

–У–Њ–≤–Њ—А–Є—В—М –Њ —А–∞—Б–њ—А–Њ—Б—В—А–∞–љ—С–љ–љ–Њ—Б—В–Є —Б–њ–Є—Б–Ї–Њ–≤ –љ–µ –њ—А–Є—Е–Њ–і–Є—В—Б—П. –°–њ–Є—Б–Њ–Ї —Е—А–∞–љ–Є—В –≤–љ—Г—В—А–Є —Б–µ–±—П –і–∞–љ–љ—Л–µ, –Ї–Њ—В–Њ—А—Л–µ –Њ—В–Њ–±—А–∞–ґ–∞–µ—В. –Э–Њ –Ј–∞ —А–µ–і–Ї–Є–Љ –Є—Б–Ї–ї—О—З–µ–љ–Є–µ–Љ, —Б–њ–Є—Б–Њ–Ї –љ–µ —П–≤–ї—П–µ—В—Б—П –њ–µ—А–≤–Є—З–љ—Л–Љ –Є—Б—В–Њ—З–љ–Є–Ї–Њ–Љ –і–∞–љ–љ—Л—Е, –Њ–љ–Є –≤ –љ–µ–≥–Њ –Ї–Њ–њ–Є—А—Г—О—В—Б—П –Є–Ј —В–∞–Ї–Њ–≤–Њ–≥–Њ, –∞ –Ј–∞—В–µ–Љ, –∞–Ї—В—Г–∞–ї—М–љ–Њ—Б—В—М —Б–Ї–Њ–њ–Є—А–Њ–≤–∞–љ–љ—Л—Е –і–∞–љ–љ—Л—Е, —В–Њ –µ—Б—В—М –Є—Е —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Є–µ —В–µ–Ї—Г—Й–Є–Љ –і–∞–љ–љ—Л–Љ –Є–Ј –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞ —Б—В–∞–љ–Њ–≤–Є—В—Б—П —Б–Њ–Љ–љ–Є—В–µ–ї—М–љ–Њ–є, –њ–Њ—Н—В–Њ–Љ—Г –≤–Њ–Ј–љ–Є–Ї–∞–µ—В –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ—Б—В—М –Њ–±–љ–Њ–≤–ї—П—В—М —Б–њ–Є—Б–Њ–Ї.
–Ы–Є–±–Њ –љ–∞–њ—А–Њ—В–Є–≤ —Б–њ–Є—Б–Ї–∞ —А–∞—Б–њ–Њ–ї–Њ–ґ–µ–љ–∞ –Ї–љ–Њ–њ–Ї–∞ ¬Ђ–Ю–±–љ–Њ–≤–Є—В—М¬ї, –ї–Є–±–Њ –Њ–±–љ–Њ–≤–ї–µ–љ–Є–µ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –њ–µ—А–Є–Њ–і–Є—З–љ–Њ (–љ–∞–њ—А–Є–Љ–µ—А —А–∞–Ј –≤ 30 —Б–µ–Ї—Г–љ–і), –ї–Є–±–Њ –њ–µ—А–≤–Є—З–љ—Л–є –Є—Б—В–Њ—З–љ–Є–Ї (–љ–∞–њ—А–Є–Љ–µ—А —Б–µ—А–≤–µ—А) —Б–Њ–Њ–±—Й–∞–µ—В, —З—В–Њ –њ–Њ—А–∞ –±—Л –Њ–±–љ–Њ–≤–Є—В—М —Б–њ–Є—Б–Њ–Ї. –Э–µ —Н—В–Њ –≤–∞–ґ–љ–Њ.
–°—Г—В—М –њ—А–Њ–±–ї–µ–Љ—Л
–Ъ —Б–Њ–ґ–∞–ї–µ–љ–Є—О, –±–Њ–ї—М—И–Є–љ—Б—В–≤–Њ –њ—А–Њ–≥—А–∞–Љ–Љ–Є—Б—В–Њ–≤ –і–µ–ї–∞—О—В –Њ–±–љ–Њ–≤–ї–µ–љ–Є–µ —Б–∞–Љ—Л–Љ ¬Ђ–≥—А—П–Ј–љ—Л–Љ¬ї –Є –≥—А—Г–±—Л–Љ —Б–њ–Њ—Б–Њ–±–Њ–Љ: —Б–љ–∞—З–∞–ї–∞ –њ–Њ–ї–љ–Њ—Б—В—М—О –Њ—З–Є—Й–∞—О—В —Б–њ–Є—Б–Њ–Ї, –Ј–∞—В–µ–Љ –і–Њ–±–∞–≤–ї—П—О—В –≤ –љ–µ–≥–Њ —Н–ї–µ–Љ–µ–љ—В—Л, –њ–Њ–ї—Г—З–µ–љ–љ—Л–µ –Њ—В –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞.
–Ф–∞–≤–∞–є—В–µ —А–∞–Ј–±–µ—А—С–Љ, –њ–Њ—З–µ–Љ—Г —Н—В–Њ –њ–ї–Њ—Е–Њ –Є –љ–µ–Ї—А–∞—Б–Є–≤–Њ:
- –Т –њ–µ—А–≤—Г—О –Њ—З–µ—А–µ–і—М —Н—В–Њ –љ–µ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –њ—А–Є–љ—Ж–Є–њ—Г –ї–µ–љ–Є. –Х—Б–ї–Є —Б–њ–Є—Б–Њ–Ї –Њ—В–Њ–±—А–∞–ґ–∞–µ—В —Д–∞–є–ї—Л –≤ –Ї–∞–Ї–Њ–є-—В–Њ –њ–∞–њ–Ї–µ, –Є –њ–∞—А—Г —Д–∞–є–ї–Њ–≤ –Ї—В–Њ-—В–Њ —Г–і–∞–ї–Є–ї, –љ–µ—В —Б–Њ–≤–µ—А—И–µ–љ–љ–Њ –љ–Є–Ї–∞–Ї–Њ–≥–Њ —Б–Љ—Л—Б–ї–∞ —Г–і–∞–ї—П—В—М 1998 —Н–ї–µ–Љ–µ–љ—В–Њ–≤ —Б–њ–Є—Б–Ї–∞ –Є–Ј 2000 —Б—Г—Й–µ—Б—В–≤—Г—О—Й–Є—Е, —З—В–Њ–±—Л –њ–Њ—В–Њ–Љ –Ј–∞–љ–Њ–≤–Њ –і–Њ–±–∞–≤–Є—В—М 1998 —Г–і–∞–ї—С–љ–љ—Л—Е —Н–ї–µ–Љ–µ–љ—В–Њ–≤. –≠—В–Њ –Љ–љ–Њ–≥–Њ –і–µ–є—Б—В–≤–Є–є, –Љ–љ–Њ–≥–Њ –±–µ—Б–њ–Њ–ї–µ–Ј–љ—Л—Е –і–µ–є—Б—В–≤–Є–є. –Ь–∞–ї–Њ –і–µ–є—Б—В–≤–Є–є вАФ —Н—В–Њ —Г–і–∞–ї–Є—В—М 2 —Н–ї–µ–Љ–µ–љ—В–∞ –Є–Ј 2000. –Р –љ–µ —Г–і–∞–ї–Є—В—М 2000 –Є –і–Њ–±–∞–≤–Є—В—М 1998.
- –Х—Б–ї–Є —Б–њ–Є—Б–Њ–Ї вАФ –≥—А–∞—Д–Є—З–µ—Б–Ї–Є–є, –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М —Г–≤–Є–і–Є—В —Г–ґ–∞—Б–љ—Л–є –≤–Є–Ј—Г–∞–ї—М–љ—Л–є —Б–њ–µ—Ж—Н—Д—Д–µ–Ї—В, –Ј–∞–Ї–ї—О—З–∞—О—Й–Є–є—Б—П –≤ –Љ–µ—А—Ж–∞–љ–Є–Є.
- –Х—Б–ї–Є –≤–≤–µ—Б—В–Є —В–∞–Ї–Њ–µ –њ–Њ–љ—П—В–Є–µ, –Ї–∞–Ї —Ж–µ–љ–∞ –і–µ–є—Б—В–≤–Є—П вАФ —В–Њ –і–Њ–±–∞–≤–ї–µ–љ–Є–µ –≤—Б–µ–≥–і–∞ –і–Њ—А–Њ–ґ–µ, —З–µ–Љ —Г–і–∞–ї–µ–љ–Є–µ. –Я–Њ—З—В–Є –≤—Б–µ–≥–і–∞ –Є—В–µ—А–∞—В–Є–≤–љ–Њ–µ –і–Њ–±–∞–≤–ї–µ–љ–Є–µ —В—А–µ–±—Г–µ—В –≤—Л–і–µ–ї–µ–љ–Є–µ –≤—Б—С –љ–Њ–≤–Њ–є –Є –љ–Њ–≤–Њ–є –њ–∞–Љ—П—В–Є. –Т —Б–ї—Г—З–∞–µ –≤—Л–і–µ–ї–µ–љ–Є—П –Њ–і–Є–љ–∞–Ї–Њ–≤–Њ–≥–Њ —Б—Г–Љ–Љ–∞—А–љ–Њ–≥–Њ –Њ–±—К—С–Љ–∞, –≤—Л–і–µ–ї–µ–љ–Є–µ –Љ–µ–ї–Ї–Є–Љ–Є –Ї—Г—Б–Њ—З–Ї–∞–Љ–Є –≤—Б–µ–≥–і–∞ –љ–µ—Н—Д—Д–µ–Ї—В–Є–≤–љ–µ–µ, —З–µ–Љ –Њ–і–љ–Є–Љ —А–∞–Ј–Њ–Љ. –Я–Њ—В–Њ–Љ—Г —З—В–Њ –њ–∞–Љ—П—В—М —Д—А–∞–≥–Љ–µ–љ—В–Є—А—Г–µ—В—Б—П, –љ—Г–ґ–љ–Њ –Є—Б–Ї–∞—В—М —Б–≤–Њ–±–Њ–і–љ—Л–µ —А–µ–≥–Є–Њ–љ—Л –Є–ї–Є –Ј–∞–љ–Є–Љ–∞—В—М—Б—П –і–µ—Д—А–∞–≥–Љ–µ–љ—В–∞—Ж–Є–µ–є. –£–і–∞–ї–µ–љ–Є–µ –љ–µ —В—А–µ–±—Г–µ—В –љ–Є—З–µ–≥–Њ —В–∞–Ї–Њ–≥–Њ. –С–Њ–ї–µ–µ —В–Њ–≥–Њ, —Г–і–∞–ї–µ–љ–Є–µ –≤—Б–µ–≥–і–∞ –Љ–Њ–ґ–љ–Њ –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞—В—М, –і–µ–ї–∞—П –≤–Љ–µ—Б—В–Њ —Б–∞–Љ–Њ–≥–Њ —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–≥–Њ —Г–і–∞–ї–µ–љ–Є—П –≤—Л—Б—В–∞–≤–ї–µ–љ–Є–µ –Њ—В–Љ–µ—В–Ї–Є ¬Ђ—Г–і–∞–ї–µ–љ–Њ¬ї, –Є –Њ—В–Ї–ї–∞–і—Л–≤–∞–љ–Є–µ–Љ —Б–∞–Љ–Њ–≥–Њ —Д–Є–Ј. —Г–і–∞–ї–µ–љ–Є—П –і–Њ –±–ї–∞–≥–Њ–њ—А–Є—П—В–љ–Њ–≥–Њ –≤—А–µ–Љ–µ–љ–Є.
- –Х—Б–ї–Є —Б–њ–Є—Б–Њ–Ї вАФ —Н–ї–µ–Љ–µ–љ—В –Є–љ—В–µ—А—Д–µ–є—Б–∞, –≤ –Ї–Њ—В–Њ—А–Њ–Љ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ –≤—Л–і–µ–ї–µ–љ–Є–µ –њ—Г–љ–Ї—В–Њ–≤, —В–Њ –≤—Л–і–µ–ї–µ–љ–Є–µ –Њ–±—Л—З–љ–Њ —Б–±—А–∞—Б—Л–≤–∞–µ—В—Б—П, –њ–Њ—В–Њ–Љ—Г —З—В–Њ —Б–њ–µ—А–≤–∞ —Б–њ–Є—Б–Њ–Ї –њ–Њ–ї–љ–Њ—Б—В—М—О –Њ—З–Є—Й–∞–µ—В—Б—П. –°–∞–Љ —Б–њ–Є—Б–Њ–Ї –љ–µ —Б–њ–Њ—Б–Њ–±–µ–љ –і–Њ–≥–∞–і–∞—В—М—Б—П, —З—В–Њ —Н–ї–µ–Љ–µ–љ—В, –Ї–Њ—В–Њ—А—Л–є –±—Л–ї –≤—Л–і–µ–ї–µ–љ–љ—Л–Љ –љ–∞ –Љ–Њ–Љ–µ–љ—В —Г–і–∞–ї–µ–љ–Є—П, –≤–Њ—В-–≤–Њ—В –≤–љ–Њ–≤—М –±—Г–і–µ—В –і–Њ–±–∞–≤–ї–µ–љ: –≤–љ–Њ–≤—М –і–Њ–±–∞–≤–ї–µ–љ–љ—Л–є —Н–ї–µ–Љ–µ–љ—В –љ–µ –њ–Њ–ї—Г—З–Є—В –≤—Л–і–µ–ї–µ–љ–Є—П.
–Т –Њ–±—Й–µ–Љ, —Н—В–Њ—В –≤–∞—А–Є–∞–љ—В –њ–ї–Њ—Е –≤—Б–µ–Љ: –≤—А–µ–Љ–µ–љ–µ–Љ –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П, —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ—Б—В—М—О, –≤—Л—З–Є—Б–ї–Є—В–µ–ї—М–љ–Њ–є —Б–ї–Њ–ґ–љ–Њ—Б—В—М—О –≤—Б–µ–є –њ—А–Њ—Ж–µ–і—Г—А—Л, –≥—А–∞—Д–Є—З–µ—Б–Ї–Є–Љ–Є —Б–њ–µ—Ж—Н—Д—Д–µ–Ї—В–∞–Љ–Є –Є –њ—А–Њ—З–Є–Љ–Є –љ–µ–і–Њ—Б—В–∞—В–Ї–∞–Љ–Є.
–Я–µ—А–≤—Л–є —И–∞–≥ —Г–ї—Г—З—И–µ–љ–Є—П
–Т–Љ–µ—Б—В–Њ —В–Њ–≥–Њ, —З—В–Њ–±—Л –њ–Њ–ї–љ–Њ—Б—В—М—О –Њ—З–Є—Й–∞—В—М —Б–њ–Є—Б–Њ–Ї, –∞ –Ј–∞—В–µ–Љ –Ј–∞–њ—А–∞—И–Є–≤–∞—В—М –љ–Њ–≤—Л–µ –і–∞–љ–љ—Л–µ –Є –Ј–∞–њ–Њ–ї–љ—П—В—М –Є–Љ–Є —В–µ–њ–µ—А—М —Г–ґ–µ –њ—Г—Б—В–Њ–є —Б–њ–Є—Б–Њ–Ї, —Б–і–µ–ї–∞–µ–Љ –Ї–Њ–µ-—З—В–Њ —З—Г—В—М –±–Њ–ї–µ–µ –Є–љ—В–µ–ї–ї–µ–Ї—В—Г–∞–ї—М–љ–Њ–µ. –Ь—Л –љ–µ –±—Г–і–µ–Љ –Њ—З–Є—Й–∞—В—М —Б–њ–Є—Б–Њ–Ї –њ–µ—А–≤—Л–Љ –і–µ–ї–Њ–Љ. –Т–Љ–µ—Б—В–Њ —Н—В–Њ–≥–Њ, –Љ—Л –њ–Њ–Љ–µ—З–∞–µ–Љ –≤—Б–µ —Н–ї–µ–Љ–µ–љ—В—Л —Б–њ–Є—Б–Ї–∞ —Б–њ–µ—Ж–Є–∞–ї—М–љ—Л–Љ —Д–ї–∞–≥–Њ–Љ, –љ–∞–њ—А–Є–Љ–µ—А, –љ–∞–Ј–Њ–≤—С–Љ –µ–≥–Њ ¬Ђ–≥—А—П–Ј–љ—Л–є¬ї (¬Ђdirty¬ї). –Ф–∞–ї–µ–µ –Љ—Л –Ј–∞–њ—А–∞—И–Є–≤–∞–µ–Љ –і–∞–љ–љ—Л–µ –Є–Ј –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞. –Ф–ї—П –Ї–∞–ґ–і–Њ–≥–Њ –њ—А–Є—И–µ–і—И–µ–≥–Њ –Њ—В –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞ —Н–ї–µ–Љ–µ–љ—В–∞, –Љ—Л –Є—Й–µ–Љ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й–Є–є —Н–ї–µ–Љ–µ–љ—В –≤ —Б–њ–Є—Б–Ї–µ. –Х—Б–ї–Є –Њ–љ —В–∞–Љ —Г–ґ–µ –µ—Б—В—М, —Б–љ–Є–Љ–∞–µ–Љ —Б —Н—В–Њ–≥–Њ —Н–ї–µ–Љ–µ–љ—В–∞ —Д–ї–∞–≥ ¬Ђ–≥—А—П–Ј–љ—Л–є¬ї. –Х—Б–ї–Є –µ–≥–Њ —В–∞–Љ –љ–µ—В вАФ –і–Њ–±–∞–≤–ї—П–µ–Љ –µ–≥–Њ —Б–Њ —Б–љ—П—В—Л–Љ —Д–ї–∞–≥–Њ–Љ. –Ґ–Њ–ї—М–Ї–Њ –Ї–Њ–≥–і–∞ –Љ—Л –Њ–±—А–∞–±–Њ—В–∞–ї–Є –≤—Б–µ –њ—А–Є—И–µ–і—И–Є–µ –Њ—В –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞ —Н–ї–µ–Љ–µ–љ—В—Л, –Љ—Л –њ—А–Њ—Е–Њ–і–Є–Љ—Б—П –њ–Њ –≤—Б–µ–Љ—Г –љ–∞—И–µ–Љ—Г —Б–њ–Є—Б–Ї—Г –Є —Г–і–∞–ї—П–µ–Љ –≤—Б–µ —В–µ –њ—Г–љ–Ї—В—Л, —Г –Ї–Њ—В–Њ—А—Л—Е —Д–ї–∞–≥ ¬Ђ–≥—А—П–Ј–љ—Л–є¬ї –Њ—Б—В–∞–ї—Б—П —Г—Б—В–∞–љ–Њ–≤–ї–µ–љ–љ—Л–Љ.
–Я–ї—О—Б—Л –њ–Њ–і—Е–Њ–і–∞:
- –Ь—Л –љ–µ —Г–і–∞–ї—П–µ–Љ —Н–ї–µ–Љ–µ–љ—В –Є–Ј —Б–њ–Є—Б–Ї–∞, –µ—Б–ї–Є —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й–Є–є –µ–Љ—Г —Н–ї–µ–Љ–µ–љ—В –Є–Ј –ґ–Є–Ј–љ–Є –љ–Є–Ї—Г–і–∞ –љ–µ –і–µ–ї—Б—П. –Ш–Ј —Б–њ–Є—Б–Ї–∞ —Г–і–∞–ї—П—О—В—Б—П —В–Њ–ї—М–Ї–Њ —В–µ —Н–ї–µ–Љ–µ–љ—В—Л, –Ї–Њ—В–Њ—А—Л–µ –Є—Б—З–µ–Ј–ї–Є –≤ –ґ–Є–Ј–љ–Є, —В–Њ –µ—Б—В—М –љ–µ –±—Л–ї–Є –њ–Њ–ї—Г—З–µ–љ—Л –Њ—В –њ–µ—А–≤–Њ–Є—Б—В–Њ—З–љ–Є–Ї–∞. –Э–µ—В –ї–Є—И–љ–Є—Е —В—А—Г–і–Њ—С–Љ–Ї–Є—Е –і–µ–є—Б—В–≤–Є–є.
- –Ъ–∞–Ї —Б–ї–µ–і—Б—В–≤–Є–µ, –µ—Б–ї–Є –Ї–∞–Ї–Њ–є-—В–Њ –Є–Ј –Њ—Б—В–∞–≤—И–Є—Е—Б—П —Н–ї–µ–Љ–µ–љ—В–Њ–Љ –±—Л–ї –≤—Л–і–µ–ї–µ–љ, –Њ–љ –Њ—Б—В–∞–љ–µ—В—Б—П –≤—Л–і–µ–ї–µ–љ. –Х—Б–ї–Є —Н—В–Њ ListView, –Є –њ—А–Є–≤—П–Ј–Ї–∞ –Ї —Б–µ—В–Ї–µ –≤—Л–Ї–ї—О—З–µ–љ–∞, –Є —Н–ї–µ–Љ–µ–љ—В –±—Л–ї —Б–і–≤–Є–љ—Г—В –Њ—В–љ–Њ—Б–Є—В–µ–ї—М–љ–Њ —Б–µ—В–Ї–Є, –Њ–љ –Њ—Б—В–∞–љ–µ—В—Б—П —Б–і–≤–Є–љ—Г—В—Л–Љ –љ–∞ —В—Г –ґ–µ –≤–µ–ї–Є—З–Є–љ—Г.
–Ь–Є–љ—Г—Б—Л –њ–Њ–і—Е–Њ–і–∞:
- –Х—Б–ї–Є –≤ —Б–њ–Є—Б–Ї–µ –љ–∞ –Љ–Њ–Љ–µ–љ—В –љ–∞—З–∞–ї–∞ –Њ–±–љ–Њ–≤–ї–µ–љ–Є—П –±—Л–ї–Њ M —Н–ї–µ–Љ–µ–љ—В–Њ–≤, –∞ –њ—А–Є –Њ–±–љ–Њ–≤–ї–µ–љ–Є–Є –њ–Њ—Б—В—Г–њ–Є–ї–∞ –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—П –Њ–± N —Н–ї–µ–Љ–µ–љ—В–∞—Е, —В–Њ –љ—Г–ґ–µ–љ–Њ, –≤ –Њ–±—Й–µ–Љ —Б–ї—Г—З–∞–µ, –њ—А–Њ–Є–Ј–≤–µ—Б—В–Є M √Ч N –Њ–њ–µ—А–∞—Ж–Є–є –њ–Њ–Є—Б–Ї–∞/—Б–≤–µ—А–Ї–Є.
–ѓ –њ–Њ–љ–Є–Љ–∞—О, —З—В–Њ –Љ–љ–Њ–≥–Є–µ –љ–µ –і–µ–ї–∞—О—В —В–∞–Ї, –њ–Њ—В–Њ–Љ—Г —З—В–Њ —Н—В–Њ —В—А–µ–±—Г–µ—В –љ–∞–њ–Є—Б–∞—В—М –±–Њ–ї—М—И–µ –Ї–Њ–і–∞, –Є –њ—А–Є —В–Њ–Љ, –Є–Љ –Ї–∞–ґ–µ—В—Б—П, —З—В–Њ –њ–Њ–Є—Б–Ї —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Є—П –Љ–µ–ґ–і—Г —Н–ї–µ–Љ–µ–љ—В–Њ–Љ –љ–∞—И–µ–≥–Њ —Б–њ–Є—Б–Ї–∞ –Є —Н–ї–µ–Љ–µ–љ—В–Њ–Љ, –њ—А–Є—И–µ–і—И–Є–Љ –Њ—В –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞, –±—Г–і–µ—В –Њ—В–љ–Є–Љ–∞—В—М –±–Њ–ї—М—И–µ –≤—Л—З–Є—Б–ї–Є—В–µ–ї—М–љ—Л—Е –Њ–њ–µ—А–∞—Ж–Є–є, —З–µ–Љ –њ–Њ–ї–љ–Њ–µ –Њ–±–љ—Г–ї–µ–љ–Є–µ —Б–њ–Є—Б–Ї–∞ —Б –µ–≥–Њ –њ–Њ—Б–ї–µ–і—Г—О—Й–Є–Љ –Ј–∞–њ–Њ–ї–љ–µ–љ–Є–µ–Љ –љ–Њ–≤—Л–Љ–Є –∞–Ї—В—Г–∞–ї—М–љ—Л–Љ –і–∞–љ–љ—Л–Љ–Є —Б –љ—Г–ї—П. –≠—В–Њ –≤–µ—А–љ–Њ —А–∞–Ј–≤–µ —З—В–Њ –і–ї—П –Љ–∞—Б—Б–Є–≤–Њ–≤. –Ф–ї—П —Б–њ–Є—Б–Ї–Њ–≤ (–≤ –њ—А–Њ–≥—А–∞–Љ–Љ–Є—Б—В—Б–Ї–Њ–Љ —Б–Љ—Л—Б–ї–µ —Б–ї–Њ–≤–∞), –∞ –Њ—Б–Њ–±–µ–љ–љ–Њ –і–ї—П —Б–њ–Є—Б–Ї–Њ–≤ –≤ —Б–Љ—Л—Б–ї–µ –≥—А–∞—Д–Є—З–µ—Б–Ї–Њ–≥–Њ —Н–ї–µ–Љ–µ–љ—В–∞ –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М—Б–Ї–Њ–≥–Њ –Є–љ—В–µ—А—Д–µ–є—Б–∞ —Н—В–Њ –њ–Њ—З—В–Є –≤—Б–µ–≥–і–∞ –љ–µ–њ—А–∞–≤–і–∞. –Т–љ–Є–Љ–∞–љ–Є–µ: –і–µ—И–µ–≤–ї–µ –Њ—В–Љ–µ—В–Є—В—М ¬Ђ—Г—Б—В–∞—А–µ–≤—И–Є–µ¬ї —Н–ї–µ–Љ–µ–љ—В—Л –Є –Ј–∞—В–µ–Љ –Є—Е —А–∞–Ј–Њ–Љ —Г–і–∞–ї–Є—В—М, —З–µ–Љ –Њ–±–љ—Г–ї—П—В—М —Б–њ–Є—Б–Њ–Ї, –Є –Ј–∞–њ–Њ–ї–љ—П—В—М –Ј–∞–љ–Њ–≤–Њ.
–Т –Њ–±—Й–µ–Љ, —Н—В–Њ—В —Б–њ–Њ—Б–Њ–± —Б–ї–µ–і—Г–µ—В –њ—А–Є–Љ–µ–љ—П—В—М –≤—Б–µ–≥–і–∞, –Ї–Њ–≥–і–∞ –Њ–њ–µ—А–∞—Ж–Є–є –њ–Њ–Є—Б–Ї–∞/—Б—А–∞–≤–љ–µ–љ–Є—П –і–µ—И–µ–≤–ї–µ, —З–µ–Љ –Њ–њ–µ—А–∞—Ж–Є—П –≤—Б—В–∞–≤–Ї–Є –љ–Њ–≤–Њ–≥–Њ —Н–ї–µ–Љ–µ–љ—В–∞. –Р –Њ–љ–∞ –њ–Њ—З—В–Є –≤—Б–µ–≥–і–∞ –і–µ—И–µ–≤–ї–µ. –Я–Њ—В–Њ–Љ—Г —З—В–Њ –Њ–±—Л—З–љ–Њ —Н–ї–µ–Љ–µ–љ—В, —Н—В–Њ –Є–і–µ–љ—В–Є—Д–Є–Ї–∞—В–Њ—А, –Є –µ—Й—С –Ї—Г—З–∞ –і–∞–љ–љ—Л—Е. –Ф–ї—П –њ–Њ–Є—Б–Ї–∞/—Б—А–∞–≤–љ–µ–љ–Є—П –љ—Г–ґ–љ–∞ —А–∞–±–Њ—В–∞ —В–Њ–ї—М–Ї–Њ —Б –Є–і–µ–љ—В–Є—Д–Є–Ї–∞—В–Њ—А–Њ–Љ, –∞ –і–ї—П –і–Њ–±–∞–≤–ї–µ–љ–Є—П –љ—Г–ґ–љ–∞ —А–∞–±–Њ—В–∞ —Б –љ–Є–Љ –Є –µ—Й—С —Б–Њ –≤—Б–µ–є —В–Њ–є –Ї—Г—З–µ–є –і–∞–љ–љ—Л—Е, –Ї–Њ—В–Њ—А–∞—П —Б –Є–і–µ–љ—В–Є—Д–Є–Ї–∞—В–Њ—А–Њ–Љ —Б–≤—П–Ј–∞–љ–∞.
–Т—В–Њ—А–Њ–є —И–∞–≥ —Г–ї—Г—З—И–µ–љ–Є—П
–Э–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ, —Б–њ–Њ—Б–Њ–± —Б —Б–Њ—Б—В–∞–≤–ї–µ–љ–Є–µ–Љ —Б–њ–Є—Б–Ї–∞ ¬Ђ—Г—Б—В–∞—А–µ–≤—И–Є—Е —Н–ї–µ–Љ–µ–љ—В–Њ–≤¬ї –≥–Њ—А–∞–Ј–і–Њ –ї—Г—З—И–µ, —З–µ–Љ —Б–њ–Њ—Б–Њ–± ¬Ђ–≤—Б—С —А–∞–Ј—А—Г—И–Є—В—М –Є –њ–Њ—Б—В—А–Њ–Є—В—М –Ј–∞–љ–Њ–≤–Њ¬ї. –Э–Њ –Є –Њ–љ –њ–ї–Њ—Е, –њ–Њ—В–Њ–Љ—Г —З—В–Њ —Б–Њ—Б—В–∞–≤–ї–µ–љ–Є–µ —Б–њ–Є—Б–Ї–∞ —В—А–µ–±—Г–µ—В –Љ–љ–Њ–≥–Њ –Њ–њ–µ—А–∞—Ж–Є–є –њ–Њ–Є—Б–Ї–∞/—Б—А–∞–≤–љ–µ–љ–Є—П. –Э–Њ —З–∞—Й–µ –≤—Б–µ–≥–Њ –µ—Б—В—М –Њ–±—Б—В–Њ—П—В–µ–ї—М—Б—В–≤–Њ, –Ї–Њ—В–Њ—А—Л–µ –њ–Њ–Ј–≤–Њ–ї—П—О—В –Є –Њ—В —Н—В–Њ–≥–Њ —Б–њ–Њ—Б–Њ–±–∞ –Њ—В–Ї–∞–Ј–∞—В—М—Б—П –≤ –њ–Њ–ї—М–Ј—Г —З–µ–≥–Њ-—В–Њ –±–Њ–ї–µ–µ —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ–≥–Њ.
–Ф–µ–ї–Њ–Љ –≤ —В–Њ–Љ, —З—В–Њ –≥–Њ—А–∞–Ј–і–Њ —З–∞—Й–µ —Н—В–Њ –Є–Љ–µ–љ–љ–Њ —В–∞–Ї: –і–∞–љ–љ—Л—Е –Њ—В –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞ –њ—А–Є—Е–Њ–і—П—В –≤ —Г–њ–Њ—А—П–і–Њ—З–µ–љ–љ–Њ–Љ –≤–Є–і–µ, –∞ –љ–µ —Б–Њ–≤–µ—А—И–µ–љ–љ–Њ —Б–ї—Г—З–∞–є–љ–Њ–Љ. –Э–∞–њ—А–Є–Љ–µ—А, –µ—Б–ї–Є –≤—Л –њ–µ—А–µ—З–Є—Б–ї—П–µ—В–µ —Д–∞–є–ї—Л –≤ –Ї–∞—В–∞–ї–Њ–≥–µ, –Є –љ–µ –≤–∞–ґ–љ–Њ, VB-—И–љ–Њ–є –ї–Є —Д—Г–љ–Ї—Ж–Є–µ–є Dir(), –Є–ї–Є WinAPI-—Д—Г–љ–Ї—Ж–Є—П–Љ–Є, —Б–њ–Є—Б–Њ–Ї —Д–∞–є–ї–Њ–≤ –≤–∞–Љ –Њ—В –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞ –±—Г–і–µ—В –њ—А–Є—Е–Њ–і–Є—В—М –≤ –∞–ї—Д–∞–≤–Є—В–љ–Њ–Љ –њ–Њ—А—П–і–Ї–µ. –Х—Б–ї–Є –њ–µ—А–≤–Є—З–љ—Л–є –Є—Б—В–Њ—З–љ–Є–Ї вАФ –С–Ф, –∞ –≤—Л –і–µ–ї–∞–µ—В–µ SQL-–Ј–∞–њ—А–Њ—Б вАФ —В–µ–Љ –ї—Г—З—И–µ, –Є–±–Њ SQL-–Ј–∞–њ—А–Њ—Б –њ–Њ–Ј–≤–Њ–ї—П–µ—В –≤–∞–Љ —Г–њ–Њ—А—П–і–Њ—З–Є—В—М –і–∞–љ–љ—Л–µ –ї—О–±—Л–Љ —Г–і–Њ–±–љ—Л–Љ –Њ–±—А–∞–Ј–Њ–Љ. –Ф–∞ –Є —Е—А–∞–љ—П—В—Б—П –і–∞–љ–љ—Л–µ –Њ–±—Л—З–љ–Њ —Г–њ–Њ—А—П–і–Њ—З–µ–љ–љ–Њ, –Є –Є–Љ–µ–љ–љ–Њ –њ–Њ—Н—В–Њ–Љ—Г —З–∞—Й–µ –≤—Б–µ–≥–Њ –Є –≤—Л–і–∞—О—В—Б—П –≤ —Е–Њ—А–Њ—И–µ–Љ –њ–Њ—А—П–і–Ї–µ, –∞ –љ–µ –∞–±—Л –Ї–∞–Ї.
–≠—В–Њ –Њ–±—Б—В–Њ—П—В–µ–ї—М—Б—В–≤–Њ –і–∞—С—В –љ–∞–Љ –і–Њ—Б—В–∞—В–Њ—З–љ–Њ –±–Њ–ї—М—И–Њ–µ –њ—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–Њ: —В–µ–њ–µ—А—М –љ–∞–Љ –љ–µ –љ—Г–ґ–љ–Њ —Б–Њ—Б—В–∞–≤–ї—П—В—М —Б–њ–Є—Б–Њ–Ї, –і–ї—П –Ї–Њ—В–Њ—А–Њ–≥–Њ –њ—А–Є—Е–Њ–і–Є–ї–Њ—Б—М –і–µ–ї–∞—В—М –Љ–љ–Њ–≥–Њ –Њ–њ–µ—А–∞—Ж–Є–є –њ–Њ–Є—Б–Ї–∞/—Б—А–∞–≤–љ–µ–љ–Є—П. –Ґ–Њ, —З—В–Њ –Љ—Л –±—Г–і–µ–Љ –њ—А–Є–Љ–µ–љ—П—В—М, —П –њ–Њ-—Б–≤–Њ–µ–Љ—Г –љ–∞–Ј—Л–≤–∞—О –Љ–µ—В–Њ–і–Њ–Љ –і–≤—Г—Е –Ї—Г—А—Б–Њ—А–Њ–≤. –Ю–і–Є–љ –Ї—Г—А—Б–Њ—А —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –≤—Л–±–Њ—А–Ї–µ –Є–Ј –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞, –Є –љ–∞–Љ –Љ–∞–ї–Њ –Є–љ—В–µ—А–µ—Б–µ–љ, –∞ –≤—В–Њ—А–Њ–є –Ї—Г—А—Б–Њ—А —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –љ–∞—И–µ–Љ—Г –Њ–±—Е–Њ–і—Г –љ–∞—И–µ–≥–Њ –ґ–µ —Б–њ–Є—Б–Ї–∞.
–Ъ–∞–Ї —П —Г –ґ–µ —Б–Ї–∞–Ј–∞–ї, —Б–њ–Њ—Б–Њ–± –њ–Њ–і—Е–Њ–і–Є—В —В–∞–Љ, –≥–і–µ –і–∞–љ–љ—Л–µ –≤—Л–і–∞—О—В—Б—П –њ–µ—А–≤–Є—З–љ—Л–Љ –Є—Б—В–Њ—З–љ–Є–Ї–Њ–Љ —Г–њ–Њ—А—П–і–Њ—З–µ–љ–љ–Њ. –°—В—А–Њ–≥–Њ –≥–Њ–≤–Њ—А—П, —Б–њ–Њ—Б–Њ–± –њ—А–Є–Љ–µ–љ–Є–Љ —В–∞–Ї, –≥–і–µ –ї—О–±—Л–µ –і–≤–∞ —Н–ї–µ–Љ–µ–љ—В–∞ –Љ–Њ–≥—Г—В –±—Л—В—М —Б—А–∞–≤–љ–µ–љ—Л, –Є –≥–і–µ –Њ—В–љ–Њ—И–µ–љ–Є–µ –њ–Њ—А—П–і–Ї–∞ —В—А–∞–љ–Ј–Є—В–Є–≤–љ–Њ. –Ы–Є–±–Њ —Б–∞–Љ–Є —Н–ї–µ–Љ–µ–љ—В—Л –і–Њ–ї–ґ–љ—Л –±—Л—В—М –ї–µ–≥–Ї–Њ —Б—А–∞–≤–љ–Є–≤—Л–Љ–Є, –ї–Є–±–Њ —Г —Н–ї–µ–Љ–µ–љ—В–Њ–≤ –і–Њ–ї–ґ–љ—Л –±—Л—В—М —Б—А–∞–≤–љ–Є–Љ—Л–µ –Є–і–µ–љ—В–Є—Д–Є–Ї–∞—В–Њ—А—Л, –ї–Є–±–Њ –≤ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Є–µ —Н–ї–µ–Љ–µ–љ—В–∞–Љ –і–Њ–ї–ґ–љ–Њ –±—Л—В—М –ї–µ–≥–Ї–Њ –њ–Њ—Б—В–∞–≤–Є—В—М –ї–µ–≥–Ї–Њ-–≤—Л—З–Є—Б–ї–Є–Љ—Л–є —Е–µ—И.
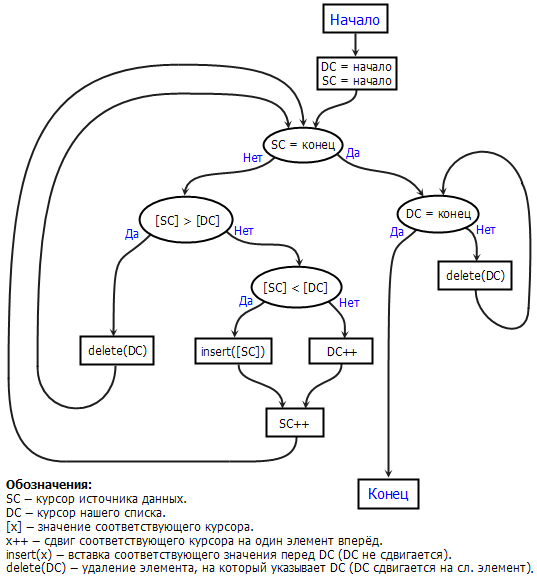
–Ы–Њ–≥–Є–Ї–∞ —А–∞–±–Њ—В —В–∞–Ї–∞—П:
- –Т –љ–∞—З–∞–ї–µ –Њ–±–љ–Њ–≤–ї–µ–љ–Є—П –Љ—Л —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞–µ–Љ –љ–∞—И –Ї—Г—А—Б–Њ—А –љ–∞ –њ–µ—А–≤—Л–є —Н–ї–µ–Љ–µ–љ—В –љ–∞—И–µ–≥–Њ —Б–њ–Є—Б–Ї–∞. –Э–∞—З–Є–љ–∞–µ–Љ –Є—В–µ—А–∞—В–Є–≤–љ–Њ –њ–Њ–ї—Г—З–∞—В—М —Н–ї–µ–Љ–µ–љ—В—Л –Њ—В –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞.
- –Я–Њ–ї—Г—З–∞–µ–Љ –Њ–і–Є–љ —Н–ї–µ–Љ–µ–љ—В –Њ—В –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞.
- –°—А–∞–≤–љ–Є–≤–∞–µ–Љ —Б —Н–ї–µ–Љ–µ–љ—В–Њ–Љ, –љ–∞ –Ї–Њ—В–Њ—А—Л–є —Г–Ї–∞–Ј—Л–≤–∞–µ—В –љ–∞—И –Ї—Г—А—Б–Њ—А:
- –Я–Њ–ї—Г—З–µ–љ–љ—Л–є —Н–ї–µ–Љ–µ–љ—В –Љ–µ–љ—М—И–µ: –і–Њ–±–∞–≤–ї—П–µ–Љ –µ–≥–Њ –њ–µ—А–µ–і –Ї—Г—А—Б–Њ—А–Њ–Љ, –њ–µ—А–µ—Е–Њ–і–Є–Љ –Ї –њ—Г–љ–Ї—В—Г 2.
- –Я–Њ–ї—Г—З–µ–љ–љ—Л–є —Н–ї–µ–Љ–µ–љ—В —А–∞–≤–µ–љ: –њ–µ—А–µ–і–≤–Є–≥–∞–µ–Љ –Ї—Г—А—Б–Њ—А –љ–∞ 1 —Н–ї–µ–Љ–µ–љ—В –≤–њ–µ—А—С–і, –њ–µ—А–µ—Е–Њ–і–Є–Љ –Ї –њ—Г–љ–Ї—В—Г 2.
- –Я–Њ–ї—Г—З–µ–љ–љ—Л–є —Н–ї–µ–Љ–µ–љ—В –±–Њ–ї—М—И–µ: —Г–і–∞–ї—П–µ–Љ —Н–ї–µ–Љ–µ–љ—В, –љ–∞ –Ї–Њ—В–Њ—А—Л–є —Г–Ї–∞–Ј—Л–≤–∞–µ—В –Ї—Г—А—Б–Њ—А, –њ–µ—А–µ—Е–Њ–і–Є–Љ –Ї –њ—Г–љ–Ї—В—Г 3.
- –Х—Б–ї–Є –і–∞–љ–љ—Л–µ –Њ—В –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞ –Ї–Њ–љ—З–Є–ї–Є—Б—М, –∞ –љ–∞—И –Ї—Г—А—Б–Њ—А –љ–µ –і–Њ—И—С–ї –і–Њ –Ї–Њ–љ—Ж–∞, —Г–і–∞–ї—П–µ–Љ –≤—Б–µ —Н–ї–µ–Љ–µ–љ—В—Л –љ–∞—З–Є–љ–∞—П —Б —В–µ–Ї—Г—Й–µ–є –њ–Њ–Ј–Є—Ж–Є–Є –Ї—Г—А—Б–Њ—А–∞.
–Ш–ї–Є –Ї–∞—А—В–Є–љ–Ї–Њ–є:
–С–Њ–љ—Г—Б –њ–Њ–і—Е–Њ–і–∞ –і–Њ–ї–ґ–µ–љ –±—Л—В—М –Њ—З–µ–≤–Є–і–µ–љ: –њ–Њ–Љ–Є–Љ–Њ —В–∞–Ї–Њ–≥–Њ –ґ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–∞ –Њ–њ–µ—А–∞—Ж–Є–є –≤—Б—В–∞–≤–Ї–Є/—Г–і–∞–ї–µ–љ–Є—П, –Ї–∞–Ї –Є –≤ –њ—А–µ–і—Л–і—Г—Й–µ–Љ —Б–њ–Њ—Б–Њ–±–µ, —З–Є—Б–ї–Њ –Њ–њ–µ—А–∞—Ж–Є–є –њ–Њ–Є—Б–Ї–∞/—Б—А–∞–≤–љ–µ–љ–Є—П —Г–Љ–µ–љ—М—И–∞–µ—В—Б—П —Б M √Ч N –і–Њ min(M, N) –±–ї–∞–≥–Њ–і–∞—А—П —В–Њ–Љ—Г, —З—В–Њ –Є–Ј-–Ј–∞ —Г–њ–Њ—А—П–і–Њ—З–µ–љ–љ–Њ—Б—В–Є –Є—Б—Е–Њ–і–љ—Л—Е –і–∞–љ–љ—Л—Е –љ–µ –љ—Г–ґ–љ–Њ –≤–µ—Б—В–Є —Б–њ–Є—Б–Њ–Ї –Ї–∞–љ–і–Є–і–∞—В–Њ–≤ –љ–∞ —Г–і–µ–ї–µ–љ–Є–µ, –Љ–Њ–ґ–љ–Њ —Г–і–∞–ї—П—В—М –Є—Е —Б—А–∞–Ј—Г.
–Ш–љ—Л–Љ–Є —Б–ї–Њ–≤–∞–Љ–Є, –µ—Б–ї–Є –њ–µ—А–≤—Л–Љ–Є –њ—Г–љ–Ї—В–∞–Љ–Є –љ–∞—И–µ–≥–Њ —Б–њ–Є—Б–Ї–∞ –Є–і—Г—В ¬Ђ–Р–ї–Є–љ–∞¬ї –Є ¬Ђ–Р–ї–ї–∞¬ї, –∞ –Њ—В –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞ –њ—А–Є—Е–Њ–і–Є—В ¬Ђ–С–Њ—А–Є—Б¬ї, —В–Њ –њ–µ—А–≤—Л–µ –і–≤–∞ —Н–ї–µ–Љ–µ–љ—В–∞ –Р–ї–Є–љ—Г –Є –Р–ї–ї—Г —Б–Љ–µ–ї–Њ –Љ–Њ–ґ–љ–Њ —Г–і–∞–ї—П—В—М —Г–ґ–µ —Б–µ–є—З–∞—Б вАФ –Њ—В –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞ –Њ–љ–Є —Г–ґ–µ –≥–∞—А–∞–љ—В–Є—А–Њ–≤–∞–љ–љ–Њ –љ–µ –њ—А–Є–і—Г—В.
–Ъ—А—Г—В–Њ!
–Ш –њ–Њ—Б–Ї–Њ–ї—М–Ї—Г —Г–њ–Њ—А—П–і–Њ—З–µ–љ–љ—Л–µ –і–∞–љ–љ—Л–µ –Њ—В –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞ –њ—А–Є—Е–Њ–і—П—В –≥–Њ—А–∞–Ј–і–Њ —З–∞—Й–µ, —З–µ–Љ –љ–µ—Г–њ–Њ—А—П–і–Њ—З–µ–љ–љ—Л–µ вАФ —Н—В–Њ –Є–Љ–µ–љ–љ–Њ —В–Њ—В —Б–њ–Њ—Б–Њ–±, –Ї–Њ—В–Њ—А—Л–є –≤—Л –і–Њ–ї–ґ–љ—Л –њ–Њ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є –≤—Б–µ–≥–і–∞ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М, –µ—Б–ї–Є –љ–µ—В –Ї–∞–Ї–Є—Е-—В–Њ –Њ—Б–Њ–±—Л—Е —В–Њ–љ–Ї–Є—Е –Љ–Њ–Љ–µ–љ—В–Њ–≤, –Ї–Њ—В–Њ—А—Л–µ –і–µ–ї–∞—О—В –µ–≥–Њ –љ–µ —Б–∞–Љ—Л–Љ –ї—Г—З—И–Є–Љ. –•–Њ—В—П —П —Б —Е–Њ–і—Г –љ–µ –њ—А–Є–і—Г–Љ–∞—О —В–∞–Ї–Њ–є —Б–ї—Г—З–∞–є: –≤–∞—И–∞ –ї–µ–љ—М, —В–Њ –µ—Б—В—М –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ—Б—В—М –њ–Є—Б–∞—В—М –±–Њ–ї—М—И–µ –Ї–Њ–і–∞, —З–µ–Љ —В—А–µ–±—Г–µ—В –љ—Г–ї–µ–≤–Њ–є ¬Ђ—Б–∞–Љ—Л–є –љ–µ–Ї—А–∞—Б–Є–≤—Л–є –≤–∞—А–Є–∞–љ—В¬ї вАФ –љ–µ —Б—З–Є—В–∞—О—В—Б—П.
–Э–Њ –Є —Н—В–Њ –љ–µ –Є–і–µ–∞–ї.
–Я—А–Є–±–ї–Є–ґ–∞—П—Б—М –Ї –Є–і–µ–∞–ї—Г
–ѓ —Б—В–Њ—А–Њ–љ–љ–Є–Ї –Ї–∞–Ї –Љ–Є–љ–Є–Љ—Г–Љ –і–≤—Г—Е –≤–µ—Й–µ–є:
- Event-driven –њ–∞—А–∞–і–Є–≥–Љ—Л, –њ—А–Є—З—С–Љ, –Ї–Њ–љ–µ—З–љ–Њ –ґ–µ, –љ–µ –Њ–≥—А–∞–љ–Є—З–Є–≤–∞—П—Б—М —Б–Њ–±—Л—В–Є—П–Љ–Є COM-–Љ–Њ–і–µ–ї–Є
- –Ф–Є—Д—Д–µ—А–µ–љ—Ж–Є–∞–ї—М–љ–Њ–≥–Њ –њ–Њ–і—Е–Њ–і–∞
–Т—В–Њ—А–Њ–є –њ–Њ–і—Е–Њ–і –≥–ї–∞—Б–Є—В: –њ—А–Є–Љ–µ–љ—П–є—В–µ –і–Є—Д—Д–µ—А–µ–љ—Ж–Є—А–Њ–≤–∞–љ–Є–µ –≤ —И–Є—А–Њ–Ї–Њ–Љ —Б–Љ—Л—Б–ї–µ —Б–ї–Њ–≤–∞ –≤–µ–Ј–і–µ, –≥–і–µ —Н—В–Њ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ. –І–∞—Б—В–Њ –њ—А–Њ—Й–µ –љ–µ –њ–Њ –≤—Е–Њ–і–љ—Л–Љ –і–∞–љ–љ—Л–Љ –≤—Л—З–Є—Б–ї—П—В—М –≤—Л—Е–Њ–і–љ—Л–µ, –∞ –њ–Њ –Є–Ј–Љ–µ–љ–µ–љ–Є—О –≤—Е–Њ–і–љ—Л—Е –≤—Л—З–Є—Б–ї–Є—В—М –Є–Ј–Љ–µ–љ–µ–љ–Є–µ –≤—Л—Е–Њ–і–љ—Л—Е. –Ф–∞–ґ–µ –њ—А–Њ–Є–Ј–≤–Њ–і–љ—Л–µ –њ—А–Њ—Б—В—Л—Е –Љ–∞—В. —Д—Г–љ–Ї—Ж–Є–є –ї–µ–≥—З–µ –≤ –њ–ї–∞–љ–µ –≤—Л—З–Є—Б–ї–µ–љ–Є—П, —З–µ–Љ —Б–∞–Љ–Є —Д—Г–љ–Ї—Ж–Є–Є.
–Т –љ–∞—И–µ–Љ —Б–ї—Г—З–∞–µ, —Б —Г—З—С—В–Њ–Љ event-driven-–њ–Њ–і—Е–Њ–і–∞, —Н—В–Њ –Њ–Ј–љ–∞—З–∞–µ—В, —З—В–Њ –≤–∞–Љ –љ—Г–ґ–љ–Њ –Њ—А–≥–∞–љ–Є–Ј–Њ–≤–∞—В—М –≤–Ј–∞–Є–Љ–Њ–і–µ–є—Б—В–≤–Є–µ –≤–∞—И–µ–≥–Њ —Б–њ–Є—Б–Ї–∞ —Б –њ–µ—А–≤–Є—З–љ—Л–Љ –Є—Б—В–Њ—З–љ–Є–Ї–Њ–Љ –і–∞–љ–љ—Л—Е —В–∞–Ї, —З—В–Њ–±—Л —Б–њ–Є—Б–Њ–Ї –њ–Њ–ї—Г—З–∞–ї —Г–≤–µ–і–Њ–Љ–ї–µ–љ–Є—П –Њ—В –њ–µ—А–≤–Є—З–љ–Њ–≥–Њ –Є—Б—В–Њ—З–љ–Є–Ї–∞ –Њ –і–Њ–±–∞–≤–ї—П—О—Й–Є—Е—Б—П –Є–ї–Є —Г–і–∞–ї—П–µ–Љ—Л—Е —Н–ї–µ–Љ–µ–љ—В–∞—Е –≤ —В–Њ—З–љ–Њ—Б—В–Є —В–Њ–≥–і–∞, –Ї–Њ–≥–і–∞ –Њ–љ–Є –і–Њ–±–∞–≤–ї—П—О—В—Б—П/—Г–і–∞–ї—П—О—В—Б—П.
–Я–Њ–і–і–µ—А–ґ–Є–≤–∞—В—М —Б–њ–Є—Б–Њ–Ї –≤ –∞–Ї—В—Г–∞–ї—М–љ–Њ–Љ —Б–Њ—Б—В–Њ—П–љ–Є–Є –њ–Њ—Б—В–Њ—П–љ–љ–Њ –≥–Њ—А–∞–Ј–і–Њ –Љ–µ–љ–µ–µ –љ–∞–Ї–ї–∞–і–љ–Њ, —З–µ–Љ –≤—А–µ–Љ—П –Њ—В –≤—А–µ–Љ–µ–љ–Є —Г—Б—В—А–∞–љ—П—В—М –Ј–љ–∞—З–Є—В–µ–ї—М–љ—Л–є —А–∞—Б—Б–Є–љ—Е—А–Њ–љ –Љ–µ–ґ–і—Г –љ–∞—И–Є–Љ —Б–њ–Є—Б–Ї–Њ–Љ –Є –њ–µ—А–≤–Є—З–љ—Л–Љ –Є—Б—В–Њ—З–љ–Є–Ї–Њ–Љ. –Ю—Б–Њ–±–µ–љ–љ–Њ —Н—В–Њ –∞–Ї—В—Г–∞–ї—М–љ–Њ –і–ї—П –Ї–ї–Є–µ–љ—В-—Б–µ—А–≤–µ—А–љ—Л—Е —Б–Є—Б—В–µ–Љ, —А–∞–±–Њ—В–∞—О—Й–Є—Е –њ–Њ —Б–µ—В–Є. –Т–Њ –≤—Б–µ—Е –њ—А–µ–і—Л–і—Г—Й–Є—Е —Б–ї—Г—З–∞—П—Е –≤–∞–Љ –њ—А–Є—Е–Њ–і–Є–ї–Њ—Б—М –њ—А–Є –Њ–±–љ–Њ–≤–ї–µ–љ–Є–Є —Б–њ–Є—Б–Ї–∞ –њ–µ—А–µ—Б—Л–ї–∞—В—М –Љ–µ–ґ–і—Г —Б–Њ–±–Њ–є –Є –њ–µ—А–≤–Є—З–љ—Л–Љ –Є—Б—В–Њ—З–љ–Є–Ї–Њ–Љ –≤–µ—Б—М –љ–∞–±–Њ—А —Н–ї–µ–Љ–µ–љ—В–Њ–≤. –≠—В–Њ—В –Њ—З–µ–љ—М –љ–µ—Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ, –µ—Б–ї–Є —Н–ї–µ–Љ–µ–љ—В–Њ–≤ –Љ–љ–Њ–≥–Њ, –∞ –Њ–±–љ–Њ–≤–ї–µ–љ–Є–µ –і–Њ—Б—В–∞—В–Њ—З–љ–Њ —З–∞—Б—В–Њ–µ. –Т—Л –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞–ї–Є —В–Њ–ї—М–Ї–Њ –∞–ї–≥–Њ—А–Є—В–Љ –Њ–±–љ–Њ–≤–ї–µ–љ–Є—П, –љ–Њ –љ–µ –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞–ї–Є –њ–µ—А–µ–і–∞—З—Г –і–∞–љ–љ—Л—Е. –Т –і–∞–љ–љ–Њ–Љ –ґ–µ —Б–ї—Г—З–∞–µ –њ–µ—А–µ–і–∞—О—В—Б—П —В–Њ–ї—М–Ї–Њ –љ—Г–ґ–љ—Л–µ –і–∞–љ–љ—Л–µ: –Ї–∞–Ї–Є–µ —Н–ї–µ–Љ–µ–љ—В—Л –±—Л–ї–Є –і–Њ–±–∞–≤–ї–µ–љ—Л, –Ї–∞–Ї–Є–µ –±—Л–ї–Є —Г–і–∞–ї–µ–љ—Л (–µ—Б–ї–Є –±—Л–ї–Є). –Э–Є–Ї–∞–Ї–Є—Е –і–∞–љ–љ—Л—Е, –Њ—В–љ–Њ—Б—П—Й–Є—Е—Б—П –Ї –љ–µ—В—А–Њ–љ—Г—В—Л–Љ —Н–ї–µ–Љ–µ–љ—В–∞–Љ вАФ –љ–µ –њ–µ—А–µ–і–∞—С—В—Б—П.
–С–Њ–ї–µ–µ —В–Њ–≥–Њ, —В–∞–Ї–Њ–є –њ–Њ–і—Е–Њ–і –њ–Њ–Ј–≤–Њ–ї–Є—В –≤–∞–Љ –Њ—В–Њ–±—А–∞–Ј–Є—В—М —Б–њ–Є—Б–Њ–Ї –≤ –Љ–љ–Њ–≥–Є—Е –Љ–µ—Б—В–∞—Е –Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ–Њ: –Њ–±–љ–Њ–≤–ї—П—В—М—Б—П –Њ–љ–Є –≤—Б–µ –±—Г–і—Г—В —В–Њ–ґ–µ –Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ–Њ, –∞ –љ–µ –њ–Њ —В–∞–є–Љ–µ—А—Г, –њ–ї—О—Б –і–ї—П –Њ–±–љ–Њ–≤–ї–µ–љ–Є—П –≤—Б–µ—Е –±—Г–і–µ—В –і–Њ—Б—В–∞—В–Њ—З–љ–Њ –Њ–і–љ–Њ–≥–Њ —Г–≤–µ–і–Њ–Љ–ї–µ–љ–Є—П –Њ —Б–Њ–±—Л—В–Є—П, –≤ –Њ—В–ї–Є—З–Є–µ –Њ—В –њ—А–µ–і—Л–і—Г—Й–Є—Е —Б–ї—Г—З–∞–µ–≤, –≥–і–µ –Ї–∞–ґ–і—Л–є —Б–њ–Є—Б–Њ–Ї —Б–Њ–Ј–і–∞–≤–∞–ї —Б–≤–Њ–є –Њ—В–і–µ–ї—М–љ—Л–є —В—А–∞—Д–Є–Ї –Љ–µ–ґ–і—Г –њ–µ—А–≤–Є—З–љ—Л–Љ –Є—Б—В–Њ—З–љ–Є–Ї–Њ–Љ.
–Ш—В–∞–Ї, –≤–Њ—В –≤–∞–Љ –љ–µ—З—В–Њ –њ–Њ—Е–Њ–ґ–µ–µ –љ–∞ –њ–∞—В—В–µ—А–љ –њ—А–Њ–µ–Ї—В–Є—А–Њ–≤–∞–љ–Є—П. –Ю–±—К–µ–Ї—В-–Ї–Њ–ї–ї–µ–Ї—Ж–Є—П —Б –Њ–±—П–Ј–∞—В–µ–ї—М–љ—Л–Љ–Є —Б–Њ–±—Л—В–Є—П–Љ–Є ItemAdded –Є ItemRemoved. –Э–∞ —Б–Њ–±—Л—В–Є—П –Њ–і–љ–Њ–≥–Њ —В–∞–Ї–Њ–≥–Њ –Њ–±—К–µ–Ї—В–∞ –Љ–Њ–ґ–µ—В –њ–Њ–і–њ–Є—Б–∞—В—М—Б—П —Б–Ї–Њ–ї—М–Ї–Њ —Г–≥–Њ–і–љ–Њ –Ј–∞–Є–љ—В–µ—А–µ—Б–Њ–≤–∞–љ–љ—Л—Е —Б—В–Њ—А–Њ–љ-—Б–њ–Є—Б–Ї–Њ–≤. –Я—А–Є—З—С–Љ –њ–Њ–і —Б–њ–Є—Б–Ї–∞–Љ–Є –Ј–і–µ—Б—М –њ–Њ–љ–Є–Љ–∞—О—В—Б—П –Ї–∞–Ї —Б–Њ–±—Б—В–≤–µ–љ–љ–Њ —Б–∞–Љ–Є —Б–њ–Є—Б–Ї–Є (—З–Є—Б—В–Њ –њ—А–Њ–≥—А–∞–Љ–Љ–љ—Л–µ –Є–ї–Є –≥—А–∞—Д–Є—З–µ—Б–Ї–Є–µ), —В–∞–Ї –Є, –љ–∞–њ—А–Є–Љ–µ—А, event-hub-—Л, –Ї–Њ—В–Њ—А—Л–µ –±—Г–і—Г—В —А–∞—Б—Б—Л–ї–∞—В—М –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—О –Њ–± –Є–Ј–Љ–µ–љ–µ–љ–Є–Є –і–∞–ї—М—И–µ.
–Ш –љ–Є–Ї–∞–Ї–Њ–є —Н–љ—Г–Љ–µ—А–∞—Ж–Є–Є. –Х—Б–ї–Є –≤—Л –≤ —Б–∞–Љ–Њ–Љ –љ–∞—З–∞–ї–µ, –Є –≤–∞—И —Б–њ–Є—Б–Њ–Ї –≤–Њ–Њ–±—Й–µ –њ—Г—Б—В, –Є –≤–∞–Љ –љ—Г–ґ–љ–∞ –љ–µ –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—П –Њ–± –Є–Ј–Љ–µ–љ–µ–љ–Є—П—Е —Б–њ–Є—Б–Ї–∞, –∞ —Б–∞–Љ —Б–њ–Є—Б–Њ–Ї, –њ—А–Њ—Б—В–Њ —Б–Њ–Њ–±—Й–Є—В–µ —Н—В–Њ –Є—Б—В–Њ—З–љ–Є–Ї—Г (–≤–µ—А–љ–µ–µ –µ–≥–Њ –њ—А–µ–і—Б—В–∞–≤–Є—В–µ–ї—О вАФ –Њ–±—К–µ–Ї—В—Г —Б —Б–Њ–±—Л—В–Є—П–Љ–Є) вАФ –≤—Б–µ —Н–ї–µ–Љ–µ–љ—В—Л —Б–њ–Є—Б–Ї–∞ –і–Њ–ї–ґ–љ—Л –Ї–∞–Ї –±—Л –Ј–∞–љ–Њ–≤–Њ —А–Њ–і–Є—В—М—Б—П —З–µ—А–µ–Ј —Б–Њ–±—Л—В–Є–µ ItemAdded.
–Я–Њ–ї–љ–Њ—Б—В—М—О –Њ—В–Ї–∞–ґ–Є—В–µ—Б—М –Њ—В –Ї–ї–∞—Б—Б–Є—З–µ—Б–Ї–Њ–є —Н–љ—Г–Љ–µ—А–∞—Ж–Є–Є, –Є –≤–Љ–µ—Б—В–Њ —Н—В–Њ–≥–Њ —А–∞—Б—И–Є—А—М—В–µ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –њ–Њ–ї—Г—З–Є—В—М —Г–≤–µ–і–Њ–Љ–ї–µ–љ–Є—П –Њ–± –і–Њ–±–∞–≤–ї—П—О—Й–Є—Е—Б—П/–Є—Б—З–µ–Ј–∞—О—Й–Є—Е —Б–µ–є—З–∞—Б —Н–ї–µ–Љ–µ–љ—В–∞—Е –і–Њ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є –њ–Њ–ї—Г—З–∞—В—М —Г–≤–µ–і–Њ–Љ–ї–µ–љ–Є—П –Њ–± –і–Њ–±–∞–≤–Є–≤—И–Є—Е—Б—П/—Г–і–∞–ї–Є–≤—И–Є—Е—Б—П —Н–ї–µ–Љ–µ–љ—В–∞—Е —Б –Ї–∞–Ї–Њ–≥–Њ-—В–Њ –Љ–Њ–Љ–µ–љ—В–∞. –Я—А–Њ—Б—В–Њ —Б–і–µ–ї–∞–є—В–µ —В–∞–Ї, —З—В–Њ–±—Л –≤—Л –Љ–Њ–≥–ї–Є —Г–Ї–∞–Ј–∞—В—М –Є—Б—В–Њ—З–љ–Є–Ї—Г –і–∞–љ–љ—Л—Е –≤—А–µ–Љ–µ–љ–љ—Г—О –Њ—В–Љ–µ—В–Ї—Г, –і–∞–љ–љ—Л–Љ–Є, –∞–Ї—В—Г–∞–ї—М–љ—Л–Љ–Є –љ–∞ –Љ–Њ–Љ–µ–љ—В –Ї–Њ—В–Њ—А–Њ–є –≤—Л –Њ–±–ї–∞–і–∞–µ—В–µ. –Я—Г—Б—В—М –Є—Б—В–Њ—З–љ–Є–Ї —Б–Њ–Њ–±—Й–Є—В –≤–∞–Љ —З–µ—А–µ–Ј –≤—Б—С —В–Њ—В –ґ–µ –Љ–µ—Е–∞–љ–Є–Ј–Љ —Б–Њ–±—Л—В–Є–є –Њ–±–Њ –≤—Б–µ—Е –Є–Ј–Љ–µ–љ–µ–љ–Є—П—Е, –њ—А–Њ–Є–Ј–Њ—И–µ–і—И–Є—Е —Б —В–Њ–≥–Њ –≤—А–µ–Љ–µ–љ–Є. –Р –њ–Њ—Б–ї–µ вАФ –њ—Г—Б—В—М —Б–Њ–Њ–±—Й–∞–µ—В –Њ–± –Є–Ј–Љ–µ–љ–µ–љ–Є—П—Е, –њ—А–Њ–Є—Б—Е–Њ–і—П—Й–Є—Е —Б–µ–є—З–∞—Б.
–Ґ–∞–Ї–Њ–є –њ–Њ–і—Е–Њ–і –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ —Н—Д—Д–µ–Ї—В–Є–≤–µ–љ –≤ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Є–Є —Б –њ—А–Є–љ—Ж–Є–њ–Њ–Љ –ї–µ–љ–Є.
–Х–і–Є–љ—Б—В–≤–µ–љ–љ–Њ–µ –Є—Б–Ї–ї—О—З–µ–љ–Є–µ, –Ї–Њ–≥–і–∞ —Н—В–Њ—В —Б–ї—Г—З–∞–є –њ—А–Њ–Є–≥—А—Л–≤–∞–µ—В –Ї–ї–∞—Б—Б–Є—З–µ—Б–Ї–Њ–є —Н–љ—Г–Љ–µ—А–∞—Ж–Є–Є, —Н—В–Њ —Б–ї—Г—З–∞–є, –Ї–Њ–≥–і–∞ —Н–ї–µ–Љ–µ–љ—В—Л –і–Њ–±–∞–≤–ї—П—О—В—Б—П –Є —Б—А–∞–Ј—Г –ґ–µ —Г–љ–Є—З—В–Њ–ґ–∞—О—В—Б—П —З—А–µ–Ј–≤—Л—З–∞–є–љ–Њ —З–∞—Б—В–Њ, –Є —Б–∞–Љ–Є —Н—В–Є —Д–∞–Ї—В—Л –Є–Љ–µ–µ—В –Њ—З–µ–љ—М –Љ–∞–ї–Њ–µ –Ј–љ–∞—З–µ–љ–Є–µ. –Ґ–Њ –µ—Б—В—М –і–∞, —Н–љ—Г–Љ–µ—А–∞—Ж–Є—П –±—Г–і–µ—В –ї—Г—З—И–µ, –µ—Б–ї–Є –Ї–∞–ґ–і—Г—О —Б–µ–Ї—Г–љ–і—Г 1000 —Н–ї–µ–Љ–µ–љ—В–Њ–≤ —Г—Б–њ–µ–≤–∞—О—В –і–Њ–±–∞–≤–Є—В—М—Б—П –Є –Є—Б—З–µ–Ј–љ—Г—В—М –њ–Њ 50 —А–∞–Ј –Ї–∞–ґ–і—Л–є, –Є –њ—А–Є —В–Њ–Љ –≤–∞–ґ–љ–Њ—Б—В—М —Н—В–Є—Е —Б–Њ–±—Л—В–Є–є вАФ –љ–Є–Ї–∞–Ї–∞—П.
–Э–Њ –і–∞–ґ–µ –≤ —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ –Ї—Г–і–∞ –Ї—А–∞—Б–Є–≤–µ–µ –±—Г–і–µ—В –њ–Њ–і—Е–Њ–і —Б —Б–Њ–±—Л—В–Є—П–Љ–Є: –њ—А–Њ—Б—В–Њ –≤–≤–µ–і–Є—В–µ —Д–Є–ї—М—В—А, —Б–і–µ–ї–∞–є—В–µ —В–∞–Ї, —З—В–Њ–±—Л —Г–≤–µ–і–Њ–Љ–ї–µ–љ–Є—П –Њ –љ–Њ–≤—Л—Е —Н–ї–µ–Љ–µ–љ—В–∞—Е –њ—А–Є—Е–Њ–і–Є–ї–Є –≤–∞–Љ —В–Њ–ї—М–Ї–Њ —В–Њ–≥–і–∞, –Ї–Њ–≥–і–∞ —Н—В–Є —Н–ї–µ–Љ–µ–љ—В—Г –њ—А–Њ—Б—Г—Й–µ—Б—В–≤–Њ–≤–∞–ї–Є –і–Њ—Б—В–∞—В–Њ—З–љ–Њ –і–Њ–ї–≥–Њ, –љ–µ —Г–і–∞–ї–Є–≤—И–Є—Б—М. –Я—Г—Б—В—М, –µ—Б–ї–Є –њ–µ—А—Б–Њ–љ–∞–ї—М–љ–Њ –≤–∞–Љ –љ–µ –љ—Г–ґ–љ—Л ¬Ђ—Б–≤–µ—А—Е–љ–Њ–≤—Л–µ —Н–ї–µ–Љ–µ–љ—В—Л¬ї, —Г–≤–µ–і–Њ–Љ–ї–µ–љ–Є—П –Њ –љ–Є—Е –њ–µ—А—Б–Њ–љ–∞–ї—М–љ–Њ –≤–∞–Љ –≤—Л—Б–ї–∞–љ—Л –љ–µ –±—Г–і—Г—В (–∞ –Ї–Њ–Љ—Г-—В–Њ –і—А—Г–≥–Њ–Љ—Г, —В–Њ –µ—Б—В—М –Ї–∞–Ї–Њ–Љ—Г-—В–Њ –і—А—Г–≥–Њ–Љ—Г –∞–≥–µ–љ—В—Г –≤–Ј–∞–Є–Љ–Њ–і–µ–є—Б—В–≤–Є—П вАФ –±—Г–і—Г—В). –Я—А–Є —Н—В–Њ–Љ –≤—Л –њ–Њ–ї–љ–Њ—Б—В—М—О –Є–Ј–±–∞–≤–Є—В–µ—Б—М –Њ—В —И—Г–Љ–∞ –Є–Ј –љ–µ–ґ–µ–ї–∞—В–µ–ї—М–љ—Л—Е —Н–ї–µ–Љ–µ–љ—В–Њ–≤, –≤ –Њ—В–ї–Є—З–Є–µ –Њ—В —Б–ї—Г—З–∞—П —Б —Н–љ—Г–Љ–µ—А–∞—Ж–Є–µ–є, –Ї–Њ—В–Њ—А–∞—П –±—Г–і–µ—В –≤–Ї–ї—О—З–∞—В—М –≤ —Б–µ–±—П –≤—Б–µ —Б—Г—Й–µ—Б—В–≤–Њ–≤–∞–≤—И–Є–µ –љ–∞ –Љ–Њ–Љ–µ–љ—В —Б–Њ–Ј–і–∞–љ–Є—П —Б–љ–Є–Љ–Ї–∞ (—Б–љ–∞–њ—И–Њ—В–∞) –Ї–Њ—А–Њ—В–Ї–Њ–ґ–Є–≤—Г—Й–Є–µ —Н–ї–µ–Љ–µ–љ—В—Л.
–Т–Ј–≥–ї—П–і —Б –і—А—Г–≥–Њ–є —Б—В–Њ—А–Њ–љ—Л
–Э–µ—В, –љ–µ —Б –њ—А–Њ—В–Є–≤–Њ–њ–Њ–ї–Њ–ґ–µ–љ–љ–Њ–є, –∞ –љ–µ–Љ–љ–Њ–≥–Њ —Б–±–Њ–Ї—Г. –Я–Њ–Љ–Є–Љ–Њ –∞–ї–≥–Њ—А–Є—В–Љ–∞ –Њ–±–љ–Њ–≤–ї–µ–љ–Є—П, –≤—Л–±–Њ—А –Љ–µ–ґ–і—Г –Ї–Њ—В–Њ—А—Л–Љ–Є –њ–Њ–Ј–≤–Њ–ї—П–µ—В –≤–∞–Љ –≤—Л–±–Є—А–∞—В—М —Б—В—А–∞—В–µ–≥–Є—О —В–Њ–≥–Њ, –Ї–∞–Ї –Є –Ї–Њ–≥–і–∞ –Ї–∞–Ї–Є–µ —Н–ї–µ–Љ–µ–љ—В—Г —Г–і–∞–ї—П—В—М –Є –і–Њ–±–∞–≤–ї—П—В—М, –Љ–Њ–ґ–љ–Њ –µ—Й—С —Е–Њ—А–Њ—И–Њ –њ–Њ–і—Г–Љ–∞—В—М –Њ —В–Њ–Љ, –Ї–∞–Ї –њ–Њ–і—Е–Њ–і–Є—В—М –Ї —Б–∞–Љ–Є–Љ –Њ–њ–µ—А–∞—Ж–Є—П–Љ–Є —Г–і–∞–ї–µ–љ–Є—П –і–Њ–±–∞–≤–ї–µ–љ–Є—П. –Т–µ—А–љ–µ–µ, –Ї —Б–µ—А–Є—П–Љ —В–∞–Ї–Є—Е –Њ–њ–µ—А–∞—Ж–Є–є. –ѓ –±—Л –Ј–і–µ—Б—М –њ–Њ—Б–Њ–≤–µ—В–Њ–≤–∞–ї ¬Ђ—В—А–∞–љ–Ј–∞–Ї—В–Є–≤–љ—Л–є –њ–Њ–і—Е–Њ–і¬ї, –љ–Њ —Н—В–∞ —В–µ–Љ–∞ –і–Њ—Б—В–Њ–є–љ–∞ –Њ—В–і–µ–ї—М–љ–Њ–є —Б—В–∞—В—М–Є.
–Ш—В–∞–Ї, –њ—А–∞–≤–Є–ї—М–љ—Л–µ –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П –Њ–±–љ–Њ–≤–ї—П—О—В —Б–≤–Њ–Є —Б–њ–Є—Б–Ї–Є –Ї—А–∞—Б–Є–≤–Њ.

