

Продемонстрирую на более менее упрощённом примере.
Написал я примерно такую процедуру:
- Код: Выделить всё
#define ADDR_BUS PORTC
#define DATA_BUS PINB
void DoRead(uint8_t *dstbuf)
{
uint8_t i;
for(i = 0; i < 128; i++)
{
ADDR_BUS = i;
dstbuf[i] = DATA_BUS;
}
}
Как должно быть очевидно, к CPU подключено некоторое устройство (будем называть его памятью) с помощью двух параллельных шин. 7-битная шина адреса повешена на Port C, а 8-битная шина данных — на Port B. Устройство просто итеративно выставляет адрес (от 0 до 127) на шину адреса, после чего считывает байт данных с шины данных и записывает его в буфер. Думаю, всё понятно.
Теперь посмотрим, во что это скомпилировалось:
- Код: Выделить всё
DoRead:
movw r30, r24
ldi r25, 0x00
loop_begin:
out PORTC, r25
in r24, PINB
st Z+, r24
subi r25, 0xFF
cpi r25, 0x80
brne loop_begin
ret
Для тех, кто не знаком с системой команд и архитектурой AVR, поясню в двух словах: микроконтроллер 8-битный, все регистры у него 8-битные, а вот памяти (SRAM) может быть больше 256 байт, поэтому адреса не умещаются в 8 бит. Для этого есть три пары регистров, которые образуют три 16-битных регистра: пара R27 и R26 образует регистр X, пара R29 и R28 — регистр Y, пара R31 и R30 — регистр Z. Это очень похоже на то, как в процессоре 8080 были 8-битные регистры A, B, C, D, E, H, L с возможностью объединения в 16-битные пары BC, DE, HL, или как в 8086 были введены сегментные регистры, чтобы адресовать больше 64K памяти.
Соглашение о вызове такое, что единственный аргумент (адрес буфера) передался в паре R25:R24. Первая же команда movw r30, r24 копирует этот адрес из R25:R24 в пару R31:R30, то есть адрес буфера заносится в регистр Z.
Инструкция ldi r25, 0x00 инициализирует регистр R25 нулём — в дальнейшем регистр R25 будет олицетворять переменную i.
Далее начинается цикл: инструкция out PORTC, r25 выставляет число из регистра R25 (то есть переменной i) на порт «C» (то есть на шину адреса). Инструкция in r24, PINB считывает байт с порта «B» (то есть с шины данных) и заносит его в регистр R24. Инструкция st Z+, r24 записывает считанный байт (хранящийся в R24) в память по адресу, находящемуся в регистре Z, после чего инкрементирует регистр Z. На x86, если пофантазировать, это была бы инструкция mov byte[reg1++], reg2 (но такой формы инструкции mov с использованием косвенной адресации с пост-инкрементом одного из регистров у x86 нет, хотя есть «строковые» инструкции MOVS/STOS/SCAS/CMPS, которые делает инкремент/декремент).
Инструкция subi r25, 0xFF это просто причудливый вариант увеличить R25 на единицу (отняв, по факту, 255), то есть эквивалент addi r25, 1 или inc r25 — увеличивает переменную i на единицу.
Далее инструкция cpi r25, 0x80 сравнивает R25 с числом 128 (аналог в x86 — инструкция cmp), и затем инструкция условного перехода brne loop_begin (аналог в x86 — jne) перекидывает нас на следующую итерцию (или завершает цикл).
Ещё раз тот же код, с комментариями:
- Код: Выделить всё
DoRead:
movw r30, r24 ; Указатель dstbuf заносится в регистр Z (R31:R30)
ldi r25, 0x00 ; i = 0
loop_begin:
out PORTC, r25 ; PORTC = i
in r24, PINB ; Считываем значение с порта B
st Z+, r24 ; Записываем его в память по адресу Z, инкрементируем Z
subi r25, 0xFF ; i++
cpi r25, 0x80 ; i == 128 ?
brne loop_begin ; Если нет, то goto loop_begin
ret ; Возврат из процедуры
Или, для тех, кому ближе x86-аналогия (весьма условная и натянутая):
- Код: Выделить всё
DoRead:
movw r30, r24 ; mov dx, ax
ldi r25, 0x00 ; mov cl, 0
loop_begin:
out PORTC, r25 ; out PORTC, cl
in r24, PINB ; in bl, PINB
st Z+, r24 ; mov [dx++], bl
subi r25, 0xFF ; sub cl, 255 ; (эквивалентно add cl, 1 или inc cl)
cpi r25, 0x80 ; cmp cl, 128
brne loop_begin ; jne loop_begin
ret ; retn
Отсюда можно сделать важное наблюдение: в то время, как в оригинальном C-коде значение переменной i использовалось для двух нужд — для выставления адреса в PORTC и для доступа к элементу буфера (dstbuf[i]), после компиляции эта переменная (регистр R25) используется только для выставления адреса на шину, а для доступа к буферу используется регистр Z, который в принципе независим от R25.
Иными словами, полученный ассемлерный код больше похож на то, что исходный сишный код был таким:
- Код: Выделить всё
void DoRead(uint8_t *dstbuf)
{
uint8_t i;
for(i = 0; i < 128; i++)
{
ADDR_BUS = i;
*(dstbuf++) = DATA_BUS;
}
}
Пока всё хорошо и правильно, очень радует, что avr-gcc использует форму адресации с пост-инкрементом (st Z+, r24 затрачивает на выполнение 2 цикла (такта), в то время как вычисление нового значения Z через сложение изначального dstbuf и R25 заняло бы куда дольше, а st Z, R24 (без пост-инкремента) всё равно бы потребовалась).
Теперь небольшое отступление:
- Ни для кого не должно быть секретом, что компиляторы в общей своей массе во имя оптимизации могут ликвидировать или как минимум перемещать (переставлять местами) одиночные инструкции или блоки инструкций. Например, если в начале функции объявлены переменные, которые на всём протяжении функции так нигде и не используются, хороший компилятор вообще устранит использование этих переменных: не будет резервировать под них место в стеке/в регистрах и не будет генерировать инструкции, производящие инициализацию. Если переменная была объявлена в начале функции, но на всём протяжении не используется, а используется только в самом конце, компилятор запросто может инициализацию этой переменной переместить ближе к концу процедуры. Компилятор руководствуется концепцией побочных эффектов: если действие1 производит некий побочный эффект, который важен для действия2, то в скомпилированном коде инструкции, соответствующие этим действиям, будут идти именно в таком порядке, в противном случае компилятор волен их переставить или вообще выкинуть действие1, если оно не производит никаких побочных эффектов (или от побочных эффектов, производимых действием, никакие другие действия не зависят). В целом, логика компилирования С-кода построена из убеждения (предположения), что текущий код выполняется единственным потоком, и все переменные (как глобальные так и локальные) могут изменяться только текущим потоком (и никем другим), поэтому если текущий код прочитал значение переменной из памяти, и пока что явно туда ничего не записывал, новое значение не будут перечитано, или, если же текущий код присваивает переменной значение, но дальше оно нигде не используется, присвоения не будет, потому что считается, что кроме исполняющегося в данный момент кода это значение никому больше не нужно. Что же касается перестановок инструкций, то это очень интенсивно используется для генерации кода для суперскалярных (то есть многоконвейерных) CPU, то есть для современного x86 в частности — компилятор постарается пару инструкций, обращающуюся к одному и тому же регистру, разбавить третьей инструкцией, обращающейся к какому-нибудь другому регистру, потому что это даст большую скорость выполнения.
Чтобы умерить пыл этой оптимизационной логики введен квалификатор volatile, которая говорит компилятору, что некая «внешняя сила» может быть заинтересована (и производить) параллельный доступ (чтение или изменение) переменной — этой силой может быть как параллельный поток, так и аппаратная логика целевой системы.
Поэтому, например, в заголовочных файлах все порты и объявлены с volatile, чтобы две последовательных попытки записи разных чисел в один и тот же порт не были оптимизированы с выкидыванием всех промежуточных записей и оставлением только последней.
Теперь вернёмся к нашей задаче. Немного поближе к реальному миру.
Мой CPU работает на тактовой частоте 16 MHz. Это означает 62.5 ns на один такт. У AVR один процессорный цикл совершается за один такт (в общем случае это не всегда так). Большинство инструкций выполняется за 1 цикл, некоторые — за 2.
В частности, инструкции out и in выполняются за 1 цикл.
И у нас есть вот такой исходный код:
- Код: Выделить всё
ADDR_BUS = i;
dstbuf[i] = DATA_BUS;
который превращается в:
- Код: Выделить всё
out PORTC, r25
in r24, PINB
Иными словами, между выставлением адреса на шину и считыванием данных с шины данных проходит не более 62.5 ns.
Однако, реальный мир таков, что устройство (мы договорились называть его «память»), которое мы опрашиваем имеет другие временнЫе ограничения. С момента выставления адреса на шину до момента распознавания адреса проходит 10 ns, а с момента распознавания адреса до выставления данных на шину данных — 75 ns.
Итого от выставления адреса на шину до появления актуальных данных на шине данных должно пройти минимум 85 ns. А у нас проходит 62.5 ns.
Нужна задержка.
Здесь-то и наступает момент истины.
Как вставить в код требуемую задержку?
Нужно ещё одно отступление:
- Надеюсь, все знают, что такое intrinsic-и в терминах С/С++. Если кто-то не знает, нужно пояснить. В С/С++ любая сущность, объявленная, но не определённая в пределах компилируемого файла считается внешней. Это относится и к функциям в не меньшей степени, к чем к переменным. Ссылки на внешние функции остаются в скомпилированном объектном файле и будут заменены на обращения к настоящим сущностям только на этапе линковки, если все межмодульные зависимости будут удовлетворены. Не существует никакой разницы между PrivetVasya() и printf() — с точки зрения компилятора обе абсолютно равнозначны и про обе можно сказать «да это просто какие-то внешние функции». Когда идиотские учебники или учителя-недоучки начинают говорить «встроенная функция языка printf()» (а это очень популярный бред) — надо понимать, что это просто глупость, что в язык ничего такого не встроено, что компилятор обрабатывает вызов к printf() на тех же условиях, что и вызов к любой другой функции, да хоть в соседнем файле реализованной. Что касается той же printf() — то это не встроенная функция языка, а функция стандартной библиотеки языка. Стандарт на язык эту функцию описывает, провозглашает её наличие в стандартной библиотеке, но сам компилятор к стандартной библиотеке отношения не имеет — она может появиться на этапе линковки, а может и вообще не появляться. Тем не менее, есть по истине встроенные функции, для которых в компиляторе на самом деле реализована особая обработка — они называются intrinsic-ами. У разных компиляторов набор intrinsic-ов разный. Intrinsic-ом может быть и функция, которая штатно должна жить в стандартной библиотеке. При вызове intrinsic-функции компилятор генерирует особый код, характерный именно для данной функции: не генерируется никакого call-а, не будет никакого реального вызова и возврата, а будет несколько инструкций, выполняющих нужную задачу. Например очень распространённый intrinsic memcpy() компилируется не в вызов какой-то функции, а в инструкцию repnz movs (пример для x86).
Понятное дело, что в стандартной библиотеке С (libc) для AVR есть некоторые функции, которые обеспечивают задержку. Естественно, это полновесные функции, которые внутри крутят цикл. Мне нужна задержка в 1—2 такта, и естественно, что для меня такие тяжеловесные функции не подходят. Сделать задержку в 1 такт полноценной (и обыкновенной) функцией нельзя: даже если это будет совершенно пустая функция, инструкция call выполняется за 4 такта, и инструкция ret — ещё 4 такта, итого 8 тактов на вызов пустой функции.
Без малейшей лишней мысли понятно, что задержки в единицы тактов (меньше 8) могут быть реализованы только intrinsic-ами. И теперь, скрестив пальцы, спросим: а есть ли в avr-gcc delay-функции (функции задержки), выполненные как intrinsic-и?
К счастью, пока всё хорошо, действительно есть такой intrinsic — функция называется __builtin_avr_delay_cycles().
На первый взгляд, если между выставлением адреса на шину адреса и считыванием байта с шины данных вклинить одну лишнюю инструкцию, то с учётом первой инструкции пройдёт 2 × 62.5ns = 125ns, что больше 85 ns.
То есть мы могли бы сделать так:
- Код: Выделить всё
void DoRead(uint8_t *dstbuf)
{
uint8_t i;
for(i = 0; i < 128; i++)
{
ADDR_BUS = i;
__builtin_avr_delay_cycles(1);
dstbuf[i] = DATA_BUS;
}
}
Во что бы это могло бы скомпилироваться?
Я не зря писал выше про перестановку инструкций. Поскольку __builtin_avr_delay_cycles — это intrinsic, то есть кодогенерация вызова этой функции происходит в самом сердце компилятора, компилятор имеет возможность для создания задержки именно в этом месте перенести сюда какую-нибудь инструкцию (занимающую 1 такт), не нарушая зависимостей по «побочным эффектам».
И я не зря просил обратить внимание, что регистр R25 используется только для выставления адреса (и не используется для доступа к буферу, несмотря на исходный сишный код). Поэтому инструкцию, инкрементирующую R25, компилятор может свободно подымать выше вплоть до того места, где нам нужна однотактная задержка, так как такой перенос никак не влияет на логику кода, но зато обеспечивает желаемую задержку в нужном месте:
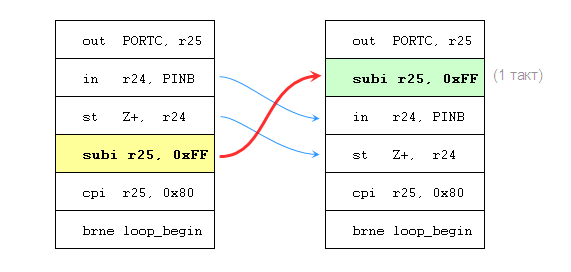
Выглядит замечательно: в цикле как было, так и осталось 6 инструкций, общее время выполнения одной итерации (любой кроме последней) — 8 тактов, а в нужном нам месте возникла задержка в 1 такт.
Но если внимательно посмотреть ту часть даташита, которая описывает чтение данных с порта, там можно обнаружить следующее:

Эта временная диаграмма говорит нам, что инструкция in r17, PINx прочитает с порта значение, которое будет защёлкнуто на середине предыдущего цикла. Каждый новый процессорный цикл начинается по восходящему фронту тактирующего сигнала, соответственно падающий фронт приходится на середину цикла. В начале цикла (по восходящему фронту) защёлка становится прозрачной и остаётся такой до спадающего фронта (заштрихованная область на диаграмме). По спадающему фронту защёлка защёлкивается и считанное с внешних пинов значение остаётся неизменным в самой зашёлке, а при следующем же восходящем фронте это считанное значение сдвигается в PINx.
Это означает, что однотактной задержки между выставлением адреса и считыванием данных мало, потому что в этом случае будет считано то состояние шины данных, в котором она была на середине выполнения задерживающей инструкции, а в этот момент времени с момента выставления адреса на шину прошло только полцикла (полтакта). Поэтому нужна задержка в два такта, ибо в этом случае с момента выставления адреса до реального момента защёлкивания состояния шины данных будет проходить уже полтора цикла.
Естественно, для меня это не сюрприз: я специально изначально написал «На первый взгляд».
Ну окей, тогда так:
- Код: Выделить всё
void DoRead(uint8_t *dstbuf)
{
uint8_t i;
for(i = 0; i < 128; i++)
{
ADDR_BUS = i;
__builtin_avr_delay_cycles(2);
dstbuf[i] = DATA_BUS;
}
}
Во что бы это могло скомпилироваться?
Опять же, создать в коде задержку на два цикла (такта) компилятор вполне может перемещением инструкций. В прошлый раз мы двигали инкрементирующую инструкцию, но ничего не мешает нам передвинуть и сравнивающую инструкцию (cpi R25, 0x80):

Вот у нас есть уже 2 такта задержки между out и in, а в цикле по прежнему 6 инструкций, выполнение которых занимает 8 процессорных циклов (для всех итераций, кроме последней, ибо она займёт 7 тактов — не выполнившееся ветвление берёт 1 цикл, вместо двух).
Такая перестановка возможна, так как она не нарушает логики работы кода: инструкция сравнения не обязана идти вплотную к инструкции ветвления, а просто как и в большинстве процессорных архитектур, инструкция сравнения выставляет флаги в статусном регистре, а инструкция условного перехода проверяет эти флаги. Поскольку инструкции in и st вообще никак не трогают флаги, их можно ставить между cpi и brne.
Ох и люблю же я тянуть...
А теперь самое главное.
Во что это реально скомпилируется?
Я даже не буду показывать код, а просто скажу, что в случае __builtin_avr_delay_cycles(1); между out и in вставляется одна инструкция nop, а в случае с __builtin_avr_delay_cycles(2); вставляется инструкция rjmp .+0, которая по сути выполняет прыжок на следующую прямо за ней инструкцию (сжирая 2 процессорных цикла, как и требуется).
Иными словами, никакой перестановки инструкций компилятор не делает, хотя, естественно, оптимизация включена, и это при том, что у компилятора была возможность создать задержки в требуемых программистом местах, не увеличивая при этом общее время выполнения одной итерации цикла.
Занавес...
Такты — на вес золота
В современном мире, где десктопные и мобильные процессоры (молчу про серверные) могут иметь больше десятка ядер, а тактовые частоты превышают 1 ГГц, и поэтому софт может выполнять миллионы лишних инструкций просто потому, что программисту не хотелось поднапрячь мозги и потому что числа хранят в строках, многим может показаться, что одна лишняя инструкция — это ничтожная мелочь.
В мире электроники, где системы можно отнести к системам реального времени, а тактовые частоты не такие большие (во имя дешевизны чипов), такты могут быть на вес золота.
Если подумать, что один и тот же кусочек кода может выполняться 10 млн раз, легко прикинуть, сколько времени сожрут лишние два такта. В нашем случае (для нашего цикла) лишние инструкции увеличивают время выполнения одной итерации на 25%! То есть то, что могло выполниться за минуту, будет выполняться за 75 секунд. И это бездарные 25 процентов, никому не нужные, потому что избежать их было легче лёгкого.
Помимо «вместо 60 секунд оно займёт 75» (что в реальности может оказаться намного хуже, потому что мы рассматривали наипростейший цикл и одну единственную задержку, а в реальном деле, разумеется, мест, где нужные такие задержки на общение с периферией — намного больше), которое несёт чисто психологически негативный эффект (устройство всё равно будет работать, но те так быстро, как хотелось автору/заказчику), есть куда более серьёзный момент.
Зачастую, приходится обрабатывать какой-то поток данных или генерировать какой-то поток данных (или сигнал). И в этом случае, взяв тактовую частоту и скорость потока данных (или частоту дискретизации сигнала) становится понятно, что, к примеру, на один байт потока можно потратить 80 тактов — и это потолок, который никак нельзя сдвинуть (превысить). Потому что иначе данные приходят быстрее, чем мы успеваем их обрабатывать, и тогда нам нужна память для очереди, где они будут накапливаться, что впрочем звучит как катастрофа, потому если нам не обещают перерывов в потоке данных, какой бы большой ни была память, она рано или поздно кончится.
Один из примеров, который я люблю приходить: однажды мне пришлось генерировать некий сигнал с частотой 44,1 кГц (несложно догадаться, что это за сигнал). Взвесив все за и против, было принято решение понизить частоту дискретизации до 40 кГц. При максимально возможной частоте для AVR-чипов того времени в 20 МГц (сейчас есть чипы AVR, которые могут работать и на 24 МГц) получалось, что на один отсчёт (sample) можно затратить не более 500 тактов. На самом же деле, поскольку кроме генерации устройству приходилось делать ещё много чего, то по сути даже меньше, чем 500 тактов.
С учётом того, что сигнал генерировался по очень сложным законам, которые требовали использования FP-математики, и на фоне того, что никакого FPU в AVR нет, и всю FP-математику приходилось эмулировать ручками, используя только целочисленные инструкции, в эти 500 тактов я никак не мог уложиться.
Тогда я выкрутился так: всю математику у меня выполнял не сам чип, а внешние цепи на операционных усилителях — в лучших традициях аналоговых компьютеров. Собственно говоря, именно для этой задачи — выполнения математических операцией — операционные усилители и были изобретены, откуда и имеют своё название.
Так что такты — на вес золота. А avr-gcc позорно эти такты профукал.
И какой же выход?
Конечно же можно, чуть подумав, изменить сишный код, чтобы после компиляции инструкции выстроились в нужном нам порядке.
Например так:
- Код: Выделить всё
void DoRead(uint8_t * dst)
{
uint8_t i;
for(ADDR_BUS = i = 0, __builtin_avr_delay_cycles(1); i < 128;)
{
*dst++ = DATA_BUS;
ADDR_BUS = ++i;
}
}
Что скомпилируется в:
- Код: Выделить всё
DoRead:
movw r30, r24
out PORTC, r1 ; Компилятор также создаёт преиниц. код, который заносит 0 в r1 для подобных случаев
nop
ldi r25, 0
loop_begin:
in r24, PINB
st Z+, r24
subi r25, 0xFF
out PORTC, r25
cpi r25, 0x80
brne loop_begin
ret
По прежнему всё те же 6 инструкций на одну итерацию, только теперь между выставлением адреса и считыванием есть требуемая задержка.
Но знаете что? Это код, который успешно скомпилируется, который успешно будет работать на чипе, но вообще-то это отвратительный сишный код, потому что он нарушает саму идею написани на Си.
Нет никакого удовольствия писать на Си, если после добавления каждой строчки Си-кода нужно смотреть ассемблерный листинг и проверять, а в том ли порядке легли инструкции, какой обеспечит нужную задержку?
Но, что более важно, идея программирования на Си примерно такая: программа начинает иметь немного декларативный характер. Вы просто диктуете компилятору, какие манипуляции данными и в каком порядке должны произойти, и вас ни капли не волнует, как он это сделает — какие аппаратные ресурсы привлечёт, как распорядится регистрами, какие выполнит инструкции. Он может использовать разные регистры, разные инструкции, в любом порядке, но что играет роль, так это то, что манипуляции над данными произойдёт именно так, как указал программист.
—Расшибись в лепёшку, но сделай так, чтобы требуемые манипуляции совершились, и сделай это максимально быстрым путём, пожалуйста.
Это именно то, что позволяет писать на Си один код, который можно скомпилировать под десятки разных архитектур, и он будет работать везде, потому что мы просто декларируем компилятору, в какой момент какие вещи над данными должны быть сделаны (а не как именно). И мы не думаем над порядком инструкций, потому что компилятор выбирает оптимальный и правильный. Если строки сишного кода приходится подгонять под резултирующий ассемблерный листинг, то это уже си-программирование с дурным запахом.
И вешеприведённый последний сишный листинг плох тем, что если его скомпилировать под некий гипотетический чип, у которого тактовая частота будет в 2 раз больше, то получишившийся код опять не будет работать.
Хорошее программирование Си состоит в том, что я не подгоняю сишный код под реалии выполнения инструкций, а просто пишу, что мне нужно сделать.
А мне нужно выставить адрес, подождать, и считать данные.
Значит это должно быть написано так:
- Код: Выделить всё
ADDR_BUS = i;
SMART_DELAY_NS(MEMORY_DELAY);
dstbuf[i] = DATA_BUS;
Где SMART_DELAY_NS — просто макрос, который задержку в наносекундах пересчитывает в количество тактов, которое нужно передать __builtin_avr_delay_cycles(), чтобы в нужном месте возникла нужная задержка.
То есть примерно такой:
- Код: Выделить всё
#define CLOCK_PERIOD (1000000000 / F_CPU)
#define SMART_DELAY_NS(ns) __builtin_avr_delay_cycles((ns) / CLOCK_PERIOD + 1)
И всё! Этот портируемый код скомпилировался бы под чип с любой тактовой частотой. Потому что будь компиляция intrinsic-функции __builtin_avr_delay_cycles() достаточно умной (или будь оптимизатор достаточно умным), при препроцессинге аргумент для __builtin_avr_delay_cycles() подставился бы нужный, а сам «вызов» __builtin_avr_delay_cycles() заставил бы компилятор создать требуемую задержку переставляя инструкции, которые можно переставлять, и не увеличивая время выполнения кода. И только когда всех инструкций, которые можно переставить, не хватало бы для обеспечения запрошенной задержки, было бы допустимо добавлять в код NOP-ы для доп. тактов.
Ассемблер vs. Си?
Но увы, компилятор оказался не таким умным, а поэтому в очередной раз придётся писать код на ассемблере, хотя очень хотелось написать на Си.
В довесок
Кто-то может сказать:
— Ты хочешь от компилятора слишкого много: скорей всего, компиляция intrinsic-функции просто порождает нужное количество паразитных инструкций и не имеет права осуществлять перестановки других инструкций, и лишь оптимизатор имеет полномочия перекраивать код, вырезая и переставляя инструкции, но он не имеет возможности знать, можно ли ликвидировать nop-инструкцию, ибо помимо случаев, когда nop появился из-за использования delay-функции, nop мог появится из-за ассемблерной вставки, и тогда, если его убрать, будет много криков, что компилятор чудит и правит куски асм-кода, вставленные асм-вставками.
Прекрасно понимаю, что скорее всего именно так всё и обстоит. Но в разработке компиляторов обычно участвуют умные люди, а нужно быть дураком, чтобы не догадаться в структуре данных, представляющей сгенерированную инструкцию, не сделать флаг, который бы информировал оптимизатор о том, является ли нахождение этой инструкции в этом месте железной волей программиста (то есть инструкция была частью ассемблерной вставки), либо же она была сгенерирована автоматически, и значит этот кусочек можно перекраивать как угодно.
Так что это вовсе не оправдание.
Но и помимо того, что компилятор делает задержки nop-ами, вместо того, чтобы подставить туда полезные инструкции, даже на этом крохотном демонстрационном примере есть ещё одно проявление плохой кодогенерации.
Обратите внимание, как компилируется условие продолжение/выхода for-цикла i < 128.
В принципе, компилятору хватает ума понять, что, поскольку i объявлена без volatile и указатель на i внутри цикла не передаётся в какие-то внешние процедуры, которые могли бы сделать с её значением что угодно), значение переменой i никогда не достигнет значения больше 128.
Поэтому он вместо {сравнить; если меньше — вернуться в начало цикла} использует подход {сравнить; если не равно — вернуться в начало цикла}. Вот только выгоды от такого трюка — никакой.
Зато есть кое-что, до чего компилятор не догадался. AVR, как и множество других процессорных архитектур, для представления отрицательных чисел пользуется идеей, что отрицательные числа имеют старший бит равный единице, причём за 127 (0x7F) следует –128 (0x80), то есть все числа, которые больше 127 в своей беззнаковой интерпретации, в знаковой интерпретации имеют смысловое значение равное (беззнаковое – 256), (поэтому 255 (0xFF) означает минус 1).
А нам, напомню, нужно выходить из цикла, когда i меняется со 127 на 128. А это, при взгляде с другой стороны, означает, что выходить из цикла нужно, когда старший бит регистра R25 ставится единичкой (до этого по ходу цикла он был 0). А у AVR во флаговом (статусном) регистре есть флаг N, смысл которого — «результат последней операции был отритцательным». Или, другими словами: после арифметических операций флаг N равен старшему биту результата операции.
А раз есть флаг, есть и соответствующая инструкция условного перехода, вернее, даже две:
- BRMI — Branch if Minus — переход осуществляется, если результат операции был отрицательным (то есть если N = 1).
- BRPL — Branch if Plus — переход осуществляется, если результат был не отрицательным (то есть если N = 0).
Нам нужно возвращаться в начало цикла, если i не достиг 0x80 (128), то есть если N сброшен.
Это означает, что вместо пары инструкций (cpi+brne)
- Код: Выделить всё
subi r25, 0xFF
cpi r25, 0x80
brne loop_begin
можно было обойтись одной (brpl):
- Код: Выделить всё
subi r25, 0xFF
brpl loop_begin
Вот ещё один сэкономленный такт (cpi занимает один процессорный цикл).
А такты — на вес золота (иногда флеш-память, в которой хранится код — тоже).
На глупой обработке __builtin_avr_delay_cycles() мы получали увеличение времени выполнения на 25%, а здесь из-за использования лишней инструкции — увеличение времени выполнения на 14.2%.
_______
Предлагаю давать ссылку на этот топик, если вам доведётся встретить холивар «Си vs. ассемблер», проводимый в среде электронщиков и программистов для микроконтроллеров. Понимаю, что в целом тематика VBStreets далека от этой области знаний, но, тем не менее, я неоднократно встречал здесь людей, связанных с темой.


