤–ї–µ–≤–Њ, —И–∞–≥ –≤–њ—А–∞–≤–Њ вАФ¬†—А–∞—Б—Б—В—А–µ–ї.
–Ш –Ј–і–µ—Б—М –љ—Г–ґ–љ–Њ —Б–і–µ–ї–∞—В—М –≤–∞–ґ–љ–Њ–µ –Ј–∞–Љ–µ—З–∞–љ–Є–µ. –Я–Њ–Љ–Є–Љ–Њ –≤—Б–µ–≥–Њ —Н—В–Њ–≥–Њ, –∞—А—Е–Є—В–µ–Ї—В—Г—А–∞ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞ –њ—А–µ–і–ї–∞–≥–∞–µ—В —А–∞–Ј–ї–Є—З–љ—Л–µ —А–µ–ґ–Є–Љ—Л —А–∞–±–Њ—В—Л –њ—А–Њ—Ж–µ—Б—Б–∞, –Њ—В–ї–Є—З–∞—О—Й–Є–µ—Б—П –њ–Њ —Г—А–Њ–≤–љ—П–Љ –њ—А–Є–≤–Є–ї–µ–≥–Є–є. –£—А–Њ–≤–љ–Є –њ—А–Є–≤–Є–ї–µ–≥–Є–є —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞—О—В, —З—В–Њ –Є–Љ–µ–љ–љ–Њ –Љ–Њ–ґ–µ—В –і–µ–ї–∞—В—М –≤—Л–њ–Њ–ї–љ—П—О—Й–Є–є—Б—П –≤ –і–∞–љ–љ—Л–є –Љ–Њ–Љ–µ–љ—В –Ї–Њ–і. –Т–Њ–Њ–±—Й–µ-—В–Њ –∞—А—Е–Є—В–µ–Ї—В—Г—А–∞ IA-32 –њ—А–µ–і–ї–∞–≥–∞–µ—В —Ж–µ–ї—Л—Е 4 —Г—А–Њ–≤–љ—П –њ—А–Є–≤–Є–ї–µ–≥–Є–є, —Б –Ї–Њ—В–Њ—А—Л–Љ–Є –Љ–Њ–ґ–µ—В —А–∞–±–Њ—В–∞—В—М –њ—А–Њ—Ж–µ—Б—Б–Њ—А (–Њ—В –љ–∞–Є–Љ–µ–љ–µ–µ –њ—А–Є–≤–Є–ї–µ–≥–Є—А–Њ–≤–∞–љ–љ–Њ–≥–Њ –і–Њ –љ–∞–Є–±–Њ–ї–µ–µ), –љ–Њ Windows –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В —В–Њ–ї—М–Ї–Њ –і–≤–∞ –Є–Ј –љ–Є—Е вАФ –љ–∞–Є–Љ–µ–љ–µ–µ –њ—А–Є–≤–Є–ї–µ–≥–Є—А–Њ–≤–∞–љ–љ—Л–є (Ring-3) –Є –љ–∞–Є–±–Њ–ї–µ–µ –њ—А–Є–≤–Є–ї–µ–≥–Є—А–Њ–≤–∞–љ–љ—Л–є (Ring-0).
–†–µ–ґ–Є–Љ Ring-3 (–Њ–љ –ґ–µ User-mode вАФ¬†–њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М—Б–Ї–Є–є —А–µ–ґ–Є–Љ) –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –і–ї—П –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –њ—А–Є–Ї–ї–∞–і–љ—Л—Е –њ—А–Њ–≥—А–∞–Љ–Љ. –†–µ–ґ–Є–Љ Ring-0 (kernel mode вАФ¬†—А–µ–ґ–Є–Љ —П–і—А–∞) –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –і–ї—П –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Ї–Њ–і–∞ —П–і—А–∞ –Ю–° –Є –Ї–Њ–і–∞ –і—А–∞–є–≤–µ—А–Њ–≤).
–Т–∞–ґ–љ—Л–є —Д–∞–Ї—В –љ–∞ —Б—З—С—В —А–µ–ґ–Є–Љ–Њ–≤ —А–∞–±–Њ—В—Л вАФ –Ї–Њ–і, —А–∞–±–Њ—В–∞—О—Й–Є–є –≤ user mode –љ–µ –Љ–Њ–ґ–µ—В –њ–Њ —Б–≤–Њ–µ–Љ—Г –ґ–µ–ї–∞–љ–Є—О –≤–Ј—П—В—М –Є –њ–Њ–Љ–µ–љ—П—В—М —А–µ–ґ–Є–Љ –љ–∞ kernel mode. –Х–і–Є–љ—Б—В–≤–µ–љ–љ—Л–є —Б–њ–Њ—Б–Њ–± –њ–Њ–Љ–µ–љ—П—В—М —В–µ–Ї—Г—Й–Є–є —А–µ–ґ–Є–Љ вАФ —Н—В–Њ —З–µ—А–µ–Ј —В–∞–Ї –љ–∞–Ј—Л–≤–∞–µ–Љ—Л–µ call gate. –Ю–њ–µ—А–∞—Ж–Є–Њ–љ–љ–∞—П —Б–Є—Б—В–µ–Љ–∞ –њ—А–µ–і–Њ—Б—В–∞–≤–ї—П–µ—В –њ—А–Є–Ї–ї–∞–і–љ—Л–Љ –њ—А–Њ–≥—А–∞–Љ–Љ–∞–Љ —Б–≤–Њ–Є —Б–Є—Б—В–µ–Љ–љ—Л–µ –≤—Л–Ј–Њ–≤—Л. –Ъ–Њ–і –њ—А–Є–Ї–ї–∞–і–љ—Л—Е –њ—А–Њ–≥—А–∞–Љ–Љ –і–µ–ї–∞–µ—В —Н—В–Є —Б–Є—Б—В–µ–Љ–љ—Л–µ –≤—Л–Ј–Њ–≤—Л –Є –≤ –Љ–Њ–Љ–µ–љ—В –≤—Л–Ј–Њ–≤–∞ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –њ–µ—А–µ–Ї–ї—О—З–µ–љ–Є–µ —А–µ–ґ–Є–Љ–∞ –љ–∞ kernel mode –Є –≤—Л–њ–Њ–ї–љ—П–µ—В—Б—П –Ї–Њ–і —П–і—А–∞ (–≤ —А–µ–ґ–Є–Љ–µ Ring-0). –Я—А–Є –≤–Њ–Ј–≤—А–∞—В–µ —Г–њ—А–∞–≤–ї–µ–љ–Є—П –≤—Л–Ј—Л–∞—О—Й–µ–Љ—Г –Ї–Њ–і—Г –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –Њ–±—А–∞—В–љ—Л–є –њ–µ—А–µ—Е–Њ–і –љ–∞ —А–µ–ґ–Є–Љ Ring-3.
–Ґ–∞–Ї —З—В–Њ –Ї–Њ–і –њ—А–Є–Ї–ї–∞–і–љ—Л—Е –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є –љ–Є–Ї–Њ–≥–і–∞ –љ–µ –≤—Л–њ–Њ–ї–љ—П–µ—В—Б—П –≤ Ring-0 –Є –љ–µ –Є–Љ–µ–µ—В –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є –Њ—Б—Г—Й–µ—Б—В–≤–ї—П—В—М –њ—А–Є–≤–µ–ї–Є–≥–Є—А–Њ–≤–∞–љ–љ—Л–µ –Њ–њ–µ—А–∞—Ж–Є–Є.
–Ш –≤–Њ—В –Ј–і–µ—Б—М –Њ—З–µ–љ—М –≤–∞–ґ–љ—Л–є —Д–∞–Ї—В.
Windows —Г—Б—В—А–Њ–µ–љ–∞ —В–∞–Ї, —З—В–Њ –Р–Я –Ї–∞–ґ–і–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ –і–µ–ї–Є—В—Б—П –љ–∞ –і–≤–µ —З–∞—Б—В–Є. –Я–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О 4-—Е –≥–Є–≥–∞–±–∞–є—В–љ–Њ–µ –Р–Я –і–µ–ї–Є—В—Б—П –љ–∞ –і–≤–µ –њ–Њ–ї–Њ–≤–Є–љ—Л –њ–Њ 2 –У–±. –°—В–∞—А—И–∞—П –њ–Њ–ї–Њ–≤–Є–љ–∞ —Е—А–∞–љ–Є—В –Ї–Њ–і –Є –і–∞–љ–љ—Л–µ, –і–Њ—Б—В—Г–њ–љ—Л–µ —В–Њ–ї—М–Ї–Њ –≤ kernel mode. –Т —А–µ–ґ–Є–Љ–µ user-mode (Ring-3) –њ–Њ–њ—Л—В–Ї–∞ –њ—А–Њ—Ж–µ—Б—Б–∞ –Њ–±—А–∞—В–Є—В—М—Б—П –Ї –ї—О–±–Њ–є —Б—В—А–∞–љ–Є—Ж–µ –Є–Ј ¬Ђ—Б—В–∞—А—И–µ–є –њ–Њ–ї–Њ–≤–Є–љ—Л¬ї (—В–Њ –µ—Б—В—М –љ–∞—З–Є–љ–∞—П —Б –∞–і—А–µ—Б–Њ–≤ 0x80000000 –Є –і–Њ 0xFFFFFFFF) –њ—А–Є–≤–Њ–і–Є—В –Ї –Є—Б–Ї–ї—О—З–µ–љ–Є—О (—Б–±–Њ—О).
–Ы–Є—И—М –љ–Є–ґ–љ—П—П –њ–Њ–ї–Њ–≤–Є–љ–∞ –Р–Я, –∞ –Є–Љ–µ–љ–љ–Њ –і–Є–∞–њ–∞–Ј–Њ–љ –∞–і—А–µ—Б–Њ–≤ –Њ—В 0x00000000 –і–Њ 0x7FFFFFFF, –і–Њ—Б—В—Г–њ–љ–∞ –Ї–Њ–і—Г –њ—А–Є–Ї–ї–∞–і–љ—Л—Е –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є, –Ї–Њ—В–Њ—А—Л–є –≤—Л–њ–Њ–ї–љ—П–µ—В—Б—П –≤ —А–µ–ґ–Є–Љ–µ user-mode (ring-3). –Ы–Є—И—М –≤ —Н—В–Њ–Љ –і–Є–∞–њ–∞–Ј–Њ–љ–µ (—А–∞–Ј–Љ–µ—А–Њ–Љ 2 –У–±) –Њ–љ –Љ–Њ–ґ–µ—В –≤—Л–і–µ–ї—П—В—М —Б–µ–±–µ —Б—В—А–∞–љ–Є—Ж—Л, –ї–Є—И—М –Ї –љ–Є–Љ –Њ–љ –Љ–Њ–ґ–µ—В –і–µ–ї–∞—В—М –Њ–±—А–∞—Й–µ–љ–Є—П, –њ—А–Є –Ї–Њ—В–Њ—А—Л—Е, —А–∞–Ј—Г–Љ–µ–µ—В—Б—П, –≤—Б—С —А–∞–≤–љ–Њ –њ—А–Њ–≤–µ—А—П—О—В—Б—П –∞—В—А–Є–±—Г—В—Л –Ј–∞—Й–Є—В—Л.
–Ш–љ—В–µ—А–µ—Б–љ—Л–є —Д–∞–Ї—В –љ–∞—Б—З—С—В —Н—В–Њ–≥–Њ —А–∞–Ј–і–µ–ї–µ–љ–Є—П —Б–Њ—Б—В–Њ–Є—В –≤ —В–Њ–Љ, —З—В–Њ –≤–µ—А—Е–љ—П—П –њ–Њ–ї–Њ–≤–Є–љ–∞ –Р–Я –Ї–∞–ґ–і–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞, –љ–µ–≤–Є–і–Є–Љ–∞—П –њ—А–Є–Ї–ї–∞–і–љ–Њ–Љ—Г –Ї–Њ–і—Г, —Г –≤—Б–µ—Е –њ—А–Њ—Ж–µ—Б—Б–Њ–≤ вАФ –Њ–і–Є–љ–∞–Ї–Њ–≤–∞—П. –Ґ–Њ –µ—Б—В—М –µ—Б–ї–Є –±—Л —А–∞–Ј–љ—Л–Љ –њ—А–Њ—Ж–µ—Б—Б–∞–Љ –і–Њ–≤–µ–ї–Њ—Б—М –њ–µ—А–µ–Ї–ї—О—З–Є—В—М—Б—П –≤ —А–µ–ґ–Є–Љ —П–і—А–∞ (–њ–Њ–≤—Л—Б–Є—В—М —Г—А–Њ–≤–µ–љ—М –њ—А–Є–≤–Є–ї–µ–≥–Є–є –і–Њ ring-0), —В–Њ –Ј–∞–≥–ї—П–љ—Г–≤ –≤ –і–Є–∞–њ–∞–Ј–Њ–љ 0x80000000вАФ0xFFFFFFFF –≤—Б–µ —А–∞–Ј–љ—Л–µ –њ—А–Њ—Ж–µ—Б—Б—Г —Г–≤–Є–і–µ–ї–Є –±—Л –Њ–і–љ–Є —В–µ –ґ–µ –і–∞–љ–љ—Л–µ. –Ґ–∞–Љ –±—Л–ї –±—Л –Ї–Њ–і —П–і—А–∞ –Є –і–∞–љ–љ—Л–µ —П–і–µ—А–љ—Л—Е —Б—В—А—Г–Ї—В—Г—А.
–Э–Є–ґ–љ—П—П (–Љ–ї–∞–і—И–∞—П) –њ–Њ–ї–Њ–≤–Є–љ–∞, —В–Њ –µ—Б—В—М –љ–Є–ґ–љ–Є–µ 2 –У–± —Г –Ї–∞–ґ–і–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ вАФ —Б–Њ–±—Б—В–≤–µ–љ–љ–∞—П, –Є–Ј–Њ–ї–Є—А–Њ–≤–∞–љ–љ–∞—П –Њ—В –і—А—Г–≥–Є—Е. –Р —Б—В–∞—А—И–∞—П –њ–Њ–ї–Њ–≤–Є–љ–∞, —Б—В–∞—А—И–Є–µ 2 –У–± —Г –≤—Б–µ—Е –њ—А–Њ—Ж–µ—Б—Б–Њ–≤ вАФ –Њ–±—Й–Є–µ, –љ–Њ –њ—А–Є–Ї–ї–∞–і–љ–Њ–є –Ї–Њ–і, —А–∞–±–Њ—В–∞—О—Й–Є–є –≤ —А–µ–ґ–Є–Љ–µ user-mode –љ–µ –Љ–Њ–ґ–µ—В –Є–Љ–µ—В—М –Ї —Н—В–Њ–є –њ–Њ–ї–Њ–≤–Є–љ–µ –љ–Є–Ї–∞–Ї–Њ–≥–Њ –і–Њ—Б—В—Г–њ–∞ –∞–±—Б–Њ–ї—О—В–љ–Њ.
(–Т –љ–∞—И–µ–є –≥–Њ—Б—В–Є–љ–Є—З–љ–Њ–є –∞–љ–∞–ї–Њ–≥–Є–Є —Н—В–Њ–Љ—Г —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В —В–Њ—В —Д–∞–Ї—В, —З—В–Њ –≤–µ—А—Е–љ–Є–µ —Н—В–∞–ґ–Є –Њ—В–і–∞–љ—Л –њ–µ—А—Б–Њ–љ–∞–ї—Г вАФ –≤ –љ–Є—Е –њ—А–Њ–ґ–Є–≤–∞–µ—В –њ–µ—А—Б–Њ–љ–∞–ї —Б–∞–Љ–Њ–є –≥–Њ—Б—В–Є–љ–Є—Ж—Л –Є –Њ–±—Л—З–љ—Л—Е –Ї–ї–Є–µ–љ—В–Њ–≤ —В—Г–і–∞ –љ–Є–Ї–Њ–≥–і–∞ –љ–µ —Б–µ–ї—П—В)
–Ґ–∞–Ї —З—В–Њ —В—А–Є –≤–∞–ґ–љ—Л—Е —В–µ–Ј–Є—Б–∞:
–Э–µ –≤—Б—С –∞–і—А–µ—Б–љ–Њ–µ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–Њ, –∞ —В–Њ–ї—М–Ї–Њ –µ–≥–Њ —З–∞—Б—В—М (–Њ–±—Л—З–љ–Њ –њ–Њ–ї–Њ–≤–Є–љ–∞ вАФ 2 –У–±) –і–Њ—Б—В—Г–њ–∞ –Ї–Њ–і—Г –њ—А–Є–Ї–ї–∞–і–љ—Л—Е –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є.
–≠—В–Њ –Ї–∞—Б–∞–µ—В—Б—П –∞–±—Б–Њ–ї—О—В–љ–Њ –≤—Б–µ—Е –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є –і–ї—П 32-–±–Є—В–љ–Њ–є Windows, –љ–∞ —З—С–Љ –±—Л –Њ–љ–Є –љ–Є –±—Л–ї–Є –љ–∞–њ–Є—Б–∞–љ—Л, –∞ –љ–µ —В–Њ–ї—М–Ї–Њ VB-—И–љ—Л—Е –њ—А–Њ–≥—А–∞–Љ–Љ.
–°—Г—Й–µ—Б—В–≤—Г–µ—В –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –њ–Њ–ї—Г—З–Є—В—М –і—А—Г–≥—Г—О –њ—А–Њ–њ–Њ—А—Ж–Є—О –і–µ–ї–µ–љ–Є—П.
–Я–Њ—Б–ї–µ–і–љ–µ–µ –Ї–∞—Б–∞–µ—В—Б—П NT-–Њ—Б–љ–Њ–≤–∞–љ–љ—Л—Е —Б–Є—Б—В–µ–Љ. –Т —Д–∞–є–ї–µ boot.ini —Б—Г—Й–µ—Б—В–≤—Г–µ—В —Б–њ–µ—Ж–Є–∞–ї—М–љ—Л–є –Ї–ї—О—З–Є–Ї /3GB. –Х—Б–ї–Є –±–µ–Ј –љ–µ–≥–Њ –њ–Њ —Г–Љ–Њ–ї—З–∞–љ–Є—О –њ–Њ–і —П–і—А–Њ –Њ—В–і–∞—С—В—Б—П 2 –У–±, –∞ –њ—А–Є–Ї–ї–∞–і–љ—Л–Љ –њ—А–Њ—Ж–µ—Б—Б–∞–Љ –і–Њ—Б—В—Г–њ–љ—Л —В–Њ–ї—М–Ї–Њ –љ–Є–ґ–љ–Є–µ 2 –У–±, —В–Њ –њ—А–Є –≤–Ї–ї—О—З–µ–љ–Є–Є —Н—В–Њ–≥–Њ –Ї–ї—О—З–Є–Ї–∞ —П–і—А–Њ –±—Г–і–µ—В —Б—В–Є—Б–Ї–Є–≤–∞—В—М—Б—П –Є –њ–Њ–і –љ–µ–≥–Њ –±—Г–і–µ—В –Њ—В–і–∞–≤–∞—В—М —В–Њ–ї—М–Ї–Њ –≤–µ—А—Е–љ–Є–є 1 –У–± –∞–і—А–µ—Б–љ–Њ–≥–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–∞. –Р –њ—А–Є–Ї–ї–∞–і–љ—Л–Љ –њ—А–Њ–≥—А–∞–Љ–Љ–∞–Љ –±—Г–і–µ—В –і–Њ—Б—В—Г–њ–љ—Л —Г–ґ–µ –љ–µ –Њ—Б—В–∞–≤—И–Є–µ—Б—П 2 –У–±, –∞ –Њ—Б—В–∞–≤—И–Є–µ—Б—П 3 –У–±!
–Ґ–Њ –µ—Б—В—М –µ—Б–ї–Є –Њ–±—Л—З–љ–Њ –і–Є–∞–њ–∞–Ј–Њ–љ –∞–і—А–µ—Б–Њ–≤, —Б –Ї–Њ—В–Њ—А—Л–Љ–Є –Є–Љ–µ–µ—В –і–µ–ї–Њ –њ—А–Є–Ї–ї–∞–і–љ–Њ–є –Ї–Њ–і, —Б–Њ—Б—В–∞–≤–ї—П–µ—В 0x00000000вАФ0x7FFFFFFF, —В–Њ —В–µ–њ–µ—А—М –Њ–љ —А–∞—Б—И–Є—А—П–µ—В—Б—П –і–Њ 0x00000000вАФ0xBFFFFFFF). –І–∞—Б—В—М –∞–і—А–µ—Б–Њ–≤ (0x80000000вАФ0xBF000000) –≤ –Ј–љ–∞–Ї–Њ–≤–Њ–Љ –њ—А–µ–і—Б—В–∞–≤–ї–µ–љ–Є–Є —З–Є—Б–µ–ї –њ–Њ–ї—Г—З–∞–µ—В—Б—П –Њ—В—А–Є—Ж–∞—В–µ–ї—М–љ–Њ–є. –Э–µ –≤—Б–µ –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П –љ–∞–њ–Є—Б–∞–љ—Л —В–∞–Ї, —З—В–Њ –Љ–Њ–≥—Г—В –Ї–Њ—А—А–µ–Ї—В–љ–Њ –њ–µ—А–µ–≤–∞—А–Є–≤–∞—В—М –Њ—В—А–Є—Ж–∞—В–µ–ї—М–љ—Л–µ –∞–і—А–µ—Б–∞. –Я–Њ—Н—В–Њ—Г –і–∞–ґ–µ –њ—А–Є –≤–Ї–ї—О—З–µ–љ–Є–Є —А–µ–ґ–Є–Љ–∞ /3GB Windows –±—Г–і–µ—В –≤—Л–і–µ–ї—П—В—М –њ–∞–Љ—П—В—М —В–Њ–ї—М–Ї–Њ –Є—Е –њ–µ—А–≤—Л—Е 2 –У–± –∞–і—А–µ—Б–љ–Њ–≥–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–∞, –µ—Б–ї–Є —В–Њ–ї—М–Ї–Њ —Б–∞–Љ–Њ –њ—А–Є–ї–Њ–ґ–µ–љ–Є–µ –љ–µ –Є–Љ–µ–µ—В —Д–ї–∞–≥, –≥–Њ–≤–Њ—А—П—Й–Є–є, —З—В–Њ –Њ–љ–Њ —Б–Њ–≤–Љ–µ—Б—В–Є–Љ–Њ —Б —А–µ–ґ–Є–Љ–Њ–Љ 3GB. –Х—Б–ї–Є —Д–ї–∞–≥ –µ—Б—В—М, —В–Њ–≥–і–∞ –њ—А–Є–Ї–ї–∞–і–љ–Њ–Љ—Г –њ—А–Є–ї–Њ–ґ–µ–љ–Є—О —Б—В–∞–љ–Њ–≤—П—В—Б—П –і–Њ—Б—В—Г–њ–љ—Л –≤—Б–µ 3 –У–± –∞–і—А–µ—Б–љ–Њ–≥–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–∞.
–Я–µ—З–∞–ї—М–љ—Л–є —Д–∞–Ї—В –Њ—В–љ–Њ—Б–Є—В–µ–ї—М–љ–Њ —А–µ–ґ–Є–Љ–∞ /3GB —Б–Њ—Б—В–Њ–Є—В –≤ —В–Њ–Љ, —З—В–Њ –µ—Б—В—М –≤–µ—А–Њ—П—В–љ–Њ—Б—В—М, —З—В–Њ –Ї–Њ–і —П–і—А–∞, –Ї–Њ–і –≤—Б–µ—Е –і—А–∞–є–≤–µ—А–Њ–≤ –Є –≤—Б–µ —П–і–µ—А–љ—Л–µ –і–∞–љ–љ—Л–µ –њ—А–Њ—Б—В–Њ –љ–µ —Б–Љ–Њ–≥—Г—В —Г–ґ–∞—В—М—Б—П –і–Њ —А–∞–Ј–Љ–µ—А–∞ 1 –У–±. –Т —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ —Б–Є—Б—В–µ–Љ–∞ –њ—А–Њ—Б—В–Њ –љ–µ –Ј–∞–≥—Г–Ј–Є—В—Б—П –Ї–Њ—А—А–µ–Ї—В–љ–Њ. –≠—В–Њ –Њ—Б–Њ–±–µ–љ–љ–Њ –∞–Ї—В—Г–∞–ї—М–љ–Њ –і–ї—П –љ–Њ–≤—Л—Е –і—А–∞–є–≤–µ—А–Њ–≤, –Ї–Њ—В–Њ—А—Л–µ –њ–Є—И—Г—В –Ї—А–µ—В–Є–љ—Л, –љ–µ –ґ–∞–ї–µ—О—Й–Є–µ –њ–∞–Љ—П—В–Є.
_______________
–Ґ—А–µ—В–Є–є –Љ–Њ–Љ–µ–љ—В –Ј–∞–Ї–ї—О—З–∞–µ—В—Б—П –≤ —В–Њ–Љ, —З—В–Њ –≤ —А–∞–Љ–Ї–∞—Е –±–Њ—А—М–±—Л —Б –љ—Г–ї–µ–≤—Л–Љ–Є —Г–Ї–∞–Ј–∞—В–µ–ї—П–Љ–Є, –њ–µ—А–≤—Л–µ (–Љ–ї–∞–і—И–Є–µ) 64 –Ї–± –∞–і—А–µ—Б–љ–Њ–≥–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–∞ –љ–Є–Ї–Њ–≥–і–∞ –љ–Є –њ–Њ–і–Њ —З—В–Њ –љ–µ –Є—Б–њ–Њ–ї—М–Ј—Г—О—В—Б—П. –°—В—А–∞–љ–Є—Ж—Л –≤ —Н—В–Њ–Љ —А–µ–≥–Є–Њ–љ–µ –љ–µ –≤—Л–і–µ–ї—П—О—В—Б—П, —Б–њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞—В—М —В—Г–і–∞ –Ї–∞–Ї–Њ–є-—В–Њ —Д–∞–є–ї —В–Њ–ґ–µ –љ–µ–ї—М–Ј—П. –Ю–±—А–∞—Й–µ–љ–Є—П –Ї —Н—В–Њ–Љ—Г —А–µ–≥–Є–Њ–љ—Г –≤—Б–µ–≥–і–∞ –≤—Л–Ј—Л–≤–∞—О—В –Є—Б–Ї–ї—О—З–µ–љ–Є–µ.
(–Ґ–Њ –µ—Б—В—М, –њ—А–Њ–і–Њ–ї–ґ–∞—П –∞–љ–∞–ї–Њ–≥–Є—О, –≤ –Ї–Њ–Љ–љ–∞—В—Г –њ–Њ–і –љ–Њ–Љ–µ—А–Њ–Љ 1 –љ–Є–Ї–Њ–≥–і–∞ –љ–Є–Ї–Њ–≥–Њ –љ–µ —Б–µ–ї—П—В)
________________
–Ґ–∞–Ї —З—В–Њ –ґ–µ —Г –љ–∞—Б –Њ—Б—В–∞—С—В—Б—П?
–Я—А–Њ—Ж–µ—Б—Б –Є–Љ–µ–µ—В –Р–Я —А–∞–Ј–Љ–µ—А–Њ–Љ 4 –У–±.
–Я—А–Є —Н—В–Њ–Љ –њ—А–Є–Ї–ї–∞–і–љ–Њ–Љ—Г –і–Њ—Б—В—Г–њ–љ–∞ —В–Њ–ї—М–Ї–Њ –љ–Є–ґ–љ—П—П —З–∞—Б—В—М —А–∞–Ј–Љ–µ—А–Њ–Љ 2 –У–± (–µ—Б–ї–Є —В–Њ–ї—М–Ї–Њ –љ–µ –≤–Ї–ї—О—З–µ–љ —А–µ–ґ–Є–Љ /3GB –Є —Г –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П –љ–µ—В —Б–њ–µ—Ж. —Д–ї–∞–≥–∞).
–Ш–Ј —Н—В–Њ–≥–Њ 2 –У–± –Ј–∞–≤–µ–і–Њ–Љ–Њ –љ–µ–і–Њ—Б—В—Г–њ–љ—Л–Љ —П–≤–ї—П–µ—В—Б—П –Љ–ї–∞–і—И–Є–є —Д—А–∞–≥–Љ–µ–љ—В —А–∞–Ј–Љ–µ—А–Њ–Љ 64 –Ъ–±.
–Ю—Б—В–∞–≤—И–∞—П—Б—П —З–∞—Б—В—М –Р–Я —П–≤–ї—П–µ—В—Б—П —В–µ–Њ—А–µ—В–Є—З–µ—Б–Ї–Є –і–Њ—Б—В—Г–њ–љ–Њ–є.
–І—В–Њ –ґ–µ –Њ–≥—А–∞–љ–Є—З–Є–≤–∞–µ—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –і–∞–ї—М–љ–µ–є—И–µ–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –њ–Њ—В–µ–љ—Ж–Є–∞–ї—М–љ–Њ-–і–Њ—Б—В—Г–њ–љ–Њ–є —З–∞—Б—В–Є –Р–Я —А–∞–Ј–Љ–µ—А–Њ–Љ –≤ 2 –У–± –Љ–Є–љ—Г—Б 64 –Ї–±?
–І—В–Њ –љ–µ –і–∞—С—В –љ–∞–Љ –≤—Л–і–µ–ї–Є—В—М –Ї–≤–∞–і—А–∞—В–љ—Л–є –Љ–∞—Б—Б–Є–≤ —Б 46000√Ч46000 —П—З–µ–µ–Ї (–Ї–≤–∞–і—А–∞—В–љ—Л–є –Ї–Њ—А–µ–љ—М –Є–Ј 2147483648)?
–Т–Њ-–њ–µ—А–≤—Л—Е, 2 –У–± –Љ–Є–љ—Г—Б 64 –Ї–± вАФ —Н—В–Њ —В–Њ–ї—М–Ї–Њ —А–∞–Ј–Љ–µ—А —Б–∞–Љ–Њ–≥–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–∞ –∞–і—А–µ—Б–Њ–≤. –Ъ–Њ–ї–Є—З–µ—Б—В–≤–Њ —Б—В—А–∞–љ–Є—Ж –љ–Њ–≤—Л—Е (–њ—Г—Б—В—Л—Е), –Ї–Њ—В–Њ—А—Л–µ –Љ–Њ–≥—Г—В –±—Л—В—М –≤—Л–і–µ–ї–µ–љ—Л
–≤—Б–µ–Љ –њ—А–Њ—Ж–µ—Б—Б–∞–Љ –≤–Љ–µ—Б—В–µ –≤–Ј—П—В—Л–Љ –Њ–≥—А–∞–љ–Є—З–µ–љ–Њ —А–∞–Ј–Љ–µ—А–Њ–Љ —Д–∞–є–ї–∞ –њ–Њ–і–Ї–∞—З–Ї–Є. –Х—Б–ї–Є —Г –љ–∞—Б —Д–∞–є–ї –њ–Њ–і–Ї–∞—З–Ї–Є –Є–Љ–µ–µ—В —А–∞–Ј–Љ–µ—А 1 –У–±, —В–Њ –і–∞–ґ–µ –Њ–і–Є–љ –µ–і–Є–љ—Б—В–≤–µ–љ–љ—Л–є –њ—А–Њ—Ж–µ—Б—Б –љ–Є–Ї–Њ–≥–і–∞ –љ–µ —Б–Љ–Њ–ґ–µ—В –≤—Л–і–µ–ї–Є—В—М –њ–∞–Љ—П—В—М –њ–Њ–і –Љ–∞—Б—Б–Є–≤ —А–∞–Ј–Љ–µ—А–Њ–Љ 1.5 –У–±. –Х—Б–ї–Є —Г –љ–∞—Б —Д–∞–є–ї –њ–Њ–і–Ї–∞—З–Ї–Є –±—Г–і–µ—В –Є–Љ–µ—В—М —А–∞–Ј–Љ–µ—А 6 –У–±, –≤—Б—С —А–∞–≤–љ–Њ –µ—Б—В—М —И–∞–љ—Б, —З—В–Њ –Љ—Л –љ–µ —Б–Љ–Њ–ґ–µ–Љ –≤—Л–і–µ–ї–Є—В—М –Љ–∞—Б—Б–Є–≤ —А–∞–Ј–Љ–µ—А–Њ–Љ –і–∞–ґ–µ 500 –Ь–±, –µ—Б–ї–Є –Њ—Б—В–∞–ї—М–љ—Л–µ 40 –њ—А–Њ—Ж–µ—Б—Б–Њ–≤ –≤ —Б—Г–Љ–Љ–µ –њ–Њ—В—А–µ–±–ї—П—О—В 5,8 –У–± —Д–∞–є–ї–∞ –њ–Њ–і–Ї–∞—З–Ї–Є.
–†–∞–Ј–Љ–µ—А —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є –Ј–і–µ—Б—М –њ—А–∞–Ї—В–Є—З–µ—Б–Ї–Є –љ–µ –Є–≥—А–∞–µ—В –љ–Є–Ї–∞–Ї–Њ–є —А–Њ–ї–Є. –Ю–љ –≤–ї–Є—П–µ—В —В–Њ–ї—М–Ї–Њ –љ–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М.
–Ґ–∞–Ї —З—В–Њ –Њ–і–љ–∞ –Є–Ј –њ—А–Є—З–Є–љ, –њ–Њ—З–µ–Љ—Г –љ–µ –њ–Њ–ї—Г—З–∞–µ—В—Б—П –≤—Л–і–µ–ї–Є—В—М –њ–∞–Љ—П—В—М –њ–Њ–і –Љ–∞—Б—Б–Є–≤ –ґ–µ–ї–∞–µ–Љ–Њ–≥–Њ —А–∞–Ј–Љ–µ—А–∞ вАФ –љ–µ—В —Б–≤–Њ–±–Њ–і–љ—Л—Е —Б—В—А–∞–љ–Є—Ж –≤ —Д–∞–є–ї–µ –њ–Њ–і–Ї–∞—З–Ї–Є. –Э—Г–ґ–љ–Њ –ї–Є–±–Њ —Г–Љ–µ–љ—М—И–Є—В—М —А–∞–Ј–Љ–µ—А —Д–∞–є–ї–∞ –њ–Њ–і–Ї–∞—З–Ї–Є, –ї–Є–±–Њ –Ј–∞–≤–µ—А—И–Є—В—М –і—А—Г–≥–Є–µ –њ—А–Њ—Ж–µ—Б—Б—Л.
_____________
–Ф—А—Г–≥–∞—П, –≥–Њ—А–∞–Ј–і–Њ –±–Њ–ї–µ–µ —Б–µ—А—М—С–Ј–љ–∞—П, –љ–µ—А–∞–Ј—А–µ—И–Є–Љ–∞—П –Є –і—А–∞–Љ–∞—В–Є—З–љ–∞—П –њ—А–Є—З–Є–љ–∞ вАФ —Н—В–Њ —Д—А–∞–≥–Љ–µ–љ—В–∞—Ж–Є—П –Р–Я.
–Я—Г—Б—В—М –і–∞–ґ–µ —Г –љ–∞—Б —Д–∞–є–ї –њ–Њ–і–Ї–∞—З–Ї–Є –Є–Љ–µ–µ—В –Ї–Њ–ї–Њ—Б—Б–∞–ї—М–љ—Л–є –љ–µ–Є—Б—З–µ—А–њ–∞–µ–Љ—Л–є —А–∞–Ј–Љ–µ—А. –Я—Г—Б—В—М —Г –љ–∞—Б —Д–Є–Ј.–њ–∞–Љ—П—В—М –Њ–≥—А–Њ–Љ–љ–Њ–≥–Њ —А–∞–Ј–Љ–µ—А–∞.
–Т—Б—С —А–∞–≤–љ–Њ –Р–Я –њ—А–Њ—Ж–µ—Б—Б–∞ –Є–Љ–µ–µ—В —А–∞–Ј–Љ–µ—А 4 –У–±.
–Т—Б—С —А–∞–≤–љ–Њ —В–Њ–ї—М–Ї–Њ –Љ–ї–∞–і—И–Є–µ 2 –У–± (–Є–ї–Є 3 –У–±) –і–Њ—Б—В—Г–њ–љ—Л –њ—А–Є–Ї–ї–∞–і–љ–Њ–Љ—Г –њ—А–Њ—Ж–µ—Б—Б—Г.
–Я—А–µ–і—Б—В–∞–≤–Є–Љ —Б–µ–±–µ —З–∞—Б—В—М –Р–Я —А–∞–Ј–Љ–µ—А–Њ–Љ 2 –У–±. –Я—Г—Б—В—М –Њ–љ–∞ –Є–Ј–љ–∞—З–∞–ї—М–љ–Њ –љ–Є—З–µ–Љ –љ–µ –Ј–∞–љ—П—В–∞.
–Ш –≤–Њ—В –Ї–∞–Ї–Њ–є-—В–Њ –Ї–Њ–і –≤—Л–і–µ–ї–Є–ї —Б–µ–±–µ –≤—Б–µ–≥–Њ-–ї–Є—И—М –Њ–і–љ—Г –µ–і–Є–љ—Б—В–≤–µ–љ–љ—Г—О —Б—В—А–∞–љ–Є—Ж—Г —А–∞–Ј–Љ–µ—А–Њ–Љ 4 –Ї–± –Є–Ј —Б–µ—А–µ–і–Є–љ—Л —Н—В–Њ–≥–Њ –Р–Я. –≠—В–∞ –Њ–і–љ–∞ –µ–і–Є–љ—Б—В–≤–µ–љ–љ–∞—П –Ї—А–Њ—Е–Њ—В–љ–∞—П —Б—В—А–∞–љ–Є—Ж–∞ —А–∞–Ј–±–Є–≤–∞–µ—В (—Д—А–∞–≥–Љ–µ–љ—В–Є—А—Г–µ—В) –±–Њ–ї—М—И–Њ–µ –і–≤—Г—Е–≥–Є–≥–∞–±–∞–є—В–љ–Њ–µ –Р–Я –љ–∞ –і–≤–µ —З–∞—Б—В–Є.
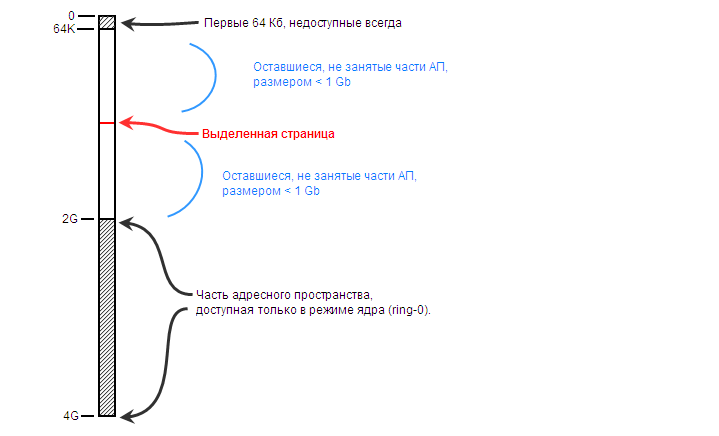
–Ґ–µ–њ–µ—А—М —Г–ґ–µ –љ–µ–≤–Њ–Ј–Љ–Њ–ґ–љ–Њ –≤—Л–і–µ–ї–Є—В—М –љ–Є 2 –≥–Є–≥–∞–±–∞–є—В–∞, –љ–Є 1.5 –≥–Є–≥–∞–±–∞–є—В–∞. –Э–µ—Б–Љ–Њ—В—А—П –љ–∞ —В–Њ, —З—В–Њ —Д–∞–є–ї –њ–Њ–і–Ї–∞—З–Ї–Є –њ–Њ–Ј–≤–Њ–ї—П–µ—В, –Є —Д–Є–Ј. –њ–∞–Љ—П—В—М –њ–Њ–Ј–≤–Њ–ї—П–µ—В. –Р–Я —Д—А–∞–≥–Љ–µ–љ—В–Є—А–Њ–≤–∞–љ–Њ, —А–∞–Ј–±–Є—В–Њ –њ–Њ–њ–Њ–ї–∞–Љ, –Є –Љ–Њ–ґ–љ–Њ —В–µ–њ–µ—А—М –≤—Л–і–µ–ї–Є—В—М —В–Њ–ї—М–Ї–Њ –і–≤–∞ –Ї—Г—Б–Њ—З–Ї–∞ –њ–Њ 0.9 –У–± (–≥—А—Г–±–Њ –≥–Њ–≤–Њ—А—П).
(–У–Њ—Б—В–Є–љ–Є—З–љ–∞—П –∞–љ–∞–ї–Њ–≥–Є—П: –≤—Л –њ—А–Є–µ—Е–∞–ї–Є –±–Њ–ї—М—И–Њ–є –≥—Г—А—М–±–Њ–є –Є –љ–∞–Љ–µ—А–µ–љ—Л –Ј–∞—Б–µ–ї–Є—В—М –≤—Б–µ –њ–Њ–і—А—П–і –љ–Њ–Љ–µ—А–∞ —Б 21-–≥–Њ –њ–Њ 50-—Л–є вАФ –≤—Б–µ–≥–Њ 30 –љ–Њ–Љ–µ—А–Њ–≤. –Т –≥–Њ—Б—В–Є–љ–Є—Ж–µ —Б–µ–є—З–∞—Б –µ—Б—В—М 80 —Б–≤–Њ–±–Њ–і–љ—Л—Е –љ–Њ–Љ–µ—А–Њ–≤, –љ–∞ —Б–Ї–ї–∞–і–µ –Њ—Б—В–∞–ї–Њ—Б—М 150 –Ї–Њ–Љ–њ–ї–µ–Ї—В–Њ–≤ –њ–Њ—Б—В–µ–ї—М–љ–Њ–≥–Њ –±–µ–ї—М—П, –љ–Њ –≤–∞–Љ –Њ—В–Ї–∞–ґ—Г—В, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –љ–Њ–Љ–µ—А 37 —Г–ґ–µ –Ј–∞—Б–µ–ї—С–љ, –∞ –≤—Л –Ј–∞—В—А–µ–±–Њ–≤–∞–ї–Є –љ–µ–њ—А–µ—А—Л–≤–љ—Л–є –і–Є–∞–њ–∞–Ј–Њ–љ –љ–Њ–Љ–µ—А–Њ–≤. –С–Њ–ї–µ–µ —В–Њ–≥–Њ, –Љ–Њ–ґ–µ—В —В–∞–Ї –Њ–Ї–∞–Ј–∞—В—М—Б—П, —З—В–Њ –≤ 100-–Љ–µ—Б—В–љ–Њ–є –≥–Њ—Б—В–Є–љ–Є—Ж–µ –µ—Б—В—М 5 —Н—В–∞–ґ–µ–є –њ–Њ 20 –Ї–Њ–Љ–љ–∞—В –љ–∞ –Ї–∞–ґ–і–Њ–Љ —Н—В–∞–ґ–µ. –Т—Л –њ—А–Є–µ—Е–∞–ї–Є –±–Њ–ї—М—И–Є–Љ –Ї–Њ–ї–ї–µ–Ї—В–Є–≤–Њ–Љ (–Ї–∞–Ї —А–∞–Ј 20 —З–µ–ї–Њ–≤–µ–Ї) –Є —В—А–µ–±—Г–µ—В–µ, —З—В–Њ–±—Л –≤–∞—Б –≤—Б–µ—Е –Ј–∞—Б–µ–ї–Є–ї –љ–∞ –Њ–і–Є–љ —Н—В–∞–ґ вАФ –≤–∞–Љ –љ–µ –њ—А–Є–љ—Ж–Є–њ–Є–∞–ї—М–љ–Њ –љ–∞ –Ї–∞–Ї–Њ–є, –≥–ї–∞–≤–љ–Њ–µ, —З—В–Њ–±—Л –≤—Б–µ –ґ–Є–ї–Є –љ–∞ –Њ–і–љ–Њ–Љ –Є —В–Њ–Љ –ґ–µ. –Э–Њ –≤–∞–Љ –Њ–Ї–∞–ґ—Г—В: –Њ–Ї–∞–Ј—Л–≤–∞–µ—В—Б—П, —З—В–Њ –љ–∞ –Ї–∞–ґ–і–Њ–Љ —Н—В–∞–ґ–µ –Ј–∞—Б–µ–ї—С–љ —В–Њ–ї—М–Ї–Њ –Њ–і–Є–љ –љ–Њ–Љ–µ—А. –Т 100-–Љ–µ—Б—В–љ–Њ–є –≥–Њ—Б—В–Є–љ–Є—Ж–µ –ґ–Є–≤—С—В 5 —З–µ–ї–Њ–≤–µ–Ї (–њ–Њ –Њ–і–љ–Њ–Љ—Г —З–µ–ї–Њ–≤–µ–Ї—Г –љ–∞ —Н—В–∞–ґ). 95% –љ–Њ–Љ–µ—А–Њ–≤ –њ—А–Њ—Б—В–∞–Є–≤–∞–µ—В. –Э–Њ –≤–∞–Љ –Њ—В–Ї–∞–ґ—Г—В, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –љ–µ—В –љ–Є –Њ–і–љ–Њ–≥–Њ –њ–Њ–ї–љ–Њ—Б—В—М—О —Б–≤–Њ–±–Њ–і–љ–Њ–≥–Њ —Н—В–∞–ґ–∞, –∞ –≤—Л —В—А–µ–±—Г–µ—В–µ –Є–Љ–µ–љ–љ–Њ —Н—В–Њ–≥–Њ. –•–Њ—В—П –Є –њ–Њ—Б—В–µ–ї—М–љ–Њ–≥–Њ –±–µ–ї—М—П –љ–∞ —Б–Ї–ї–∞–і–µ –љ–∞–≤–∞–ї–Њ–Љ, –Є 95 –љ–Њ–Љ–µ—А–Њ–≤ –љ–µ –Ј–∞—Б–µ–ї–µ–љ—Л. –Э–Њ –і–Є–∞–њ–∞–Ј–Њ–љ —Д—А–∞–≥–Љ–µ–љ—В–Є—А–Њ–≤–∞–љ —В–µ–Љ–Є —Б–ї—Г—З–∞–є–љ—Л–Љ–Є –Ј–∞—Б–µ–ї–µ–љ—Ж–∞–Љ–Є, —З—В–Њ –µ—Б—В—М –љ–∞ –Ї–∞–ґ–і–Њ–Љ —Н—В–∞–ґ–µ, –Є —Н—В–Њ –љ–µ –і–∞—С—В –≤–∞–Љ –≤–Њ—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М—Б—П –њ–Њ—З—В–Є –њ—Г—Б—В–Њ–є –≥–Њ—Б—В–Є–љ–Є—Ж–µ–є).
–≠—В–Њ –љ–∞–і—Г–Љ–∞–љ–љ—Л–є –њ—А–Є–Љ–µ—А.
–Т —А–µ–∞–ї—М–љ–Њ–є –ґ–Є–Ј–љ–Є —Б—А–∞–Ј—Г –ґ–µ –њ–Њ—Б–ї–µ –Ј–∞–њ—Г—Б–Ї–∞ –Є –Ј–∞–≥—А—Г–Ј–Ї–Є –њ—А–Њ—Ж–µ—Б—Б–∞, —Д—А–∞–≥–Љ–µ–љ—В–Є—А–Њ–≤–∞–љ–љ–Њ—Б—В—М –µ–≥–Њ –Р–Я –і–∞—С—В –Ї—Г–і–∞ —Е—Г–і—И—Г—О –Ї–∞—А—В–Є–љ—Г. –Ґ–Њ –µ—Б—В—М –Њ–љ–∞ –≥–Њ—А–∞–Ј–і–Њ –±–Њ–ї–µ–µ —Д—А–∞–≥–Љ–µ–љ—В–Є—А–Њ–≤–∞–љ–Њ, –љ–µ–ґ–µ–ї–Є —З–µ–Љ –љ–∞ –і–≤–∞ —Д—А–∞–≥–Љ–µ–љ—В–∞ –Њ–і–љ–Њ–є –µ–і–Є–љ—Б—В–≤–µ–љ–љ–Њ–є —Б—В—А–∞–љ–Є—З–Ї–Њ–є, –Ї–∞–Ї –љ–∞ –Ї–∞—А—В–Є–љ–Ї–µ –≤—Л—И–µ.
–І–µ–Љ —Д—А–∞–≥–Љ–µ–љ—В–Є—А—Г–µ—В—Б—П –Р–Я –њ—А–Њ—Ж–µ—Б—Б–∞?
–Т–Њ-–њ–µ—А–≤—Л—Е, –µ—Й—С –њ—А–Є —Б–Њ–Ј–і–∞–љ–Є–Є –Є –Ј–∞–≥—А—Г–Ј–Ї–Є –њ—А–Њ—Ж–µ—Б—Б–∞, –≤ –љ–µ–≥–Њ –њ—А–Њ–µ—Ж–Є—А—Г—О—В—Б—П –≤—Б–µ –Є—Б–њ–Њ–ї—М–Ј—Г—О—Й–Є–µ—Б—П –Є—Б–њ–Њ–ї–љ—П–µ–Љ—Л–µ —Д–∞–є–ї—Л. –Ґ–Њ –µ—Б—В—М –њ—А—П–Љ–Њ –≤ –Р–Я –њ—А–Њ—Ж–µ—Б—Б–∞ –њ—А–Њ–µ—Ж–Є—А—Г–µ—В—Б—П –≥–ї–∞–≤–љ—Л–є EXE-—Д–∞–є–ї, –≤—Б–µ –Є—Б–њ–Њ–ї—М–Ј—Г–Љ—Л–µ –Є–Љ —Б–Є—Б—В–µ–Љ–љ—Л–µ –±–Є–±–ї–Є–Њ—В–µ–Ї–Є (DLL), –Є –љ–µ —В–Њ–ї—М–Ї–Њ —Б–Є—Б—В–µ–Љ–љ—Л–µ, –≤—Б–µ –Ї–Њ–Љ–њ–Њ–љ–µ–љ—В—Л. –Р–і—А–µ—Б–∞, –њ–Њ –Ї–Њ—В–Њ—А—Л–Љ –њ—А–Њ–µ—Ж–Є—А—Г—О—В—Б—П –Є—Б–њ–Њ–ї–љ—П–µ–Љ—Л–µ —Д–∞–є–ї—Л, –Ј–∞–≤–Є—Б—П—В –Њ—В –≤—И–Є—В—Л—Е –≤ —Б–∞–Љ–Є —Д–∞–є–ї–∞ –Ј–љ–∞—З–µ–љ–Є–є –±–∞–Ј–Њ–≤—Л—Е –∞–і—А–µ—Б–Њ–≤.
–Ш–љ—Л–Љ–Є —Б–ї–Њ–≤–∞–Љ–Є, –Ї–∞–ґ–і—Л–є –Є—Б–њ–Њ–ї–љ—П–µ–Љ—Л–є —Д–∞–є–ї —Б–∞–Љ —А–µ—И–∞–µ—В, –Ї—Г–і–∞ –Њ–љ –±—Г–і–µ—В —Б–њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞–љ. –Я–Њ –Ї—А–∞–є–љ–µ–є –Љ–µ—А–µ —Б–Є—Б—В–µ–Љ–љ—Л–µ –±–Є–±–ї–Є–Њ—В–µ–Ї–Є –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞–љ—Л –≤ —Н—В–Њ–Љ –њ–ї–∞–љ–µ —В–∞–Ї, —З—В–Њ –њ—А–Є –њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞–љ–Є–Є –Њ–Ї–∞–Ј—Л–≤–∞—О—В—Б—П –±–ї–Є–Ј–Ї–Њ –і—А—Г–≥ –Ї –і—А—Г–≥—Г –≤ –Њ–±–ї–∞—Б—В–Є –±–ї–Є–ґ–µ –Ї –Ї–Њ–љ—Ж—Г –і–≤—Г—Е–≥–Є–≥–∞–±–∞–є—В–Њ–≤–Њ–≥–Њ –Ї—Г—Б–Ї–∞ –Р–Я. –≠—В–Њ –і–∞—С—В –Љ–µ–љ—М—И—Г—О —Д—А–∞–≥–Љ–µ–љ—В–∞—Ж–Є—О. –°–∞–Љ –њ–Њ —Б–µ–±–µ EXE –Њ–±—Л—З–љ–Њ –њ—А–Њ–µ—Ж–Є—А—Г–µ—В—Б—П –њ–Њ –∞–і—А–µ—Б—Г 0x00400000. –Ф–ї—П —Б–Њ–±—Б—В–≤–µ–љ–љ–Њ–≥–Њ EXE –Є —Б–Њ–±—Б—В–≤–µ–љ–љ—Л—Е –±–Є–±–ї–Є–Њ—В–µ–Ї —Н—В–Є –∞–і—А–µ—Б–∞ –Љ–Њ–ґ–љ–Њ –њ–µ—А–µ–Њ–њ—А–µ–і–µ–ї–Є—В—М. –Ъ—А–Њ–Љ–µ —В–Њ–≥–Њ, –µ—Б–ї–Є –љ–∞ –Љ–Њ–Љ–µ–љ—В –Ј–∞–≥—А—Г–Ј–Ї–Є –±–Є–±–ї–Є–Њ—В–µ–Ї–Є –њ–Њ –љ—Г–ґ–љ–Њ–Љ—Г –∞–і—А–µ—Б—Г —Г–ґ–µ —З—В–Њ-—В–Њ —Е—А–∞–љ–Є—В—Б—П, –Є –њ—А–Є —Н—В–Њ–Љ –±–Є–±–ї–Є–Њ—В–µ–Ї–∞ –љ–µ —А–µ—И–µ–љ–∞ —Б–µ–Ї—Ж–Є–Є —А–µ–ї–Њ–Ї–Њ–≤, —В–Њ –±–Є–±–ї–Є–Њ—В–µ–Ї–∞ –Љ–Њ–ґ–µ—В –±—Л—В—М –Ј–∞–≥—А—Г–ґ–µ–љ–∞ (—Б–њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞–љ–∞) –њ–Њ –і—А—Г–≥–Њ–Љ—Г –Љ–µ—Б—В–Њ–њ–Њ–ї–Њ–ґ–µ–љ–Є—О. –С–Њ–ї–µ–µ —В–Њ–≥–Њ, –љ–∞ –њ–Њ—Б–ї–µ–і–љ–Є—Е –Ю–° (Vista, Win7 –Є —В–∞–Ї –і–∞–ї–µ–µ) –µ—Б—В—М —В–µ—Е–љ–Њ–ї–Њ–≥–Є—П ASLR (address-space layout randomization вАФ —А–∞–љ–і–Њ–Љ–Є–Ј–∞—Ж–Є—П –∞–і—А–µ—Б–љ–Њ–≥–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–∞), –њ—А–Є –Ї–Њ—В–Њ—А–Њ–є –Є—Б–њ–Њ–ї–љ—П–µ–Љ—Л–µ —Д–∞–є–ї—Л –±—Г–і—Г—В –њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞—В—М—Б—П –≤ –±–Њ–ї–µ–µ-–Љ–µ–љ–µ–µ —Б–ї—Г—З–∞–є–љ—Л–µ –Љ–µ—Б—В–∞ –Р–Я.
–Т–Њ-–≤—В–Њ—А—Л—Е, –≤ –Р–Я –њ—А–Њ–µ—Ж–Є—А—Г–µ—В—Б—П —А—П–і —Б–Є—Б—В–µ–Љ–љ—Л—Е –і–∞–љ–љ—Л—Е (–љ–∞–њ—А–Є–Љ–µ—А NLS-–±–ї–Њ–Ї–Є), –љ–Њ —Н—В–Њ –њ—А–Њ–Є—Б—Е–Њ–і –њ–Њ –Љ–ї–∞–і—И–Є–Љ –∞–і—А–µ—Б–∞–Љ–Є.
–Т-—В—А–µ—В—М–Є—Е, –Р–Я —Д—А–∞–≥–Љ–µ–љ—В–Є—А—Г–µ—В—Б—П —Б—В–µ–Ї–∞–Љ–Є –њ–Њ—В–Њ–Ї–Њ–≤. –Ф–ї—П –Ї–∞–ґ–і–Њ–≥–Њ –њ–Њ—В–Њ–Ї–∞ —А–µ–Ј–µ—А–≤–Є—А—Г–µ—В—Б—П –Љ–µ—Б—В–Њ –њ–Њ–і –µ–≥–Њ —Б—В–µ–Ї. –†–∞–Ј–Љ–µ—А —А–µ–Ј–µ—А–≤–Є—А—Г–µ–Љ–Њ–є —З–∞—Б—В–Є –Љ–Њ–ґ–љ–Њ –њ–µ—А–µ–Њ–њ—А–µ–і–µ–ї–Є—В—М.
–Т-—З–µ—В–≤—С—А—В—Л—Е, –Р–Я —Д—А–∞–≥–Љ–µ–љ—В–Є—А—Г–µ—В—Б—П TIB-–±–ї–Њ–Ї–∞–Љ–Є –њ–Њ–і –Ї–∞–ґ–і—Л–є –њ–Њ—В–Њ–Ї. –Т–њ—А–Њ—З–µ–Љ, –Є –Є—Е —Б–Є—Б—В–µ–Љ–∞ —Б—В–∞—А–∞–µ—В—Б—П —А–∞–Ј–Љ–µ—Й–∞—В—М –±–ї–Є–ґ–µ –Ї –Ї–Њ–љ—Ж—Г –і–≤—Г—Е–≥–Є–≥–∞–±–∞–є—В–љ–Њ–≥–Њ –Ї—Г—Б–Ї–∞, –і–Њ—Б—В—Г–њ–љ–Њ–≥–Њ –њ—А–Є–Ї–ї–∞–і–љ—Л–Љ –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П–Љ.
–Э—Г –Є —Б–∞–Љ–Њ–µ –≥–ї–∞–≤–љ–Њ–µ: –њ–Њ —Е–Њ–і—Г —Б–≤–Њ–µ–є —А–∞–±–Њ—В—Л –њ—А–Є–ї–Њ–ґ–µ–љ–Є–µ –∞–Ї—В–Є–≤–љ–Њ –≤—Л–і–µ–ї—П–µ—В –і–ї—П —Б–µ–±—П –њ–∞–Љ—П—В—М (–Є—Б–њ–Њ–ї—М–Ј—Г—П —А–∞–Ј–љ—Л–µ –Љ–µ—Е–∞–љ–Є–Ј–Љ—Л), –Љ–Њ–ґ–µ—В –±—Л—В—М, —З—В–Њ-—В–Њ –њ—А–Њ–µ—Ж–Є—А—Г–µ—В –≤ —Б–≤–Њ—С –Р–Я, –Є —В–µ–Љ —Б–∞–Љ—Л–Љ –≤–љ–Њ—Б–Є—В –љ–∞–Є–±–Њ–ї—М—И—Г—О —Д—А–∞–≥–Љ–µ–љ—В–∞—Ж–Є—О –≤ ¬Ђ—А–∞—Б–Ї—А–Њ–є¬ї –∞–і—А–µ—Б–љ–Њ–≥–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–Њ.
–Ю—В—Б—О–і–∞ –Є —Б–ї–µ–і—Г–µ—В, —З—В–Њ —Е–Њ—В—П –Є–Ј–љ–∞—З–∞–ї—М–љ–Њ —А–∞–Ј–Љ–µ—А –і–Њ—Б—В—Г–њ–љ–Њ–≥–Њ –Р–Я –ї—О–±–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ —Б–Њ—Б—В–∞–≤–ї—П—В—М —З—Г—В—М –Љ–µ–љ—М—И–µ 2 –У–± (–Є–ї–Є —З—Г—В—М –Љ–µ–љ—М—И–µ 3 –У–± –≤ —Б–њ–µ—Ж–Є–∞–ї—М–љ–Њ–Љ —А–µ–ґ–Є–Љ–µ —А–∞–±–Њ—В—Л –Ю–°), —Д—А–∞–≥–Љ–µ–љ—В–∞—Ж–Є—П –Њ–≥—А–∞–љ–Є—З–Є–≤–∞–µ—В –љ–∞–Є–±–Њ–ї—М—И–Є–є —А–∞–Ј–Љ–µ—А –љ–µ–њ—А–µ—А—Л–≤–љ–Њ–≥–Њ –±–ї–Њ–Ї–∞, –Ї–Њ—В–Њ—А—Л–є –Љ–Њ–ґ–µ—В –±—Л—В—М –Ј–∞—А–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞–љ/–≤—Л–і–µ–ї–µ–љ –Є–ї–Є —Б–њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞–љ. –Ъ—А–Њ–Љ–µ —Д—А–∞–≥–Љ–µ–љ—В–∞—Ж–Є–Є, –Ї–Њ—В–Њ—А–∞—П –Ј–∞—В—А–∞–≥–Є–≤–∞–µ—В –Є–Љ–µ–љ–љ–Њ –±–Њ–ї—М—И–Є–µ –љ–µ–њ—А–µ—А—Л–≤–љ—Л–µ –Ї—Г—Б–Ї–Є, –µ—Й—С –Є —А–∞–Ј–Љ–µ—А —Д–∞–є–ї–∞ –њ–Њ–і–Ї–∞—З–Ї–Є –≤–ї–Є—П–µ—В –љ–∞ –Њ–±—Й–µ—Б–Є—Б—В–µ–Љ–љ–Њ–µ –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ–µ —Б—Г–Љ–Љ–∞—А–љ–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Б—В—А–∞–љ–Є—Ж, –Ї–Њ—В–Њ—А–Њ–µ –Љ–Њ–ґ–µ—В –±—Л—В—М –≤—Л–і–µ–ї–µ–љ–Њ –≤—Б–µ–Љ —А–∞–±–Њ—В–∞—О—Й–Є–Љ –њ—А–Њ—Ж–µ—Б—Б–∞–Љ –≤–Љ–µ—Б—В–µ –≤–Ј—П—В—Л–Љ.
–Ь–Њ—А–∞–ї—М:
- –Х—Б–ї–Є –љ–µ —Г–і–∞—С—В—Б—П –≤—Л–і–µ–ї–Є—В—М –±–ї–Њ–Ї –њ–∞–Љ—П—В–Є, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –µ–≥–Њ —А–∞–Ј–Љ–µ—А –±–Њ–ї—М—И–µ, —З–µ–Љ –і–Њ—Б—В—Г–њ–љ–∞—П —З–∞—Б—В—М –Р–Я (—В–Њ –µ—Б—В—М –≤—Л —Е–Њ—В–Є—В–µ –Ј–∞—Б–µ–ї–Є—В—М 500 —З–µ–ї–Њ–≤–µ–Ї –≤ –Њ–і–љ—Г 100-–Љ–µ—Б—В–љ—Г—О –≥–Њ—Б—В–Є–љ–Є—Ж—Г), –љ—Г–ґ–љ–Њ –ї–Є–±–Њ –Ј–∞—Б—В–∞–≤–ї—П—В—М –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є –≤–Ї–ї—О—З–∞—В—М —А–µ–ґ–Є–Љ /3GB (–≤ –Ї–Њ—В–Њ—А–Њ–Љ —Б–Є—Б—В–µ–Љ–∞ —Б –љ–µ–Љ–∞–ї–Њ–є –≤–µ—А–Њ—П—В–љ–Њ—Б—В—М—О –≤–Њ–Њ–±—Й–µ –љ–µ —Б–Љ–Њ–ґ–µ—В –Ј–∞–≥—А—Г–Ј–Є—В—М—Б—П), –ї–Є–±–Њ –њ–µ—А–µ—Б–∞–ґ–Є–≤–∞—В—М –Є—Е –љ–∞ 64-–±–Є—В–љ—Л–µ —Б–Є—Б—В–µ–Љ—Л. –Э–Њ 32-–±–Є—В–љ—Л–µ –Є—Б–њ–Њ–ї–љ—П–µ–Љ—Л–µ —Д–∞–є–ї—Л –і–∞–ґ–µ –љ–∞ 64-–±–Є—В–љ—Л—Е —Б–Є—Б—В–µ–Љ–∞—Е –ґ–Є–≤—Г—В –њ–Њ –њ—А–∞–≤–Є–ї–∞–Љ 32-–±–Є—В–љ—Л—Е —Б–Є—Б—В–µ–Љ. –Р –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В—М –љ–∞ —Б–≤–µ—В 64-–±–Є—В–љ—Л–µ –Є—Б–њ–Њ–ї–љ—П–µ–Љ—Л–µ —Д–∞–є–ї—Л VB (–њ–Њ–Ї–∞ —З—В–Њ) —Г–≤—Л, –љ–µ —Г–Љ–µ–µ—В. –Э–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ, —Н—В–Њ –≤—Б—С –≤—А–µ–і–љ—Л–µ —Б–Њ–≤–µ—В—Л вАФ –љ—Г–ґ–љ–Њ –њ—А–Њ—Б—В–Њ –њ–µ—А–µ—Б–Љ–∞—В—А–Є–≤–∞—В—М –∞—А—Е–Є—В–µ–Ї—В—Г—А—Г —Б–≤–Њ–µ–є –њ—А–Њ–≥—А–∞–Љ–Љ—Л –Є —Б–≤–Њ–Є –њ–Њ–і—Е–Њ–і—Л. –Ш —Б–Њ–≤—Б–µ–Љ –њ–Њ-–і—А—Г–≥–Њ–Љ—Г —А–µ–∞–ї–Є–Ј–Њ–≤—Л–≤–∞—В—М —А–∞–±–Њ—В—Г —Б –і–∞–љ–љ—Л–Љ–Є.
–Х—Б–ї–Є –љ—Г–ґ–љ–Њ —А–∞–±–Њ—В–∞—В—М —Б –Њ–≥—А–Њ–Љ–љ—Л–Љ–Є –Њ–±—К—С–Љ–Њ–Љ –і–∞–љ–љ—Л—Е, –≤—Б–µ–≥–і–∞ –Љ–Њ–ґ–љ–Њ –і–µ—А–ґ–∞—В—М –Є—Е –≤ –Њ–≥—А–Њ–Љ–љ–Њ–Љ —Д–∞–є–ї–µ –љ–∞ –і–Є—Б–Ї–µ –Є –њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞—В—М –Ї—Г—Б–Њ—З–Ї–Є —Н—В–Њ–≥–Њ –Њ–≥—А–Њ–Љ–љ–Њ–≥–Њ —Д–∞–є–ї–∞ –≤ –Р–Я –њ—А–Њ—Ж–µ—Б—Б–∞ –Є —А–∞–±–Њ—В–∞—В—М —Б —Н—В–Є–Љ–Є –Ї—Г—Б–Њ—З–Ї–∞–Љ–Є. - –Х—Б–ї–Є –љ–µ —Г–і–∞—С—В—Б—П –≤—Л–і–µ–ї–Є—В—М –±–ї–Њ–Ї –њ–∞–Љ—П—В–Є, –њ–Њ—В–Њ–Љ—Г —З—В–Њ —Г–њ–Є—А–∞–µ—И—М—Б—П –≤ –Њ–≥—А–∞–љ–Є—З–µ–љ–Є–µ –љ–∞ —З–Є—Б–ї–Њ swap-backed —Б—В—А–∞–љ–Є—Ж, –Ї–Њ—В–Њ—А—Л–µ –Љ–Њ–≥—Г—В –±—Л—В—М –≤—Л–і–µ–ї–µ–љ—Л –≤—Б–µ–Љ –њ—А–Њ—Ж–µ—Б—Б–∞–Љ –≤–Љ–µ—Б—В–µ –≤–Ј—П—В—Л–Љ –≤ —Б—Г–Љ–Љ–µ (—В–Њ –µ—Б—В—М –њ—А–Є–µ—Е–∞–ї–Є –≤ –≥–Њ—Б—В–Є–љ–Є—Ж—Г, –≥–і–µ –≤ –њ—А–Є–љ—Ж–Є–њ–µ –µ—Б—В—М —Б–≤–Њ–±–Њ–і–љ—Л–µ –љ–Њ–Љ–µ—А–∞, –љ–Њ –Њ–Ї–∞–Ј–∞–ї–Њ—Б—М, —З—В–Њ –љ–∞ —Б–Ї–ї–∞–і–µ –±–Њ–ї—М—И–µ –љ–µ—В –Ї–Њ–Љ–њ–ї–µ–Ї—В–Њ–≤ –њ–Њ—Б—В–µ–ї—М–љ–Њ–≥–Њ –±–µ–ї—М—П), —В–Њ –љ—Г–ґ–љ–Њ –ї–Є–±–Њ —Г–≤–µ–ї–Є—З–Є—В—М —А–∞–Ј–Љ–µ—А —Д–∞–є–ї–∞ –њ–Њ–і–Ї–∞—З–Ї–Є (–њ—А–Њ—Б–Є—В—М –≤–ї–∞–і–µ–ї—М—Ж–∞ —Б–µ—В–Є –≥–Њ—Б—В–Є–љ–Є—Ж –Ј–∞–Ї—Г–њ–Є—В—М –µ—Й—С –Ї–Њ–Љ–њ–ї–µ–Ї—В—Л, —Е—А–∞–љ–Є–Љ—Л–µ –љ–∞ —Б–Ї–ї–∞–і–µ), –ї–Є–±–Њ –≤—Л–і–µ–ї—П—В—М —Н—В–Є —Б—В—А–∞–љ–Є—Ж—Л –љ–µ –Є–Ј —Д–∞–є–ї–∞ –њ–Њ–і–Ї–∞—З–Ї–Є вАФ –і–ї—П —Н—В–Њ–≥–Њ –њ—А–Є–і—С—В—Б—П —Б–Њ–Ј–і–∞—В—М —Б–≤–Њ–є —Д–∞–є–ї –љ–∞ –і–Є—Б–Ї–µ (–і–Њ—Б—В–∞—В–Њ—З–љ–Њ–≥–Њ —А–∞–Ј–Љ–µ—А–∞) –Є –і–ї—П –≤—Л–і–µ–ї–µ–љ–Є—П –њ–∞–Љ—П—В–Є –њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞—В—М –µ–≥–Њ –Ї—Г—Б–Ї–Є –≤ –Р–Я (–њ—А–Є–µ–Ј–ґ–∞—В—М —Б–Њ —Б–≤–Њ–Є–Љ –љ–∞–±–Њ—А–Њ–Љ –Ї–Њ–Љ–њ–ї–µ–Ї—В–Њ–≤ –њ–Њ—Б—В–µ–ї—М–љ–Њ–≥–Њ –±–µ–ї—М—П). –С—Г–і–µ—В —В–∞–Ї–Њ–є —Б–∞–Љ–Њ–і–µ–ї—М–љ—Л–є —Д–∞–є–ї –њ–Њ–і–Ї–∞—З–Ї–Є, –љ–Њ –њ—А–µ–Є–Љ—Г—Й–µ—Б—В–≤ —Г —В–∞–Ї–Њ–≥–Њ –њ–Њ–і—Е–Њ–і–∞ –Љ–∞–ї–Њ. –†–∞–Ј–≤–µ —З—В–Њ —В–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ –Љ–Њ–ґ–љ–Њ –њ–Њ–ї—Г—З–Є—В—М —И–∞–љ—Б –Ј–∞–њ—Г—Б–Ї–∞—В—М –њ—А–Њ–ґ–Њ—А–ї–Є–≤–Њ–µ –і–Њ –њ–∞–Љ—П—В–Є –њ—А–Є–ї–Њ–ґ–µ–љ–Є–µ –≥–і–µ-—В–Њ —В–∞–Љ, –≥–і–µ –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М –љ–µ –Є–Љ–µ–µ—В –њ—А–∞–≤ —Г–≤–µ–ї–Є—З–Є—В—М —А–∞–Ј–Љ–µ—А —Д–∞–є–ї–∞ –њ–Њ–і–Ї–∞—З–Ї–Є, –∞ —В–Њ—В, –Ї—В–Њ –Є–Љ–µ–µ—В —В–∞–Ї–Њ–µ –њ—А–∞–≤–Њ, –љ–µ –ґ–µ–ї–∞–µ—В —Н—В–Њ–≥–Њ –і–µ–ї–∞—В—М.
- –Х—Б–ї–Є –љ–µ —Г–і–∞—С—В—Б—П –≤—Л–і–µ–ї–Є—В—М –±–ї–Њ–Ї –њ–∞–Љ—П—В–Є, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –Љ–µ—И–∞–µ—В —Д—А–∞–≥–Љ–µ–љ—В–Є—А–Њ–≤–∞–љ–љ–Њ—Б—В—М –Р–Я (—Е–Њ—В–Є—В–µ –Ј–∞–љ—П—В—М –≤–µ—Б—М —Н—В–∞–ґ –≥–Њ—Б—В–Є–љ–Є—Ж—Л —Ж–µ–ї–Є–Ї–Њ–Љ, –љ–Њ –љ–µ—В –љ–Є –Њ–і–љ–Њ–≥–Њ –њ–Њ–ї–љ–Њ—Б—В—М—О —Б–≤–Њ–±–Њ–і–љ–Њ–≥–Њ —Н—В–∞–ґ–∞), —В–Њ –љ—Г–ґ–љ–Њ –њ–µ—А–µ—Б–Љ–∞—В—А–Є–≤–∞—В—М –∞—А—Е–Є—В–µ–Ї—В—Г—А—Г –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П (–Њ—В–Ї–∞–Ј—Л–≤–∞—В—М—Б—П –Њ—В –ґ–µ–ї–∞–љ–Є—П –Ј–∞—Б–µ–ї–Є—В—М –≤–µ—Б—М —Б–≤–Њ–є –Ї–Њ–ї–ї–µ–Ї—В–Є–≤ –љ–∞ –Њ–і–љ–Њ–Љ –Є —В–Њ–Љ –ґ–µ —Н—В–∞–ґ–µ) –Є –Њ—А–≥–∞–љ–Є–Ј–∞—Ж–Є—О –і–∞–љ–љ—Л—Е вАФ —Д—А–∞–≥–Љ–µ–љ—В–Є—А–Њ–≤–∞—В—М —Б–≤–Њ–Є –і–∞–љ–љ—Л–µ, —З—В–Њ–±—Л —Г–Љ–µ—Й–∞–ї–Є—Б—М –≤ —Д—А–∞–≥–Љ–µ–љ—В–Є—А–Њ–≤–∞–љ–љ–Њ–Љ –Р–Я. –Т–Љ–µ—Б—В–Њ –Њ–≥—А–Њ–Љ–љ—Л—Е –љ–µ–њ—А–µ—А—Л–≤–љ—Л—Е –Љ–∞—Б—Б–Є–≤–Њ–≤ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —Б–≤—П–Ј–љ—Л–µ —Б–њ–Є—Б–Ї–Є, –і–µ—А–µ–≤—М—П, –±–ї–Њ—З–љ—Л–µ —Б–њ–Є—Б–Ї–Є. –Э–∞–њ—А–Є–Љ–µ—А, –≤–Љ–µ—Б—В–Њ —В–≤–Њ–µ–≥–Њ –Њ–≥—А–Њ–Љ–љ–Њ–≥–Њ –і–≤—Г—Е–Љ–µ—А–љ–Њ–≥–Њ –Љ–∞—Б—Б–Є–≤–∞ вАФ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –Љ–∞—Б—Б–Є–≤ –Љ–∞—Б—Б–Є–≤–Њ–≤.
–Э–µ–Ї–Њ—В–Њ—А—Л–µ —Д–∞–Ї—В—Л –Њ—Б—В–∞–ї–Є—Б—М –Ј–∞ –Ї–∞–і—А–Њ–Љ:
- –ѓ –љ–∞–њ–Є—Б–∞–ї, —З—В–Њ –ї—О–±–∞—П —Б—В—А–∞–љ–Є—Ж–∞ –∞–і—А–µ—Б–љ–Њ–≥–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–∞ –≤ –ї—О–±–Њ–є –Љ–Њ–Љ–µ–љ—В –≤—А–µ–Љ–µ–љ–Є –ї–Є–±–Њ –ї–µ–ґ–Є—В –љ–∞ –і–Є—Б–Ї–µ (–≤ —Д–∞–є–ї–µ-–њ–Њ–і–Ї–∞—З–Ї–µ –ї–Є–±–Њ —Д–∞–є–ї–µ-–Њ–±—А–∞–Ј–µ, –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–≤—И–µ–Љ—Б—П –њ—А–Є –њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞–љ–Є–Є), –ї–Є–±–Њ –≤ —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є, –Є –Ї–Њ–≥–і–∞ –Є–і—С—В –Њ–±—А–∞—Й–µ–љ–Є–µ –Ї —Б—В—А–∞–љ–Є—Ж–µ, –Ї–Њ—В–Њ—А–∞—П –≤ –і–∞–љ–љ—Л–є –Љ–Њ–Љ–µ–љ—В –љ–µ –љ–∞—Е–Њ–і–Є—В—Б—П –≤ —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є, –Њ–љ–∞ —В—Г–і–∞ –Ј–∞–≥—А—Г–ґ–∞–µ—В—Б—П, –∞ —В–∞ —Б—В—А–∞–љ–Є—Ж–∞, –Ї–Њ—В–Њ—А–∞—П —В–∞–Љ –±—Л–ї–∞, –≤—Л–≥—А—Г–ґ–∞–µ—В—Б—П. –Т –Њ—Б–љ–Њ–≤–µ —Б–≤–Њ–µ–є —Н—В–Њ–є —В–∞–Ї, –љ–Њ —Б—Г—Й–µ—Б—В–≤—Г–µ—В —Б—В—А–∞–љ–Є—Ж—Л, –Ї–Њ–≥–і–∞ –≤—Б–µ–≥–і–∞ –њ—А–Є—Б—Г—В—Б—В–≤—Г—О—В –≤ —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є –Є –љ–Є–Ї–Њ–≥–і–∞ –љ–µ –≤—Л–≥—А—Г–ґ–∞—О—В—Б—П –љ–∞ –і–Є—Б–Ї (—З—В–Њ–±—Л –Њ—Б–≤–Њ–±–Њ–і–Є—В—М –Љ–µ—Б—В–Њ –≤ —Д–Є–Ј. –њ–∞–Љ—П—В–Є –њ–Њ–і–Њ —З—В–Њ-—В–Њ –і—А—Г–≥–Њ–µ). –Ґ–∞–Ї–Є–µ —Б—В—А–∞–љ–Є—Ж—Л –љ–∞–Ј—Л–≤–∞—О—В—Б—П –љ–µ–њ–Њ–і–Ї–∞—З–Є–≤–∞–µ–Љ—Л–Љ–Є (non-paged), –Є –Є—Б–њ–Њ–ї—М–Ј—Г—О—В—Б—П –Њ–љ–Є —П–і—А–Њ–Љ –Ю–° –і–ї—П –Њ—Б–Њ–±—Л—Е –љ—Г–ґ–і. –Э–∞–њ—А–Є–Љ–µ—А —Б–∞–Љ –Ї–Њ–і, –Ї–Њ—В–Њ—А—Л–є –Њ—Б—Г—Й–µ—Б—В–≤–ї—П–µ—В –њ–Њ–і–Ї–∞—З–Ї—Г (–њ–Њ–і–≥—А—Г–Ј–Ї—Г/–≤—Л–≥—А—Г–Ј–Ї—Г —Б—В—А–∞–љ–Є—Ж –Є–Ј —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є –љ–∞ –і–Є—Б–Ї –Є –Њ–±—А–∞—В–љ–Њ), —Е—А–∞–љ–Є—В—Б—П –Є–Љ–µ–љ–љ–Њ –≤ –љ–µ–њ–Њ–Ї–∞—З–Є–≤–∞–µ–Љ—Л—Е –љ–µ–≤—Л–≥—А—Г–ґ–∞–µ–Љ—Л—Е —Б—В—А–∞–љ–Є—Ж–∞—Е. –Х—Б–ї–Є –±—Л —Б—В—А–∞–љ–Є—Ж–∞ –њ–∞–Љ—П—В–Є, –≤ –Ї–Њ—В–Њ—А–Њ–є —Е—А–∞–љ–Є—В—Б—П —Н—В–Њ—В –Ї–Њ–і, –±—Л–ї –±—Л –≤—Л–≥—А—Г–ґ–µ–љ –љ–∞ –і–Є—Б–Ї, —В–Њ –љ–µ–Ї–Њ–Љ—Г –±—Л–ї–Њ –±—Л –Ј–∞–≥—А—Г–Ј–Є—В—М –µ—С (–Є–ї–Є –ї—О–±—Г—О –і—А—Г–≥—Г—О —Б—В—А–∞–љ–Є—Ж—Г) –Њ–±—А–∞—В–љ–Њ. –Ґ–∞–Ї–Є–µ —Б—В—А–∞–љ–Є—Ж—Л вАФ –і–µ—Д–Є—Ж–Є—В–љ—Л–є —А–µ—Б—Г—А—Б, –љ–Њ —В–∞–Ї –Є–ї–Є –Є–љ–∞—З–µ, –њ–Њ–і —А–∞–Ј–љ—Л–µ –љ—Г–ґ–і—Л —П–і—А–Њ –Ю–° –Є—Е –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В. –Я–Њ—Н—В–Њ–Љ—Г –Њ–±—К—С–Љ —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є –≤–ї–Є—П–µ—В –љ–µ —В–Њ–ї—М–Ї–Њ –љ–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М, –љ–Њ –Є –љ–∞ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –љ–µ–≤—Л–≥—А—Г–ґ–∞–µ–Љ—Л—Е —Б—В—А–∞–љ–Є—Ж, –Ї–Њ—В–Њ—А—Л–µ –Љ–Њ–ґ–µ—В –≤—Л–і–µ–ї–Є—В—М –і–ї—П —Б–µ–±—П —П–і—А–Њ –Ю–°.
- –Э–µ–њ—А–∞–≤–Є–ї—М–љ–Њ –і—Г–Љ–∞—В—М, —З—В–Њ –≤—Б–µ —Б—В—А–∞–љ–Є—Ж—Л —Д–Є–Ј–њ–∞–Љ—П—В–Є –Є—Б–њ–Њ–ї—М–Ј—Г—О—В—Б—П –њ–Њ–і –Ј–∞–≤—П–Ј–Ї—Г. –Х—Б–ї–Є –±—Л —Н—В–Њ –±—Л–ї–Њ —В–∞–Ї, –њ—А–µ–ґ–і–µ —З–µ–Љ –Ј–∞–≥—А—Г–Ј–Є—В—М –Ї–∞–Ї—Г—О-—В–Њ —Б—В—А–∞–љ–Є—Ж—Г —Б –і–Є—Б–Ї–∞ –≤ —Д–Є–Ј–њ–∞–Љ—П—В—М, –њ—А–Є—И–ї–Њ—Б—М –±—Л —Б–љ–∞—З–∞–ї–∞ –Ї–∞–Ї—Г—О-—В–Њ –≤—Л–≥—А—Г–Ј–Є—В—М. –Р –≤—Л–≥—А—Г–Ј–Ї–∞ (–Ї–∞–Ї –Є –Ј–∞–≥—А—Г–Ј–Ї–∞) вАФ —Н—В–Њ –і–Є—Б–Ї–Њ–≤—Л–µ –Њ–њ–µ—А–∞—Ж–Є–Є, –∞ –Њ–љ–Є –Љ–µ–і–ї–µ–љ–љ—Л–µ, –Є —Н—В–Њ —Б–Є–ї—М–љ–Њ —Г—Е—Г–і—И–∞–ї–Њ –±—Л –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М –њ—А–Њ–≥—А–∞–Љ–Љ –Є –Ю–° –њ—А–Є —А–∞–±–Њ—В–µ —Б –њ–∞–Љ—П—В—М—О. –Т–Љ–µ—Б—В–Њ —Н—В–Њ–≥–Њ –Ю–° –≤—Б–µ–≥–і–∞ –і–µ—А–ґ–Є—В –Ї–∞–Ї–Њ–µ-—В–Њ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Б–≤–Њ–±–Њ–і–љ—Л—Е —Б—В—А–∞–љ–Є—Ж –њ—А–Њ –Ј–∞–њ–∞—Б. –Ъ–Њ–≥–і–∞ —В—А–µ–±—Г–µ—В—Б—П –њ–Њ–і–≥—А—Г–Ј–Є—В—М –Ї–∞–Ї—Г—О-—В–Њ —Б—В—А–∞–љ–Є—Ж—Г —Б –і–Є—Б–Ї–∞ –≤ —Д–Є–Ј. –њ–∞–Љ—П—В—М, —В–Њ —Б—А–∞–Ј—Г –ґ–µ –≤—Л–њ–Њ–ї–љ—П–µ—В—Б—П —Н—В–∞ –њ–Њ–і–≥—А—Г–Ј–Ї–∞, –Є –і–ї—П —Н—В–Њ–≥–Њ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П —Б–≤–Њ–±–Њ–і–љ–∞—П —Б—В—А–∞–љ–Є—Ж–∞ —Д–Є–Ј. –њ–∞–Љ—П—В–Є. –Я–Њ—В–Њ–Ї, –≤—Л–њ–Њ–ї–љ–Є–≤—И–Є–є –Њ–±—А–∞—Й–µ–љ–Є–µ –Ї —Б—В—А–∞–љ–Є—Ж–µ, –њ—А–Њ–і–Њ–ї–ґ–∞–µ—В —Б–≤–Њ—О —А–∞–±–Њ—В—Г, –љ–Њ –њ—А–Є —Н—В–Њ–Љ –≤ —Д–Њ–љ–Њ–≤–Њ–Љ —Б–Є—Б—В–µ–Љ–љ–Њ–Љ –њ–Њ—В–Њ–Ї–µ –±—Г–і–µ—В –њ—А–Њ–Є–Ј–≤–µ–і–µ–љ–∞ –≤—Л–≥—А—Г–Ј–Ї–∞ –Ї–∞–Ї–Њ–є-–љ–Є–±—Г–і—М –Љ–∞–ї–Њ–Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ–Њ–є —Б—В—А–∞–љ–Є—Ж—Л —Д–Є–Ј. –њ–∞–Љ—П—В–Є, —З—В–Њ–±—Л –њ–Њ–і–і–µ—А–ґ–Є–≤–∞—В—М –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ ¬Ђ–Ј–∞–њ–∞—Б–љ—Л—Е¬ї —Б–≤–Њ–±–Њ–і–љ—Л—Е —Б—В—А–∞–љ–Є—Ж —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –њ–∞–Љ—П—В–Є –љ–∞ –њ—А–µ–ґ–љ–µ–Љ —Г—А–Њ–≤–љ–µ.
- –Т—Б–µ –Љ–Њ–Є –∞–љ–∞–ї–Њ–≥–Є–Є —Б –≥–Њ—Б—В–Є–љ–Є—Ж–µ–є –Є –Ј–∞—Б–µ–ї–µ–љ–Є–µ–Љ –≤ –љ–Њ–Љ–µ—А–∞ –±—Л–ї–Є –љ–∞–њ–Є—Б–∞–љ—Л –Є—Б—Е–Њ–і—П –Є–Ј –њ—А–µ–і–њ–Њ–ї–Њ–ґ–µ–љ–Є–є, —З—В–Њ:
- –Т—Б–µ –љ–Њ–Љ–µ—А–∞ вАФ –Њ–і–љ–Њ–Љ–µ—Б—В–љ—Л–µ.
- –Т –≥–Њ—Б—В–Є–љ–Є—Ж—Г –Љ–Њ–ґ–љ–Њ –Ј–∞—Б–µ–ї–Є—В—М—Б—П —Б—А–∞–Ј—Г, –љ–µ –±—А–Њ–љ–Є—А—Г—П (–љ–µ —А–µ–Ј–µ—А–≤–Є—А—Г—П) –љ–Њ–Љ–µ—А –Ј–∞—А–∞–љ–µ–µ.
–Ґ–Њ—З–љ–Њ —В–∞–Ї –ґ–µ –Њ–±—Б—В–Њ—П—В –і–µ–ї–∞ –≤ Windows.
–Э–µ–ї—М–Ј—П –њ—А–Њ—Б—В–Њ —В–∞–Ї –≤–Ј—П—В—М –Є –≤—Л–і–µ–ї–Є—В—М —Б–µ–±–µ –Њ–і–љ—Г –Є–ї–Є –њ–∞—А–Њ—З–Ї—Г —Б—В—А–∞–љ–Є—Ж –њ–∞–Љ—П—В–Є. –°–њ–µ—А–≤–∞ –љ—Г–ґ–љ–Њ –Ј–∞—А–µ–Ј–µ—А–≤–Є—А–Њ–≤–Њ–≤–∞—В—М —Б–µ–±–µ —А–µ–≥–Є–Њ–љ –њ–∞–Љ—П—В–Є. –Я–Њ–і–Њ–±–љ–Њ —В–Њ–Љ—Г, –Ї–∞–Ї –љ–µ–ї—М–Ј—П —А–∞–Ј–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞—В—М (–љ–Њ –Љ–Њ–ґ–љ–Њ –Ј–∞–љ—П—В—М) –Њ—В–і–µ–ї—М–љ–Њ–µ –Ї–Њ–є–Ї–Њ-–Љ–µ—Б—В–Њ –≤ –≥–Њ—Б—В–Є–љ–Є—Ж–µ, –љ–µ–ї—М–Ј—П –≤ —Б–Є—Б—В–µ–Љ–µ –Ј–∞—А–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞—В—М –Њ—В–і–µ–ї—М–љ—Г—О —Б—В—А–∞–љ–Є—Ж—Г. –†–∞–Ј–µ—А–≤–Є—А–Њ–≤–∞–љ–Є–µ —А–µ–≥–Є–Њ–љ–Њ–≤ –њ–∞–Љ—П—В–Є –Њ—Б—Г—Й–µ—Б—В–≤–ї—П–µ—В—Б—П –±–ї–Њ–Ї–∞–Љ–Є –њ–Њ 64 –Ъ–± (–њ–Њ 16 —Б—В—А–∞–љ–Є—Ж –≤ –Ї–∞–ґ–і–Њ–Љ –±–ї–Њ–Ї–µ), –њ–Њ–і–Њ–±–љ–Њ —В–Њ–Љ—Г, –Ї–∞–Ї –≤ –≥–Њ—Б—В–Є–љ–Є—Ж—Г —А–µ–Ј–µ—А–≤–Є—А—Г—О—В—Б—П —Ж–µ–ї—Л–µ –љ–Њ–Љ–µ—А–∞ (–њ–Њ 3 —Б–њ–∞–ї—М–љ—Л—Е –Љ–µ—Б—В–∞, –∞ –љ–µ –Њ—В–і–µ–ї—М–љ—Л–µ –Ї–Њ–є–Ї–Є). –Я–Њ—Б–ї–µ —В–Њ–≥–Њ, –Ї–∞–Ї –±—Л–ї –Ј–∞—А–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞–љ —А–µ–≥–Є–Њ–љ –њ–∞–Љ—П—В–Є (—А–∞–Ј–Љ–µ—А –Ї–Њ—В–Њ—А–Њ–≥–Њ –Ї—А–∞—В–µ–љ 64 –Ї–±), –≤ —Н—В–Њ–Љ —А–µ–≥–Є–Њ–љ–µ –Љ–Њ–ґ–љ–Њ –≤—Л–і–µ–ї—П—В—М —Б–µ–±–µ –Њ—В–і–µ–ї—М–љ—Л–µ —Б—В—А–∞–љ–Є—Ж—Л. –Ь–Њ–ґ–љ–Њ –≤—Л–і–µ–ї–Є—В—М –≤—Б–µ —Б—В—А–∞–љ–Є—Ж—Л –Є–Ј –Ј–∞—А–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞–љ–љ–Њ–≥–Њ —А–µ–≥–Є–Њ–љ–∞, –Љ–Њ–ґ–љ–Њ –≤—Л–і–µ–ї–Є—В—М —В–Њ–ї—М–Ї–Њ 1, –Љ–Њ–ґ–љ–Њ –і–Њ –њ–Њ—А—Л –і–Њ –≤—А–µ–Љ–µ–љ–Є –≤–Њ–Њ–±—Й–µ –љ–Є—З–µ–≥–Њ –љ–µ –≤—Л–і–µ–ї—П—В—М, –∞ –њ—А–Њ—Б—В–Њ –і–µ—А–ґ–∞—В—М –±—А–Њ–љ—М ¬Ђ–љ–∞ –≤—Б—П–Ї–Є–є —Б–ї—Г—З–∞–є¬ї.
–†–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞–љ–Є–µ –±–ї–Њ–Ї–Њ–≤ –њ–∞–Љ—П—В–Є –Њ—В–ї–Є—З–∞–µ—В—Б—П –Њ—В –≤—Л–і–µ–ї–µ–љ–Є—П –њ–∞–Љ—П—В–Є —В–Њ—З–љ–Њ —В–∞–Ї –ґ–µ, –Ї–∞–Ї –±—А–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ –љ–Њ–Љ–µ—А–Њ–≤ –Њ—В–ї–Є—З–∞–µ—В—Б—П –Њ—В –Ј–∞—Б–µ–ї–µ–љ–Є—П –≤ –љ–Є—Е –ї—О–і–µ–є.
–Ю–≥—А–∞–љ–Є—З–µ–љ–Є–µ –љ–∞ —Б—Г–Љ–Љ–∞—А–љ–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –≤—Л–і–µ–ї–µ–љ–љ—Л—Е swap-backed —Б—В—А–∞–љ–Є—Ж —Б–Ї–∞–Ј—Л–≤–∞–µ—В—Б—П –Є–Љ–µ–љ–љ–Њ –њ—А–Є –≤—Л–і–µ–ї–µ–љ–Є–Є —Б—В—А–∞–љ–Є—Ж. –Я—А–Є —А–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞–љ–Є–Є –±–ї–Њ–Ї–Њ–≤ –љ–µ –Љ–Њ–ґ–µ—В –±—Л—В—М –љ–Є–Ї–∞–Ї–Њ–≥–Њ ¬Ђ–љ–µ —Е–≤–∞—В–∞–µ—В –њ–∞–Љ—П—В–Є¬ї –њ–Њ –њ—А–Є—З–Є–љ–µ –Є—Б—З–µ—А–њ–∞–љ–Є—П –Љ–µ—Б—В–∞ –≤ —Д–∞–є–ї–µ –њ–Њ–і–Ї–∞—З–Ї–Є вАФ –Њ—И–Є–±–Ї–∞ –Љ–Њ–ґ–µ—В –±—Л—В—М —В–Њ–ї—М–Ї–Њ –њ–Њ –њ—А–Є—З–Є–љ–µ —В–Њ–≥–Њ, —З—В–Њ –ґ–µ–ї–∞–µ–Љ–Њ–µ –Љ–µ—Б—В–Њ —Г–ґ–µ –Ј–∞—А–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞–ї –Ї—В–Њ-—В–Њ –і—А—Г–≥–Њ–є. –†–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞–љ–Є–µ вАФ —Н—В–Њ —З–Є—Б—В–∞—П –±—О—А–Њ–Ї—А–∞—В–Є—П, –Ї–∞–Ї –Є –±—А–Њ–љ–Є—А–Њ–≤–∞–љ–Є–µ –≤ –≥–Њ—Б—В–Є–љ–Є—Ж–µ, —Ж–µ–ї—М —Н—В–Њ–є –њ—А–Њ—Ж–µ–і—Г—А—Л —Б–Њ—Б—В–Њ–Є—В —В–Њ–ї—М–Ї–Њ –≤ —В–Њ–Љ, —З—В–Њ–±—Л –љ—Г–і–љ—Л–µ —Б—В—А–∞–љ–Є—Ж—Л/–љ–Њ–Љ–µ—А–∞ –љ–µ –Њ–Ї–∞–Ј–∞–ї–Є—Б—М —Е–∞–Њ—В–Є—З–љ–Њ –Ј–∞–љ—П—В—Л–Љ–Є –Ї –Љ–Њ–Љ–µ–љ—В—Г, –Ї–Њ–≥–і–∞ –Њ–љ–Є –њ–Њ–љ–∞–і–Њ–±—П—В—Б—П (–Ї–Њ–≥–і–∞ –њ–Њ—В—А–µ–±—Г–µ—В—Б—П –≤—Л–і–µ–ї–Є—В—М —Б—В—А–∞–љ–Є—Ж—Л / –Ј–∞—Б–µ–ї–Є—В—М –ї—О–і–µ–є). –Э–∞ —А–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞–љ–Є–µ —А–µ–≥–Є–Њ–љ–Њ–≤ –њ–∞–Љ—П—В–Є –љ–µ —В—А–∞—В–Є—В—Б—П –љ–Є —Д–∞–є–ї –њ–Њ–і–Ї–∞—З–Ї–Є –љ–Є —Д–Є–Ј–Є—З–µ—Б–Ї–∞—П –њ–∞–Љ—П—В—М, –њ–Њ–і–Њ–±–љ–Њ —В–Њ–Љ—Г, –Ї–∞–Ї –љ–∞ –±—А–Њ–љ–Є—А—Г–µ–Љ—Л–µ –≤ –≥–Њ—Б—В–Є–љ–Є—Ж–µ –љ–Њ–Љ–µ—А–∞ –љ–µ —В—А–∞—В—П—В—Б—П –Ї–Њ–Љ–њ–ї–µ–Ї—В—Л –њ–Њ—Б—В–µ–ї—М–љ–Њ–≥–Њ –±–µ–ї—М—П (–Њ–љ–Є —В—А–∞—В—П—В—Б—П –≤ –Љ–Њ–Љ–µ–љ—В –Ј–∞—Б–µ–ї–µ–љ–Є—П –Ї–Њ–љ–Ї—А–µ—В–љ—Л—Е –ї—О–і–µ–є).
–§–∞–є–ї –њ–Њ–і–Ї–∞—З–Ї–Є —В—А–∞—В–Є—В—Б—П –ї–Є—И—М —В–Њ–≥–і–∞, –Ї–Њ–≥–і–∞ –Є–Ј –Ј–∞—А–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞–љ–љ–Њ–≥–Њ —А–µ–≥–Є–Њ–љ–∞ –≤—Л–і–µ–ї–µ–љ–Є—П –љ–Њ–≤–∞—П –њ—Г—Б—В–∞—П —Б—В—А–∞–љ–Є—Ж–∞.
–Э–Њ –≤ –Ј–∞—А–µ–Ј–µ—А–≤–Є—А–≤–Њ–∞–љ–љ—Л–є —А–µ–≥–Є–Њ–љ –Љ–Њ–ґ–љ–Њ —Б–њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞—В—М —Б–Њ–і–µ—А–ґ–Є–Љ–Њ–µ –Ї–∞–Ї–Њ–≥–Њ-—В–Њ –њ—А–Њ–Є–Ј–≤–Њ–ї—М–љ–Њ–≥–Њ —Д–∞–є–ї–∞, —В–Њ–≥–і–∞ —Д–∞–є–ї –њ–Њ–і–Ї–∞—З–Ї–Є –љ–µ —А–∞—Б—Е–Њ–і—Г–µ—В—Б—П (—Н—В–Њ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –Ј–∞—Б–µ–ї–µ–љ–Є—О –≤ –Ј–∞—А–∞–љ–µ–µ –Ј–∞–±—А–Њ–љ–Є—А–Њ–≤–∞–љ–љ—Л–є –љ–Њ–Љ–µ—А —Б —Б–Њ–±—Б—В–≤–µ–љ–љ—Л–Љ–Є –Ї–Њ–Љ–њ–ї–µ–Ї—В–∞–Љ–Є –њ–Њ—Б—В–µ–ї—М–љ–Њ–≥–Њ –±–µ–ї—М—П вАФ —В–Њ–≥–і–∞ –Ї–Њ–Љ–њ–ї–µ–Ї—В—Л, —Е—А–∞–љ—П—Й–Є–µ—Б—П –љ–∞ —Б–Ї–ї–∞–і–µ –љ–µ —А–∞—Б—Е–Њ–і—Г—О—В—Б—П). - –Т –љ–Њ—А–Љ–µ –њ—А–Є –њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞–љ–Є–Є —Д–∞–є–ї –≤ –њ–∞–Љ—П—В—М, –µ—Б–ї–Є –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –Ј–∞–њ–Є—Б—М –≤ —Г—З–∞—Б—В–Њ–Ї –њ–∞–Љ—П—В–Є, –Ї—Г–і–∞ –±—Л–ї —Б–њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞–љ —Д–∞–є–ї, –Є –µ—Б–ї–Є –і–∞–љ–љ—Л–µ –Љ–µ–љ—П—О—В—Б—П, —В–Њ –Є–Ј–Љ–µ–љ–µ–љ–Є–µ –Њ—В—А–∞–ґ–∞–µ—В—Б—П –Є –≤ —Д–∞–є–ї–µ. –Э–Њ —Б—Г—Й–µ—Б—В–≤—Г—В–µ —А–µ–ґ–Є–Љ copy-on-write, –њ—А–Є –Ї–Њ—В–Њ—А–Њ–Љ –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є—П —Б–њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞–љ–љ–Њ–є —Б—В—А–∞–љ–Є—Ж—Л –њ—А–Є–≤–Њ–і–Є—В –Ї —В–Њ–Љ—Г, —З—В–Њ —В–∞–Ї–∞—П —Б—В—А–∞–љ–Є—Ж–∞ –њ–µ—А–µ—Б—В–∞—С—В –±—Л—В—М –њ—А–Њ–µ–Ї—Ж–Є–µ–є –Є–Ј–љ–∞—З–∞–ї—М–љ–Њ–≥–Њ —Д–∞–є–ї–∞, —В–Њ –µ—Б—В—М –њ–µ—А–µ—Б—В–∞—С—В –±—Л—В—М image-backed. –Т –Љ–Њ–Љ–µ–љ—В –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є–Є —В–∞–Ї–Њ–є —Б—В—А–∞–љ–Є—Ж—Л –њ–Њ–і –љ–µ—С –≤—Л–і–µ–ї—П–µ—В—Б—П —Б—В—А–∞–љ–Є—Ж–∞ –Є–Ј —Д–∞–є–ї–∞ –њ–Њ–і–Ї–∞—З–Ї–Є –Є —Б –Љ–Њ–Љ–µ–љ—В–∞ –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є–Є –Є–Ј–Љ–µ–љ—С–љ–љ–∞—П –Ї–Њ–њ–Є–Є —Б—В—А–∞–љ–Є—Ж—Л –љ–∞—З–Є–љ–∞–µ—В –ґ–Є—В—М –≤ —Д–∞–є–ї–µ –њ–Њ–і–Ї–∞—З–Ї–µ, —В–Њ –µ—Б—В—М —Б—В–∞–љ–Њ–≤–Є—В—Б—П swap-backed —Б—В—А–∞–љ–Є—Ж–µ–є. –§–∞–є–ї, –Ї–Њ—В–Њ—А—Л–є –±—Л–ї —Б–њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞–љ, –њ—А–Є —Н—В–Њ–Љ –љ–µ –Є–Ј–Љ–µ–љ—П–µ—В—Б—П. –°—В—А–∞–љ–Є—Ж—Л –Р–Я, –њ–Њ–ї—Г—З–µ–љ–љ—Л–µ –≤ —А–µ–Ј—Г–ї—М—В–∞—В–µ –њ—А–Њ–µ–Ї—Ж–Є–Є, –Ї–Њ—В–Њ—А—Л–µ –љ–µ –±—Л–ї–Є –Є–Ј–Љ–µ–љ–µ–љ—Л —Б –Љ–Њ–Љ–µ–љ—В–∞ –њ—А–Њ–µ–Ї—Ж–Є–Є, –њ—А–Њ–і–Њ–ї–ґ–∞—О—В –±—Л—В—М –њ—А–Њ–µ–Ї—Ж–Є–µ–є —Н—В–Њ–≥–Њ —Б–∞–Љ–Њ–≥–Њ —Д–∞–є–ї–∞. –Ы–Є—И—М —В–µ —Б—В—А–∞–љ–Є—Ж—Л, –Ї–Њ—В–Њ—А—Л–µ –њ–Њ—Б–ї–µ –њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞–љ–Є—П –±—Л–ї–Є –Є–Ј–Љ–µ–љ–µ–љ—Л, –њ—А–µ–Њ–±—А–∞–Ј—Г—О—В—Б—П –≤ —Б—В—А–∞–љ–Є—Ж—Л, –і–∞–љ–љ—Л–µ –Ї–Њ—В–Њ—А—Л—Е —Е—А–∞–љ—П—В—Б—П –≤ —Д–∞–є–ї–µ-–њ–Њ–і–Ї–∞—З–Ї–Є.
–Ш–Љ–µ–љ–љ–Њ —Н—В–Њ—В —А–µ–ґ–Є–Љ copy-on-write –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –њ—А–Є –њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞–љ–Є–Є –Є—Б–њ–Њ–ї–љ—П–µ–Љ—Л—Е —Д–∞–є–ї–Њ–≤ (EXE/DLL/OCX).
вАФWe separate their smiling faces from the rest of their body, Captain.
вАФThat's right! We decapitate them.
вАФThat's right! We decapitate them.
- tych
- –Э–∞—З–Є–љ–∞—О—Й–Є–є
-

- –°–Њ–Њ–±—Й–µ–љ–Є—П: 13
- –Ч–∞—А–µ–≥–Є—Б—В—А–Є—А–Њ–≤–∞–љ: 03.12.2013 (–Т—В) 0:16
- –Ю—В–Ї—Г–і–∞: Russia, Kaliningrad
Re: –Ъ–∞–Ї –њ–Њ–±–µ–і–Є—В—М "Out of memory"?
![]() tych » 01.03.2016 (–Т—В) 11:43
tych » 01.03.2016 (–Т—В) 11:43
kugeod –њ–Є—Б–∞–ї(–∞):–Ї –њ—А–Є–Љ–µ—А—Г –Ї–Њ–і:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
dim massive(40000,40000) as byte
–≤—Л–і–∞—Б—В –Њ—И–Є–±–Ї—Г "Out of memory".
–Т—Л–і–∞—Б—В. –Т —Б—А–µ–і–µ VB6, –Є–±–Њ –њ—А–Њ–≥—А–∞–Љ–Љ–µ, –љ–∞–њ–∞—А—Г —Б–Њ —Б—А–µ–і–Њ–є (–Њ–љ–Є –±—Г–і—Г—В –≤ –Њ–і–љ–Њ–Љ –њ—А–Њ—Ж–µ—Б—Б–µ), –њ–∞–Љ—П—В–Є –≤ 2 –У–± –і–µ–є—Б—В–≤–Є—В–µ–ї—М–љ–Њ –љ–µ —Е–≤–∞—В–Є—В. –Т —Б–Ї–Њ–Љ–њ–Є–ї–Є—А–Њ–≤–∞–љ–љ–Њ–Љ –≤–Є–і–µ –Њ—В–і–µ–ї—М–љ–Њ –Њ—В —Б—А–µ–і—Л - —А–∞–±–Њ—В–∞—В—М –±—Г–і–µ—В.
(P.S. –Ъ–∞–Ї –≤—Л—И–µ –Њ–±—К—П—Б–љ–Є–ї –•–∞–Ї–µ—А - –љ–µ –≤—Б–µ–≥–і–∞ –Є –љ–µ –≤–µ–Ј–і–µ)
kugeod –њ–Є—Б–∞–ї(–∞):–І—В–Њ–±—Л –Њ–±—А–∞–±–∞—В—Л–≤–∞—В—М –Љ–∞—В—А–Є—Ж—Л 80000 –љ–∞ 80000. –Т–Њ–Ј–Љ–Њ–ґ–љ–Њ –ї–Є —Н—В–Њ?
–Т–Њ–Ј–Љ–Њ–ґ–љ–Њ. –° –њ–Њ–Љ–Њ—Й—М—О —И–µ–є–і–µ—А–Њ–≤ –Є –±–Њ–ї–µ–µ —Б–Њ–≤—А–µ–Љ–µ–љ–љ–Њ–≥–Њ –ѓ–Я –і–ї—П 64-—Е —А–∞–Ј—А—П–і–љ—Л—Е —Б–Є—Б—В–µ–Љ.
–Х–ґ–µ–ї–Є –њ—А–Є–љ—Ж–Є–њ–Є–∞–ї–µ–љ VB6 - –Ј–∞–±—Л—В—М –њ—А–Њ —Б–Ї–Њ—А–Њ—Б—В—М –Њ–±—А–∞–±–Њ—В–Ї–Є –Є –њ—А–Њ–≥—А–∞–Љ–Љ–љ–Њ –Њ—А–≥–∞–љ–Є–Ј–Њ–≤—Л–≤–∞—В—М —Б–≤–Њ–є swap —Д–∞–є–ї, –Є–ї–Є –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ (–Ї–∞–Ї –≤ VB6 —А–∞–±–Њ—В–∞—В—М —Б —Д–∞–є–ї–Њ–Љ, —А–∞–Ј–Љ–µ—А–Њ–Љ –±–Њ–ї—М—И–µ 4-—Е –Є –і–∞–ґ–µ 2-—Е –≥–Є–≥–∞–±–∞–є—В, —П –њ—А–µ–і—Б—В–∞–≤–ї—П—О –њ–ї–Њ—Е–Њ). –Э–Њ —Н—В–Њ, –Ї–∞–Ї –≥–Њ–≤–Њ—А–Є—В—Б—П, –і–Њ–ї–≥–Њ, –і–Њ—А–Њ–≥–Њ –Є ... –ї—Г—З—И–µ –њ–Њ—Б–Љ–Њ—В—А–µ—В—М –≤ —Б—В–Њ—А–Њ–љ—Г SQL (–Э–Њ –њ—А–Є —Н—В–Њ–Љ –≤—Б–µ —А–∞–≤–љ–Њ –њ—А–Є–і–µ—В—Б—П —А–∞–±–Њ—В–∞—В—М —Б "–њ–Њ—А—Ж–Є—П–Љ–Є" –і–∞–љ–љ—Л—Е –Є –њ–µ—А–µ—Б–Љ–∞—В—А–Є–≤–∞—В—М –∞—А—Е–Є—В–µ–Ї—В—Г—А—Г –њ—А–Њ–≥—А–∞–Љ–Љ—Л). –Ы–µ—В 15 –љ–∞–Ј–∞–і –≤—Б—В—А–µ—З–∞–ї —Б–µ—А—М–µ–Ј–љ—Г—О –њ—А–Њ–≥—А–∞–Љ–Љ—Г-–і–Њ–њ–Њ–ї–љ–µ–љ–Є–µ –і–ї—П DataMine, –њ–Є—Б–∞–љ–љ—Г—О –љ–∞ VBA, –Є –њ–Њ–ї—М–Ј–Њ–≤–∞–≤—И—Г—О MSSQL –і–ї—П –Њ–±—А–∞–±–Њ—В–Ї–Є –±–Њ–ї—М—И–Є—Е (–Љ–Є–ї–ї–Є–Њ–љ—Л 3-—Е –Љ–µ—А–љ—Л—Е —В–Њ—З–µ–Ї) –і–∞–љ–љ—Л—Е. –Ґ—Г–ґ–Є–ї–∞—Б—М, –і—Г–Љ–∞–ї–∞, –љ–Њ —Б–њ—А–∞–≤–ї—П–ї–∞—Б—М.
–Т –Њ—Б—В–∞–ї—М–љ–Њ–Љ, –Њ–њ—П—В—М-–ґ–µ, –≤—Л—И–µ - –•–∞–Ї–µ—А –≤—Б–µ –Њ—З–µ–љ—М –і–Њ—Б–Ї–Њ–љ–∞–ї—М–љ–Њ –Њ–±—К—П—Б–љ–Є–ї. –Ю—Б–љ–Њ–≤–љ–Њ–є —Г–њ–Њ—А –љ–∞ "–њ—А–Є —Н—В–Њ–Љ –≤—Б–µ —А–∞–≤–љ–Њ –њ—А–Є–і–µ—В—Б—П —А–∞–±–Њ—В–∞—В—М —Б "–њ–Њ—А—Ж–Є—П–Љ–Є" –і–∞–љ–љ—Л—Е –Є –њ–µ—А–µ—Б–Љ–∞—В—А–Є–≤–∞—В—М –∞—А—Е–Є—В–µ–Ї—В—Г—А—Г –њ—А–Њ–≥—А–∞–Љ–Љ—Л"
–°–Њ–Њ–±—Й–µ–љ–Є–є: 11
• –°—В—А–∞–љ–Є—Ж–∞ 1 –Є–Ј 1
–Т–µ—А–љ—Г—В—М—Б—П –≤ Visual Basic 1вАУ6
–Ъ—В–Њ —Б–µ–є—З–∞—Б –љ–∞ –Ї–Њ–љ—Д–µ—А–µ–љ—Ж–Є–Є
–°–µ–є—З–∞—Б —Н—В–Њ—В —Д–Њ—А—Г–Љ –њ—А–Њ—Б–Љ–∞—В—А–Є–≤–∞—О—В: SemrushBot –Є –≥–Њ—Б—В–Є: 6