

–Я—А–Њ–і–µ–Љ–Њ–љ—Б—В—А–Є—А—Г—О –љ–∞ –±–Њ–ї–µ–µ –Љ–µ–љ–µ–µ —Г–њ—А–Њ—Й—С–љ–љ–Њ–Љ –њ—А–Є–Љ–µ—А–µ.
–Э–∞–њ–Є—Б–∞–ї —П –њ—А–Є–Љ–µ—А–љ–Њ —В–∞–Ї—Г—О –њ—А–Њ—Ж–µ–і—Г—А—Г:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
#define ADDR_BUS PORTC
#define DATA_BUS PINB
void DoRead(uint8_t *dstbuf)
{
uint8_t i;
for(i = 0; i < 128; i++)
{
ADDR_BUS = i;
dstbuf[i] = DATA_BUS;
}
}
–Ъ–∞–Ї –і–Њ–ї–ґ–љ–Њ –±—Л—В—М –Њ—З–µ–≤–Є–і–љ–Њ, –Ї CPU –њ–Њ–і–Ї–ї—О—З–µ–љ–Њ –љ–µ–Ї–Њ—В–Њ—А–Њ–µ —Г—Б—В—А–Њ–є—Б—В–≤–Њ (–±—Г–і–µ–Љ –љ–∞–Ј—Л–≤–∞—В—М –µ–≥–Њ –њ–∞–Љ—П—В—М—О) —Б –њ–Њ–Љ–Њ—Й—М—О –і–≤—Г—Е –њ–∞—А–∞–ї–ї–µ–ї—М–љ—Л—Е —И–Є–љ. 7-–±–Є—В–љ–∞—П —И–Є–љ–∞ –∞–і—А–µ—Б–∞ –њ–Њ–≤–µ—И–µ–љ–∞ –љ–∞ Port C, –∞ 8-–±–Є—В–љ–∞—П —И–Є–љ–∞ –і–∞–љ–љ—Л—Е вАФ –љ–∞ Port B. –£—Б—В—А–Њ–є—Б—В–≤–Њ –њ—А–Њ—Б—В–Њ –Є—В–µ—А–∞—В–Є–≤–љ–Њ –≤—Л—Б—В–∞–≤–ї—П–µ—В –∞–і—А–µ—Б (–Њ—В 0 –і–Њ 127) –љ–∞ —И–Є–љ—Г –∞–і—А–µ—Б–∞, –њ–Њ—Б–ї–µ —З–µ–≥–Њ —Б—З–Є—В—Л–≤–∞–µ—В –±–∞–є—В –і–∞–љ–љ—Л—Е —Б —И–Є–љ—Л –і–∞–љ–љ—Л—Е –Є –Ј–∞–њ–Є—Б—Л–≤–∞–µ—В –µ–≥–Њ –≤ –±—Г—Д–µ—А. –Ф—Г–Љ–∞—О, –≤—Б—С –њ–Њ–љ—П—В–љ–Њ.
–Ґ–µ–њ–µ—А—М –њ–Њ—Б–Љ–Њ—В—А–Є–Љ, –≤–Њ —З—В–Њ —Н—В–Њ —Б–Ї–Њ–Љ–њ–Є–ї–Є—А–Њ–≤–∞–ї–Њ—Б—М:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
DoRead:
movw r30, r24
ldi r25, 0x00
loop_begin:
out PORTC, r25
in r24, PINB
st Z+, r24
subi r25, 0xFF
cpi r25, 0x80
brne loop_begin
ret
–Ф–ї—П —В–µ—Е, –Ї—В–Њ –љ–µ –Ј–љ–∞–Ї–Њ–Љ —Б —Б–Є—Б—В–µ–Љ–Њ–є –Ї–Њ–Љ–∞–љ–і –Є –∞—А—Е–Є—В–µ–Ї—В—Г—А–Њ–є AVR, –њ–Њ—П—Б–љ—О –≤ –і–≤—Г—Е —Б–ї–Њ–≤–∞—Е: –Љ–Є–Ї—А–Њ–Ї–Њ–љ—В—А–Њ–ї–ї–µ—А 8-–±–Є—В–љ—Л–є, –≤—Б–µ —А–µ–≥–Є—Б—В—А—Л —Г –љ–µ–≥–Њ 8-–±–Є—В–љ—Л–µ, –∞ –≤–Њ—В –њ–∞–Љ—П—В–Є (SRAM) –Љ–Њ–ґ–µ—В –±—Л—В—М –±–Њ–ї—М—И–µ 256 –±–∞–є—В, –њ–Њ—Н—В–Њ–Љ—Г –∞–і—А–µ—Б–∞ –љ–µ —Г–Љ–µ—Й–∞—О—В—Б—П –≤ 8 –±–Є—В. –Ф–ї—П —Н—В–Њ–≥–Њ –µ—Б—В—М —В—А–Є –њ–∞—А—Л —А–µ–≥–Є—Б—В—А–Њ–≤, –Ї–Њ—В–Њ—А—Л–µ –Њ–±—А–∞–Ј—Г—О—В —В—А–Є 16-–±–Є—В–љ—Л—Е —А–µ–≥–Є—Б—В—А–∞: –њ–∞—А–∞ R27 –Є R26 –Њ–±—А–∞–Ј—Г–µ—В —А–µ–≥–Є—Б—В—А X, –њ–∞—А–∞ R29 –Є R28 вАФ —А–µ–≥–Є—Б—В—А Y, –њ–∞—А–∞ R31 –Є R30 вАФ —А–µ–≥–Є—Б—В—А Z. –≠—В–Њ –Њ—З–µ–љ—М –њ–Њ—Е–Њ–ґ–µ –љ–∞ —В–Њ, –Ї–∞–Ї –≤ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–µ 8080 –±—Л–ї–Є 8-–±–Є—В–љ—Л–µ —А–µ–≥–Є—Б—В—А—Л A, B, C, D, E, H, L —Б –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М—О –Њ–±—К–µ–і–Є–љ–µ–љ–Є—П –≤ 16-–±–Є—В–љ—Л–µ –њ–∞—А—Л BC, DE, HL, –Є–ї–Є –Ї–∞–Ї –≤ 8086 –±—Л–ї–Є –≤–≤–µ–і–µ–љ—Л —Б–µ–≥–Љ–µ–љ—В–љ—Л–µ —А–µ–≥–Є—Б—В—А—Л, —З—В–Њ–±—Л –∞–і—А–µ—Б–Њ–≤–∞—В—М –±–Њ–ї—М—И–µ 64K –њ–∞–Љ—П—В–Є.
–°–Њ–≥–ї–∞—И–µ–љ–Є–µ –Њ –≤—Л–Ј–Њ–≤–µ —В–∞–Ї–Њ–µ, —З—В–Њ –µ–і–Є–љ—Б—В–≤–µ–љ–љ—Л–є –∞—А–≥—Г–Љ–µ–љ—В (–∞–і—А–µ—Б –±—Г—Д–µ—А–∞) –њ–µ—А–µ–і–∞–ї—Б—П –≤ –њ–∞—А–µ R25:R24. –Я–µ—А–≤–∞—П –ґ–µ –Ї–Њ–Љ–∞–љ–і–∞ movw r30, r24 –Ї–Њ–њ–Є—А—Г–µ—В —Н—В–Њ—В –∞–і—А–µ—Б –Є–Ј R25:R24 –≤ –њ–∞—А—Г R31:R30, —В–Њ –µ—Б—В—М –∞–і—А–µ—Б –±—Г—Д–µ—А–∞ –Ј–∞–љ–Њ—Б–Є—В—Б—П –≤ —А–µ–≥–Є—Б—В—А Z.
–Ш–љ—Б—В—А—Г–Ї—Ж–Є—П ldi r25, 0x00 –Є–љ–Є—Ж–Є–∞–ї–Є–Ј–Є—А—Г–µ—В —А–µ–≥–Є—Б—В—А R25 –љ—Г–ї—С–Љ вАФ –≤ –і–∞–ї—М–љ–µ–є—И–µ–Љ —А–µ–≥–Є—Б—В—А R25 –±—Г–і–µ—В –Њ–ї–Є—Ж–µ—В–≤–Њ—А—П—В—М –њ–µ—А–µ–Љ–µ–љ–љ—Г—О i.
–Ф–∞–ї–µ–µ –љ–∞—З–Є–љ–∞–µ—В—Б—П —Ж–Є–Ї–ї: –Є–љ—Б—В—А—Г–Ї—Ж–Є—П out PORTC, r25 –≤—Л—Б—В–∞–≤–ї—П–µ—В —З–Є—Б–ї–Њ –Є–Ј —А–µ–≥–Є—Б—В—А–∞ R25 (—В–Њ –µ—Б—В—М –њ–µ—А–µ–Љ–µ–љ–љ–Њ–є i) –љ–∞ –њ–Њ—А—В ¬ЂC¬ї (—В–Њ –µ—Б—В—М –љ–∞ —И–Є–љ—Г –∞–і—А–µ—Б–∞). –Ш–љ—Б—В—А—Г–Ї—Ж–Є—П in r24, PINB —Б—З–Є—В—Л–≤–∞–µ—В –±–∞–є—В —Б –њ–Њ—А—В–∞ ¬ЂB¬ї (—В–Њ –µ—Б—В—М —Б —И–Є–љ—Л –і–∞–љ–љ—Л—Е) –Є –Ј–∞–љ–Њ—Б–Є—В –µ–≥–Њ –≤ —А–µ–≥–Є—Б—В—А R24. –Ш–љ—Б—В—А—Г–Ї—Ж–Є—П st Z+, r24 –Ј–∞–њ–Є—Б—Л–≤–∞–µ—В —Б—З–Є—В–∞–љ–љ—Л–є –±–∞–є—В (—Е—А–∞–љ—П—Й–Є–є—Б—П –≤ R24) –≤ –њ–∞–Љ—П—В—М –њ–Њ –∞–і—А–µ—Б—Г, –љ–∞—Е–Њ–і—П—Й–µ–Љ—Г—Б—П –≤ —А–µ–≥–Є—Б—В—А–µ Z, –њ–Њ—Б–ї–µ —З–µ–≥–Њ –Є–љ–Ї—А–µ–Љ–µ–љ—В–Є—А—Г–µ—В —А–µ–≥–Є—Б—В—А Z. –Э–∞ x86, –µ—Б–ї–Є –њ–Њ—Д–∞–љ—В–∞–Ј–Є—А–Њ–≤–∞—В—М, —Н—В–Њ –±—Л–ї–∞ –±—Л –Є–љ—Б—В—А—Г–Ї—Ж–Є—П mov byte[reg1++], reg2 (–љ–Њ —В–∞–Ї–Њ–є —Д–Њ—А–Љ—Л –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є mov —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ –Ї–Њ—Б–≤–µ–љ–љ–Њ–є –∞–і—А–µ—Б–∞—Ж–Є–Є —Б –њ–Њ—Б—В-–Є–љ–Ї—А–µ–Љ–µ–љ—В–Њ–Љ –Њ–і–љ–Њ–≥–Њ –Є–Ј —А–µ–≥–Є—Б—В—А–Њ–≤ —Г x86 –љ–µ—В, —Е–Њ—В—П –µ—Б—В—М ¬Ђ—Б—В—А–Њ–Ї–Њ–≤—Л–µ¬ї –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є MOVS/STOS/SCAS/CMPS, –Ї–Њ—В–Њ—А—Л–µ –і–µ–ї–∞–µ—В –Є–љ–Ї—А–µ–Љ–µ–љ—В/–і–µ–Ї—А–µ–Љ–µ–љ—В).
–Ш–љ—Б—В—А—Г–Ї—Ж–Є—П subi r25, 0xFF —Н—В–Њ –њ—А–Њ—Б—В–Њ –њ—А–Є—З—Г–і–ї–Є–≤—Л–є –≤–∞—А–Є–∞–љ—В —Г–≤–µ–ї–Є—З–Є—В—М R25 –љ–∞ –µ–і–Є–љ–Є—Ж—Г (–Њ—В–љ—П–≤, –њ–Њ —Д–∞–Ї—В—Г, 255), —В–Њ –µ—Б—В—М —Н–Ї–≤–Є–≤–∞–ї–µ–љ—В addi r25, 1 –Є–ї–Є inc r25 вАФ —Г–≤–µ–ї–Є—З–Є–≤–∞–µ—В –њ–µ—А–µ–Љ–µ–љ–љ—Г—О i –љ–∞ –µ–і–Є–љ–Є—Ж—Г.
–Ф–∞–ї–µ–µ –Є–љ—Б—В—А—Г–Ї—Ж–Є—П cpi r25, 0x80 —Б—А–∞–≤–љ–Є–≤–∞–µ—В R25 —Б —З–Є—Б–ї–Њ–Љ 128 (–∞–љ–∞–ї–Њ–≥ –≤ x86 вАФ –Є–љ—Б—В—А—Г–Ї—Ж–Є—П cmp), –Є –Ј–∞—В–µ–Љ –Є–љ—Б—В—А—Г–Ї—Ж–Є—П —Г—Б–ї–Њ–≤–љ–Њ–≥–Њ –њ–µ—А–µ—Е–Њ–і–∞ brne loop_begin (–∞–љ–∞–ї–Њ–≥ –≤ x86 вАФ jne) –њ–µ—А–µ–Ї–Є–і—Л–≤–∞–µ—В –љ–∞—Б –љ–∞ —Б–ї–µ–і—Г—О—Й—Г—О –Є—В–µ—А—Ж–Є—О (–Є–ї–Є –Ј–∞–≤–µ—А—И–∞–µ—В —Ж–Є–Ї–ї).
–Х—Й—С —А–∞–Ј —В–Њ—В –ґ–µ –Ї–Њ–і, —Б –Ї–Њ–Љ–Љ–µ–љ—В–∞—А–Є—П–Љ–Є:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
DoRead:
movw r30, r24 ; –£–Ї–∞–Ј–∞—В–µ–ї—М dstbuf –Ј–∞–љ–Њ—Б–Є—В—Б—П –≤ —А–µ–≥–Є—Б—В—А Z (R31:R30)
ldi r25, 0x00 ; i = 0
loop_begin:
out PORTC, r25 ; PORTC = i
in r24, PINB ; –°—З–Є—В—Л–≤–∞–µ–Љ –Ј–љ–∞—З–µ–љ–Є–µ —Б –њ–Њ—А—В–∞ B
st Z+, r24 ; –Ч–∞–њ–Є—Б—Л–≤–∞–µ–Љ –µ–≥–Њ –≤ –њ–∞–Љ—П—В—М –њ–Њ –∞–і—А–µ—Б—Г Z, –Є–љ–Ї—А–µ–Љ–µ–љ—В–Є—А—Г–µ–Љ Z
subi r25, 0xFF ; i++
cpi r25, 0x80 ; i == 128 ?
brne loop_begin ; –Х—Б–ї–Є –љ–µ—В, —В–Њ goto loop_begin
ret ; –Т–Њ–Ј–≤—А–∞—В –Є–Ј –њ—А–Њ—Ж–µ–і—Г—А—Л
–Ш–ї–Є, –і–ї—П —В–µ—Е, –Ї–Њ–Љ—Г –±–ї–Є–ґ–µ x86-–∞–љ–∞–ї–Њ–≥–Є—П (–≤–µ—Б—М–Љ–∞ —Г—Б–ї–Њ–≤–љ–∞—П –Є –љ–∞—В—П–љ—Г—В–∞—П):
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
DoRead:
movw r30, r24 ; mov dx, ax
ldi r25, 0x00 ; mov cl, 0
loop_begin:
out PORTC, r25 ; out PORTC, cl
in r24, PINB ; in bl, PINB
st Z+, r24 ; mov [dx++], bl
subi r25, 0xFF ; sub cl, 255 ; (—Н–Ї–≤–Є–≤–∞–ї–µ–љ—В–љ–Њ add cl, 1 –Є–ї–Є inc cl)
cpi r25, 0x80 ; cmp cl, 128
brne loop_begin ; jne loop_begin
ret ; retn
–Ю—В—Б—О–і–∞ –Љ–Њ–ґ–љ–Њ —Б–і–µ–ї–∞—В—М –≤–∞–ґ–љ–Њ–µ –љ–∞–±–ї—О–і–µ–љ–Є–µ: –≤ —В–Њ –≤—А–µ–Љ—П, –Ї–∞–Ї –≤ –Њ—А–Є–≥–Є–љ–∞–ї—М–љ–Њ–Љ C-–Ї–Њ–і–µ –Ј–љ–∞—З–µ–љ–Є–µ –њ–µ—А–µ–Љ–µ–љ–љ–Њ–є i –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–ї–Њ—Б—М –і–ї—П –і–≤—Г—Е –љ—Г–ґ–і вАФ –і–ї—П –≤—Л—Б—В–∞–≤–ї–µ–љ–Є—П –∞–і—А–µ—Б–∞ –≤ PORTC –Є –і–ї—П –і–Њ—Б—В—Г–њ–∞ –Ї —Н–ї–µ–Љ–µ–љ—В—Г –±—Г—Д–µ—А–∞ (dstbuf[i]), –њ–Њ—Б–ї–µ –Ї–Њ–Љ–њ–Є–ї—П—Ж–Є–Є —Н—В–∞ –њ–µ—А–µ–Љ–µ–љ–љ–∞—П (—А–µ–≥–Є—Б—В—А R25) –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П —В–Њ–ї—М–Ї–Њ –і–ї—П –≤—Л—Б—В–∞–≤–ї–µ–љ–Є—П –∞–і—А–µ—Б–∞ –љ–∞ —И–Є–љ—Г, –∞ –і–ї—П –і–Њ—Б—В—Г–њ–∞ –Ї –±—Г—Д–µ—А—Г –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П —А–µ–≥–Є—Б—В—А Z, –Ї–Њ—В–Њ—А—Л–є –≤ –њ—А–Є–љ—Ж–Є–њ–µ –љ–µ–Ј–∞–≤–Є—Б–Є–Љ –Њ—В R25.
–Ш–љ—Л–Љ–Є —Б–ї–Њ–≤–∞–Љ–Є, –њ–Њ–ї—Г—З–µ–љ–љ—Л–є –∞—Б—Б–µ–Љ–ї–µ—А–љ—Л–є –Ї–Њ–і –±–Њ–ї—М—И–µ –њ–Њ—Е–Њ–ґ –љ–∞ —В–Њ, —З—В–Њ –Є—Б—Е–Њ–і–љ—Л–є —Б–Є—И–љ—Л–є –Ї–Њ–і –±—Л–ї —В–∞–Ї–Є–Љ:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
void DoRead(uint8_t *dstbuf)
{
uint8_t i;
for(i = 0; i < 128; i++)
{
ADDR_BUS = i;
*(dstbuf++) = DATA_BUS;
}
}
–Я–Њ–Ї–∞ –≤—Б—С —Е–Њ—А–Њ—И–Њ –Є –њ—А–∞–≤–Є–ї—М–љ–Њ, –Њ—З–µ–љ—М —А–∞–і—Г–µ—В, —З—В–Њ avr-gcc –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В —Д–Њ—А–Љ—Г –∞–і—А–µ—Б–∞—Ж–Є–Є —Б –њ–Њ—Б—В-–Є–љ–Ї—А–µ–Љ–µ–љ—В–Њ–Љ (st Z+, r24 –Ј–∞—В—А–∞—З–Є–≤–∞–µ—В –љ–∞ –≤—Л–њ–Њ–ї–љ–µ–љ–Є–µ 2 —Ж–Є–Ї–ї–∞ (—В–∞–Ї—В–∞), –≤ —В–Њ –≤—А–µ–Љ—П –Ї–∞–Ї –≤—Л—З–Є—Б–ї–µ–љ–Є–µ –љ–Њ–≤–Њ–≥–Њ –Ј–љ–∞—З–µ–љ–Є—П Z —З–µ—А–µ–Ј —Б–ї–Њ–ґ–µ–љ–Є–µ –Є–Ј–љ–∞—З–∞–ї—М–љ–Њ–≥–Њ dstbuf –Є R25 –Ј–∞–љ—П–ї–Њ –±—Л –Ї—Г–і–∞ –і–Њ–ї—М—И–µ, –∞ st Z, R24 (–±–µ–Ј –њ–Њ—Б—В-–Є–љ–Ї—А–µ–Љ–µ–љ—В–∞) –≤—Б—С —А–∞–≤–љ–Њ –±—Л –њ–Њ—В—А–µ–±–Њ–≤–∞–ї–∞—Б—М).
–Ґ–µ–њ–µ—А—М –љ–µ–±–Њ–ї—М—И–Њ–µ –Њ—В—Б—В—Г–њ–ї–µ–љ–Є–µ:
- –Э–Є –і–ї—П –Ї–Њ–≥–Њ –љ–µ –і–Њ–ї–ґ–љ–Њ –±—Л—В—М —Б–µ–Ї—А–µ—В–Њ–Љ, —З—В–Њ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А—Л –≤ –Њ–±—Й–µ–є —Б–≤–Њ–µ–є –Љ–∞—Б—Б–µ –≤–Њ –Є–Љ—П –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є–Є –Љ–Њ–≥—Г—В –ї–Є–Ї–≤–Є–і–Є—А–Њ–≤–∞—В—М –Є–ї–Є –Ї–∞–Ї –Љ–Є–љ–Є–Љ—Г–Љ –њ–µ—А–µ–Љ–µ—Й–∞—В—М (–њ–µ—А–µ—Б—В–∞–≤–ї—П—В—М –Љ–µ—Б—В–∞–Љ–Є) –Њ–і–Є–љ–Њ—З–љ—Л–µ –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є –Є–ї–Є –±–ї–Њ–Ї–Є –Є–љ—Б—В—А—Г–Ї—Ж–Є–є. –Э–∞–њ—А–Є–Љ–µ—А, –µ—Б–ї–Є –≤ –љ–∞—З–∞–ї–µ —Д—Г–љ–Ї—Ж–Є–Є –Њ–±—К—П–≤–ї–µ–љ—Л –њ–µ—А–µ–Љ–µ–љ–љ—Л–µ, –Ї–Њ—В–Њ—А—Л–µ –љ–∞ –≤—Б—С–Љ –њ—А–Њ—В—П–ґ–µ–љ–Є–Є —Д—Г–љ–Ї—Ж–Є–Є —В–∞–Ї –љ–Є–≥–і–µ –Є –љ–µ –Є—Б–њ–Њ–ї—М–Ј—Г—О—В—Б—П, —Е–Њ—А–Њ—И–Є–є –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –≤–Њ–Њ–±—Й–µ —Г—Б—В—А–∞–љ–Є—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ —Н—В–Є—Е –њ–µ—А–µ–Љ–µ–љ–љ—Л—Е: –љ–µ –±—Г–і–µ—В —А–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞—В—М –њ–Њ–і –љ–Є—Е –Љ–µ—Б—В–Њ –≤ —Б—В–µ–Ї–µ/–≤ —А–µ–≥–Є—Б—В—А–∞—Е –Є –љ–µ –±—Г–і–µ—В –≥–µ–љ–µ—А–Є—А–Њ–≤–∞—В—М –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є, –њ—А–Њ–Є–Ј–≤–Њ–і—П—Й–Є–µ –Є–љ–Є—Ж–Є–∞–ї–Є–Ј–∞—Ж–Є—О. –Х—Б–ї–Є –њ–µ—А–µ–Љ–µ–љ–љ–∞—П –±—Л–ї–∞ –Њ–±—К—П–≤–ї–µ–љ–∞ –≤ –љ–∞—З–∞–ї–µ —Д—Г–љ–Ї—Ж–Є–Є, –љ–Њ –љ–∞ –≤—Б—С–Љ –њ—А–Њ—В—П–ґ–µ–љ–Є–Є –љ–µ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П, –∞ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П —В–Њ–ї—М–Ї–Њ –≤ —Б–∞–Љ–Њ–Љ –Ї–Њ–љ—Ж–µ, –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –Ј–∞–њ—А–Њ—Б—В–Њ –Љ–Њ–ґ–µ—В –Є–љ–Є—Ж–Є–∞–ї–Є–Ј–∞—Ж–Є—О —Н—В–Њ–є –њ–µ—А–µ–Љ–µ–љ–љ–Њ–є –њ–µ—А–µ–Љ–µ—Б—В–Є—В—М –±–ї–Є–ґ–µ –Ї –Ї–Њ–љ—Ж—Г –њ—А–Њ—Ж–µ–і—Г—А—Л. –Ъ–Њ–Љ–њ–Є–ї—П—В–Њ—А —А—Г–Ї–Њ–≤–Њ–і—Б—В–≤—Г–µ—В—Б—П –Ї–Њ–љ—Ж–µ–њ—Ж–Є–µ–є –њ–Њ–±–Њ—З–љ—Л—Е —Н—Д—Д–µ–Ї—В–Њ–≤: –µ—Б–ї–Є –і–µ–є—Б—В–≤–Є–µ1 –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В –љ–µ–Ї–Є–є –њ–Њ–±–Њ—З–љ—Л–є —Н—Д—Д–µ–Ї—В, –Ї–Њ—В–Њ—А—Л–є –≤–∞–ґ–µ–љ –і–ї—П –і–µ–є—Б—В–≤–Є—П2, —В–Њ –≤ —Б–Ї–Њ–Љ–њ–Є–ї–Є—А–Њ–≤–∞–љ–љ–Њ–Љ –Ї–Њ–і–µ –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є, —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й–Є–µ —Н—В–Є–Љ –і–µ–є—Б—В–≤–Є—П–Љ, –±—Г–і—Г—В –Є–і—В–Є –Є–Љ–µ–љ–љ–Њ –≤ —В–∞–Ї–Њ–Љ –њ–Њ—А—П–і–Ї–µ, –≤ –њ—А–Њ—В–Є–≤–љ–Њ–Љ —Б–ї—Г—З–∞–µ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –≤–Њ–ї–µ–љ –Є—Е –њ–µ—А–µ—Б—В–∞–≤–Є—В—М –Є–ї–Є –≤–Њ–Њ–±—Й–µ –≤—Л–Ї–Є–љ—Г—В—М –і–µ–є—Б—В–≤–Є–µ1, –µ—Б–ї–Є –Њ–љ–Њ –љ–µ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В –љ–Є–Ї–∞–Ї–Є—Е –њ–Њ–±–Њ—З–љ—Л—Е —Н—Д—Д–µ–Ї—В–Њ–≤ (–Є–ї–Є –Њ—В –њ–Њ–±–Њ—З–љ—Л—Е —Н—Д—Д–µ–Ї—В–Њ–≤, –њ—А–Њ–Є–Ј–≤–Њ–і–Є–Љ—Л—Е –і–µ–є—Б—В–≤–Є–µ–Љ, –љ–Є–Ї–∞–Ї–Є–µ –і—А—Г–≥–Є–µ –і–µ–є—Б—В–≤–Є—П –љ–µ –Ј–∞–≤–Є—Б—П—В). –Т —Ж–µ–ї–Њ–Љ, –ї–Њ–≥–Є–Ї–∞ –Ї–Њ–Љ–њ–Є–ї–Є—А–Њ–≤–∞–љ–Є—П –°-–Ї–Њ–і–∞ –њ–Њ—Б—В—А–Њ–µ–љ–∞ –Є–Ј —Г–±–µ–ґ–і–µ–љ–Є—П (–њ—А–µ–і–њ–Њ–ї–Њ–ґ–µ–љ–Є—П), —З—В–Њ —В–µ–Ї—Г—Й–Є–є –Ї–Њ–і –≤—Л–њ–Њ–ї–љ—П–µ—В—Б—П –µ–і–Є–љ—Б—В–≤–µ–љ–љ—Л–Љ –њ–Њ—В–Њ–Ї–Њ–Љ, –Є –≤—Б–µ –њ–µ—А–µ–Љ–µ–љ–љ—Л–µ (–Ї–∞–Ї –≥–ї–Њ–±–∞–ї—М–љ—Л–µ —В–∞–Ї –Є –ї–Њ–Ї–∞–ї—М–љ—Л–µ) –Љ–Њ–≥—Г—В –Є–Ј–Љ–µ–љ—П—В—М—Б—П —В–Њ–ї—М–Ї–Њ —В–µ–Ї—Г—Й–Є–Љ –њ–Њ—В–Њ–Ї–Њ–Љ (–Є –љ–Є–Ї–µ–Љ –і—А—Г–≥–Є–Љ), –њ–Њ—Н—В–Њ–Љ—Г –µ—Б–ї–Є —В–µ–Ї—Г—Й–Є–є –Ї–Њ–і –њ—А–Њ—З–Є—В–∞–ї –Ј–љ–∞—З–µ–љ–Є–µ –њ–µ—А–µ–Љ–µ–љ–љ–Њ–є –Є–Ј –њ–∞–Љ—П—В–Є, –Є –њ–Њ–Ї–∞ —З—В–Њ —П–≤–љ–Њ —В—Г–і–∞ –љ–Є—З–µ–≥–Њ –љ–µ –Ј–∞–њ–Є—Б—Л–≤–∞–ї, –љ–Њ–≤–Њ–µ –Ј–љ–∞—З–µ–љ–Є–µ –љ–µ –±—Г–і—Г—В –њ–µ—А–µ—З–Є—В–∞–љ–Њ, –Є–ї–Є, –µ—Б–ї–Є –ґ–µ —В–µ–Ї—Г—Й–Є–є –Ї–Њ–і –њ—А–Є—Б–≤–∞–Є–≤–∞–µ—В –њ–µ—А–µ–Љ–µ–љ–љ–Њ–є –Ј–љ–∞—З–µ–љ–Є–µ, –љ–Њ –і–∞–ї—М—И–µ –Њ–љ–Њ –љ–Є–≥–і–µ –љ–µ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П, –њ—А–Є—Б–≤–Њ–µ–љ–Є—П –љ–µ –±—Г–і–µ—В, –њ–Њ—В–Њ–Љ—Г —З—В–Њ —Б—З–Є—В–∞–µ—В—Б—П, —З—В–Њ –Ї—А–Њ–Љ–µ –Є—Б–њ–Њ–ї–љ—П—О—Й–µ–≥–Њ—Б—П –≤ –і–∞–љ–љ—Л–є –Љ–Њ–Љ–µ–љ—В –Ї–Њ–і–∞ —Н—В–Њ –Ј–љ–∞—З–µ–љ–Є–µ –љ–Є–Ї–Њ–Љ—Г –±–Њ–ї—М—И–µ –љ–µ –љ—Г–ґ–љ–Њ. –І—В–Њ –ґ–µ –Ї–∞—Б–∞–µ—В—Б—П –њ–µ—А–µ—Б—В–∞–љ–Њ–≤–Њ–Ї –Є–љ—Б—В—А—Г–Ї—Ж–Є–є, —В–Њ —Н—В–Њ –Њ—З–µ–љ—М –Є–љ—В–µ–љ—Б–Є–≤–љ–Њ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –і–ї—П –≥–µ–љ–µ—А–∞—Ж–Є–Є –Ї–Њ–і–∞ –і–ї—П —Б—Г–њ–µ—А—Б–Ї–∞–ї—П—А–љ—Л—Е (—В–Њ –µ—Б—В—М –Љ–љ–Њ–≥–Њ–Ї–Њ–љ–≤–µ–є–µ—А–љ—Л—Е) CPU, —В–Њ –µ—Б—В—М –і–ї—П —Б–Њ–≤—А–µ–Љ–µ–љ–љ–Њ–≥–Њ x86 –≤ —З–∞—Б—В–љ–Њ—Б—В–Є вАФ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –њ–Њ—Б—В–∞—А–∞–µ—В—Б—П –њ–∞—А—Г –Є–љ—Б—В—А—Г–Ї—Ж–Є–є, –Њ–±—А–∞—Й–∞—О—Й—Г—О—Б—П –Ї –Њ–і–љ–Њ–Љ—Г –Є —В–Њ–Љ—Г –ґ–µ —А–µ–≥–Є—Б—В—А—Г, —А–∞–Ј–±–∞–≤–Є—В—М —В—А–µ—В—М–µ–є –Є–љ—Б—В—А—Г–Ї—Ж–Є–µ–є, –Њ–±—А–∞—Й–∞—О—Й–µ–є—Б—П –Ї –Ї–∞–Ї–Њ–Љ—Г-–љ–Є–±—Г–і—М –і—А—Г–≥–Њ–Љ—Г —А–µ–≥–Є—Б—В—А—Г, –њ–Њ—В–Њ–Љ—Г —З—В–Њ —Н—В–Њ –і–∞—Б—В –±–Њ–ї—М—И—Г—О —Б–Ї–Њ—А–Њ—Б—В—М –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П.
–І—В–Њ–±—Л —Г–Љ–µ—А–Є—В—М –њ—Л–ї —Н—В–Њ–є –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є–Њ–љ–љ–Њ–є –ї–Њ–≥–Є–Ї–Є –≤–≤–µ–і–µ–љ –Ї–≤–∞–ї–Є—Д–Є–Ї–∞—В–Њ—А volatile, –Ї–Њ—В–Њ—А–∞—П –≥–Њ–≤–Њ—А–Є—В –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А—Г, —З—В–Њ –љ–µ–Ї–∞—П ¬Ђ–≤–љ–µ—И–љ—П—П —Б–Є–ї–∞¬ї –Љ–Њ–ґ–µ—В –±—Л—В—М –Ј–∞–Є–љ—В–µ—А–µ—Б–Њ–≤–∞–љ–∞ (–Є –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В—М) –њ–∞—А–∞–ї–ї–µ–ї—М–љ—Л–є –і–Њ—Б—В—Г–њ (—З—В–µ–љ–Є–µ –Є–ї–Є –Є–Ј–Љ–µ–љ–µ–љ–Є–µ) –њ–µ—А–µ–Љ–µ–љ–љ–Њ–є вАФ —Н—В–Њ–є —Б–Є–ї–Њ–є –Љ–Њ–ґ–µ—В –±—Л—В—М –Ї–∞–Ї –њ–∞—А–∞–ї–ї–µ–ї—М–љ—Л–є –њ–Њ—В–Њ–Ї, —В–∞–Ї –Є –∞–њ–њ–∞—А–∞—В–љ–∞—П –ї–Њ–≥–Є–Ї–∞ —Ж–µ–ї–µ–≤–Њ–є —Б–Є—Б—В–µ–Љ—Л.
–Я–Њ—Н—В–Њ–Љ—Г, –љ–∞–њ—А–Є–Љ–µ—А, –≤ –Ј–∞–≥–Њ–ї–Њ–≤–Њ—З–љ—Л—Е —Д–∞–є–ї–∞—Е –≤—Б–µ –њ–Њ—А—В—Л –Є –Њ–±—К—П–≤–ї–µ–љ—Л —Б volatile, —З—В–Њ–±—Л –і–≤–µ –њ–Њ—Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ—Л—Е –њ–Њ–њ—Л—В–Ї–Є –Ј–∞–њ–Є—Б–Є —А–∞–Ј–љ—Л—Е —З–Є—Б–µ–ї –≤ –Њ–і–Є–љ –Є —В–Њ—В –ґ–µ –њ–Њ—А—В –љ–µ –±—Л–ї–Є –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞–љ—Л —Б –≤—Л–Ї–Є–і—Л–≤–∞–љ–Є–µ–Љ –≤—Б–µ—Е –њ—А–Њ–Љ–µ–ґ—Г—В–Њ—З–љ—Л—Е –Ј–∞–њ–Є—Б–µ–є –Є –Њ—Б—В–∞–≤–ї–µ–љ–Є–µ–Љ —В–Њ–ї—М–Ї–Њ –њ–Њ—Б–ї–µ–і–љ–µ–є.
–Ґ–µ–њ–µ—А—М –≤–µ—А–љ—С–Љ—Б—П –Ї –љ–∞—И–µ–є –Ј–∞–і–∞—З–µ. –Э–µ–Љ–љ–Њ–≥–Њ –њ–Њ–±–ї–Є–ґ–µ –Ї —А–µ–∞–ї—М–љ–Њ–Љ—Г –Љ–Є—А—Г.
–Ь–Њ–є CPU —А–∞–±–Њ—В–∞–µ—В –љ–∞ —В–∞–Ї—В–Њ–≤–Њ–є —З–∞—Б—В–Њ—В–µ 16 MHz. –≠—В–Њ –Њ–Ј–љ–∞—З–∞–µ—В 62.5 ns –љ–∞ –Њ–і–Є–љ —В–∞–Ї—В. –£ AVR –Њ–і–Є–љ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–љ—Л–є —Ж–Є–Ї–ї —Б–Њ–≤–µ—А—И–∞–µ—В—Б—П –Ј–∞ –Њ–і–Є–љ —В–∞–Ї—В (–≤ –Њ–±—Й–µ–Љ —Б–ї—Г—З–∞–µ —Н—В–Њ –љ–µ –≤—Б–µ–≥–і–∞ —В–∞–Ї). –С–Њ–ї—М—И–Є–љ—Б—В–≤–Њ –Є–љ—Б—В—А—Г–Ї—Ж–Є–є –≤—Л–њ–Њ–ї–љ—П–µ—В—Б—П –Ј–∞ 1 —Ж–Є–Ї–ї, –љ–µ–Ї–Њ—В–Њ—А—Л–µ вАФ –Ј–∞ 2.
–Т —З–∞—Б—В–љ–Њ—Б—В–Є, –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є out –Є in –≤—Л–њ–Њ–ї–љ—П—О—В—Б—П –Ј–∞ 1 —Ж–Є–Ї–ї.
–Ш —Г –љ–∞—Б –µ—Б—В—М –≤–Њ—В —В–∞–Ї–Њ–є –Є—Б—Е–Њ–і–љ—Л–є –Ї–Њ–і:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
ADDR_BUS = i;
dstbuf[i] = DATA_BUS;
–Ї–Њ—В–Њ—А—Л–є –њ—А–µ–≤—А–∞—Й–∞–µ—В—Б—П –≤:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
out PORTC, r25
in r24, PINB
–Ш–љ—Л–Љ–Є —Б–ї–Њ–≤–∞–Љ–Є, –Љ–µ–ґ–і—Г –≤—Л—Б—В–∞–≤–ї–µ–љ–Є–µ–Љ –∞–і—А–µ—Б–∞ –љ–∞ —И–Є–љ—Г –Є —Б—З–Є—В—Л–≤–∞–љ–Є–µ–Љ –і–∞–љ–љ—Л—Е —Б —И–Є–љ—Л –і–∞–љ–љ—Л—Е –њ—А–Њ—Е–Њ–і–Є—В –љ–µ –±–Њ–ї–µ–µ 62.5 ns.
–Ю–і–љ–∞–Ї–Њ, —А–µ–∞–ї—М–љ—Л–є –Љ–Є—А —В–∞–Ї–Њ–≤, —З—В–Њ —Г—Б—В—А–Њ–є—Б—В–≤–Њ (–Љ—Л –і–Њ–≥–Њ–≤–Њ—А–Є–ї–Є—Б—М –љ–∞–Ј—Л–≤–∞—В—М –µ–≥–Њ ¬Ђ–њ–∞–Љ—П—В—М¬ї), –Ї–Њ—В–Њ—А–Њ–µ –Љ—Л –Њ–њ—А–∞—И–Є–≤–∞–µ–Љ –Є–Љ–µ–µ—В –і—А—Г–≥–Є–µ –≤—А–µ–Љ–µ–љ–љ–Ђ–µ –Њ–≥—А–∞–љ–Є—З–µ–љ–Є—П. –° –Љ–Њ–Љ–µ–љ—В–∞ –≤—Л—Б—В–∞–≤–ї–µ–љ–Є—П –∞–і—А–µ—Б–∞ –љ–∞ —И–Є–љ—Г –і–Њ –Љ–Њ–Љ–µ–љ—В–∞ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –∞–і—А–µ—Б–∞ –њ—А–Њ—Е–Њ–і–Є—В 10 ns, –∞ —Б –Љ–Њ–Љ–µ–љ—В–∞ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –∞–і—А–µ—Б–∞ –і–Њ –≤—Л—Б—В–∞–≤–ї–µ–љ–Є—П –і–∞–љ–љ—Л—Е –љ–∞ —И–Є–љ—Г –і–∞–љ–љ—Л—Е вАФ 75 ns.
–Ш—В–Њ–≥–Њ –Њ—В –≤—Л—Б—В–∞–≤–ї–µ–љ–Є—П –∞–і—А–µ—Б–∞ –љ–∞ —И–Є–љ—Г –і–Њ –њ–Њ—П–≤–ї–µ–љ–Є—П –∞–Ї—В—Г–∞–ї—М–љ—Л—Е –і–∞–љ–љ—Л—Е –љ–∞ —И–Є–љ–µ –і–∞–љ–љ—Л—Е –і–Њ–ї–ґ–љ–Њ –њ—А–Њ–є—В–Є –Љ–Є–љ–Є–Љ—Г–Љ 85 ns. –Р —Г –љ–∞—Б –њ—А–Њ—Е–Њ–і–Є—В 62.5 ns.
–Э—Г–ґ–љ–∞ –Ј–∞–і–µ—А–ґ–Ї–∞.
–Ч–і–µ—Б—М-—В–Њ –Є –љ–∞—Б—В—Г–њ–∞–µ—В –Љ–Њ–Љ–µ–љ—В –Є—Б—В–Є–љ—Л.
–Ъ–∞–Ї –≤—Б—В–∞–≤–Є—В—М –≤ –Ї–Њ–і —В—А–µ–±—Г–µ–Љ—Г—О –Ј–∞–і–µ—А–ґ–Ї—Г?
–Э—Г–ґ–љ–Њ –µ—Й—С –Њ–і–љ–Њ –Њ—В—Б—В—Г–њ–ї–µ–љ–Є–µ:
- –Э–∞–і–µ—О—Б—М, –≤—Б–µ –Ј–љ–∞—О—В, —З—В–Њ —В–∞–Ї–Њ–µ intrinsic-–Є –≤ —В–µ—А–Љ–Є–љ–∞—Е –°/–°++. –Х—Б–ї–Є –Ї—В–Њ-—В–Њ –љ–µ –Ј–љ–∞–µ—В, –љ—Г–ґ–љ–Њ –њ–Њ—П—Б–љ–Є—В—М. –Т –°/–°++ –ї—О–±–∞—П —Б—Г—Й–љ–Њ—Б—В—М, –Њ–±—К—П–≤–ї–µ–љ–љ–∞—П, –љ–Њ –љ–µ –Њ–њ—А–µ–і–µ–ї—С–љ–љ–∞—П –≤ –њ—А–µ–і–µ–ї–∞—Е –Ї–Њ–Љ–њ–Є–ї–Є—А—Г–µ–Љ–Њ–≥–Њ —Д–∞–є–ї–∞ —Б—З–Є—В–∞–µ—В—Б—П –≤–љ–µ—И–љ–µ–є. –≠—В–Њ –Њ—В–љ–Њ—Б–Є—В—Б—П –Є –Ї —Д—Г–љ–Ї—Ж–Є—П–Љ –≤ –љ–µ –Љ–µ–љ—М—И–µ–є —Б—В–µ–њ–µ–љ–Є, –Ї —З–µ–Љ –Ї –њ–µ—А–µ–Љ–µ–љ–љ—Л–Љ. –°—Б—Л–ї–Ї–Є –љ–∞ –≤–љ–µ—И–љ–Є–µ —Д—Г–љ–Ї—Ж–Є–Є –Њ—Б—В–∞—О—В—Б—П –≤ —Б–Ї–Њ–Љ–њ–Є–ї–Є—А–Њ–≤–∞–љ–љ–Њ–Љ –Њ–±—К–µ–Ї—В–љ–Њ–Љ —Д–∞–є–ї–µ –Є –±—Г–і—Г—В –Ј–∞–Љ–µ–љ–µ–љ—Л –љ–∞ –Њ–±—А–∞—Й–µ–љ–Є—П –Ї –љ–∞—Б—В–Њ—П—Й–Є–Љ —Б—Г—Й–љ–Њ—Б—В—П–Љ —В–Њ–ї—М–Ї–Њ –љ–∞ —Н—В–∞–њ–µ –ї–Є–љ–Ї–Њ–≤–Ї–Є, –µ—Б–ї–Є –≤—Б–µ –Љ–µ–ґ–Љ–Њ–і—Г–ї—М–љ—Л–µ –Ј–∞–≤–Є—Б–Є–Љ–Њ—Б—В–Є –±—Г–і—Г—В —Г–і–Њ–≤–ї–µ—В–≤–Њ—А–µ–љ—Л. –Э–µ —Б—Г—Й–µ—Б—В–≤—Г–µ—В –љ–Є–Ї–∞–Ї–Њ–є —А–∞–Ј–љ–Є—Ж—Л –Љ–µ–ґ–і—Г PrivetVasya() –Є printf() вАФ —Б —В–Њ—З–Ї–Є –Ј—А–µ–љ–Є—П –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–∞ –Њ–±–µ –∞–±—Б–Њ–ї—О—В–љ–Њ —А–∞–≤–љ–Њ–Ј–љ–∞—З–љ—Л –Є –њ—А–Њ –Њ–±–µ –Љ–Њ–ґ–љ–Њ —Б–Ї–∞–Ј–∞—В—М ¬Ђ–і–∞ —Н—В–Њ –њ—А–Њ—Б—В–Њ –Ї–∞–Ї–Є–µ-—В–Њ –≤–љ–µ—И–љ–Є–µ —Д—Г–љ–Ї—Ж–Є–Є¬ї. –Ъ–Њ–≥–і–∞ –Є–і–Є–Њ—В—Б–Ї–Є–µ —Г—З–µ–±–љ–Є–Ї–Є –Є–ї–Є —Г—З–Є—В–µ–ї—П-–љ–µ–і–Њ—Г—З–Ї–Є –љ–∞—З–Є–љ–∞—О—В –≥–Њ–≤–Њ—А–Є—В—М ¬Ђ–≤—Б—В—А–Њ–µ–љ–љ–∞—П —Д—Г–љ–Ї—Ж–Є—П —П–Ј—Л–Ї–∞ printf()¬ї (–∞ —Н—В–Њ –Њ—З–µ–љ—М –њ–Њ–њ—Г–ї—П—А–љ—Л–є –±—А–µ–і) вАФ –љ–∞–і–Њ –њ–Њ–љ–Є–Љ–∞—В—М, —З—В–Њ —Н—В–Њ –њ—А–Њ—Б—В–Њ –≥–ї—Г–њ–Њ—Б—В—М, —З—В–Њ –≤ —П–Ј—Л–Ї –љ–Є—З–µ–≥–Њ —В–∞–Ї–Њ–≥–Њ –љ–µ –≤—Б—В—А–Њ–µ–љ–Њ, —З—В–Њ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –Њ–±—А–∞–±–∞—В—Л–≤–∞–µ—В –≤—Л–Ј–Њ–≤ –Ї printf() –љ–∞ —В–µ—Е –ґ–µ —Г—Б–ї–Њ–≤–Є—П—Е, —З—В–Њ –Є –≤—Л–Ј–Њ–≤ –Ї –ї—О–±–Њ–є –і—А—Г–≥–Њ–є —Д—Г–љ–Ї—Ж–Є–Є, –і–∞ —Е–Њ—В—М –≤ —Б–Њ—Б–µ–і–љ–µ–Љ —Д–∞–є–ї–µ —А–µ–∞–ї–Є–Ј–Њ–≤–∞–љ–љ–Њ–є. –І—В–Њ –Ї–∞—Б–∞–µ—В—Б—П —В–Њ–є –ґ–µ printf() вАФ —В–Њ —Н—В–Њ –љ–µ –≤—Б—В—А–Њ–µ–љ–љ–∞—П —Д—Г–љ–Ї—Ж–Є—П —П–Ј—Л–Ї–∞, –∞ —Д—Г–љ–Ї—Ж–Є—П —Б—В–∞–љ–і–∞—А—В–љ–Њ–є –±–Є–±–ї–Є–Њ—В–µ–Ї–Є —П–Ј—Л–Ї–∞. –°—В–∞–љ–і–∞—А—В –љ–∞ —П–Ј—Л–Ї —Н—В—Г —Д—Г–љ–Ї—Ж–Є—О –Њ–њ–Є—Б—Л–≤–∞–µ—В, –њ—А–Њ–≤–Њ–Ј–≥–ї–∞—И–∞–µ—В –µ—С –љ–∞–ї–Є—З–Є–µ –≤ —Б—В–∞–љ–і–∞—А—В–љ–Њ–є –±–Є–±–ї–Є–Њ—В–µ–Ї–µ, –љ–Њ —Б–∞–Љ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –Ї —Б—В–∞–љ–і–∞—А—В–љ–Њ–є –±–Є–±–ї–Є–Њ—В–µ–Ї–µ –Њ—В–љ–Њ—И–µ–љ–Є—П –љ–µ –Є–Љ–µ–µ—В вАФ –Њ–љ–∞ –Љ–Њ–ґ–µ—В –њ–Њ—П–≤–Є—В—М—Б—П –љ–∞ —Н—В–∞–њ–µ –ї–Є–љ–Ї–Њ–≤–Ї–Є, –∞ –Љ–Њ–ґ–µ—В –Є –≤–Њ–Њ–±—Й–µ –љ–µ –њ–Њ—П–≤–ї—П—В—М—Б—П. –Ґ–µ–Љ –љ–µ –Љ–µ–љ–µ–µ, –µ—Б—В—М –њ–Њ –Є—Б—В–Є–љ–µ –≤—Б—В—А–Њ–µ–љ–љ—Л–µ —Д—Г–љ–Ї—Ж–Є–Є, –і–ї—П –Ї–Њ—В–Њ—А—Л—Е –≤ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–µ –љ–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ —А–µ–∞–ї–Є–Ј–Њ–≤–∞–љ–∞ –Њ—Б–Њ–±–∞—П –Њ–±—А–∞–±–Њ—В–Ї–∞ вАФ –Њ–љ–Є –љ–∞–Ј—Л–≤–∞—О—В—Б—П intrinsic-–∞–Љ–Є. –£ —А–∞–Ј–љ—Л—Е –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–Њ–≤ –љ–∞–±–Њ—А intrinsic-–Њ–≤ —А–∞–Ј–љ—Л–є. Intrinsic-–Њ–Љ –Љ–Њ–ґ–µ—В –±—Л—В—М –Є —Д—Г–љ–Ї—Ж–Є—П, –Ї–Њ—В–Њ—А–∞—П —И—В–∞—В–љ–Њ –і–Њ–ї–ґ–љ–∞ –ґ–Є—В—М –≤ —Б—В–∞–љ–і–∞—А—В–љ–Њ–є –±–Є–±–ї–Є–Њ—В–µ–Ї–µ. –Я—А–Є –≤—Л–Ј–Њ–≤–µ intrinsic-—Д—Г–љ–Ї—Ж–Є–Є –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –≥–µ–љ–µ—А–Є—А—Г–µ—В –Њ—Б–Њ–±—Л–є –Ї–Њ–і, —Е–∞—А–∞–Ї—В–µ—А–љ—Л–є –Є–Љ–µ–љ–љ–Њ –і–ї—П –і–∞–љ–љ–Њ–є —Д—Г–љ–Ї—Ж–Є–Є: –љ–µ –≥–µ–љ–µ—А–Є—А—Г–µ—В—Б—П –љ–Є–Ї–∞–Ї–Њ–≥–Њ call-–∞, –љ–µ –±—Г–і–µ—В –љ–Є–Ї–∞–Ї–Њ–≥–Њ —А–µ–∞–ї—М–љ–Њ–≥–Њ –≤—Л–Ј–Њ–≤–∞ –Є –≤–Њ–Ј–≤—А–∞—В–∞, –∞ –±—Г–і–µ—В –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –Є–љ—Б—В—А—Г–Ї—Ж–Є–є, –≤—Л–њ–Њ–ї–љ—П—О—Й–Є—Е –љ—Г–ґ–љ—Г—О –Ј–∞–і–∞—З—Г. –Э–∞–њ—А–Є–Љ–µ—А –Њ—З–µ–љ—М —А–∞—Б–њ—А–Њ—Б—В—А–∞–љ—С–љ–љ—Л–є intrinsic memcpy() –Ї–Њ–Љ–њ–Є–ї–Є—А—Г–µ—В—Б—П –љ–µ –≤ –≤—Л–Ј–Њ–≤ –Ї–∞–Ї–Њ–є-—В–Њ —Д—Г–љ–Ї—Ж–Є–Є, –∞ –≤ –Є–љ—Б—В—А—Г–Ї—Ж–Є—О repnz movs (–њ—А–Є–Љ–µ—А –і–ї—П x86).
–Я–Њ–љ—П—В–љ–Њ–µ –і–µ–ї–Њ, —З—В–Њ –≤ —Б—В–∞–љ–і–∞—А—В–љ–Њ–є –±–Є–±–ї–Є–Њ—В–µ–Ї–µ –° (libc) –і–ї—П AVR –µ—Б—В—М –љ–µ–Ї–Њ—В–Њ—А—Л–µ —Д—Г–љ–Ї—Ж–Є–Є, –Ї–Њ—В–Њ—А—Л–µ –Њ–±–µ—Б–њ–µ—З–Є–≤–∞—О—В –Ј–∞–і–µ—А–ґ–Ї—Г. –Х—Б—В–µ—Б—В–≤–µ–љ–љ–Њ, —Н—В–Њ –њ–Њ–ї–љ–Њ–≤–µ—Б–љ—Л–µ —Д—Г–љ–Ї—Ж–Є–Є, –Ї–Њ—В–Њ—А—Л–µ –≤–љ—Г—В—А–Є –Ї—А—Г—В—П—В —Ж–Є–Ї–ї. –Ь–љ–µ –љ—Г–ґ–љ–∞ –Ј–∞–і–µ—А–ґ–Ї–∞ –≤ 1вАФ2 —В–∞–Ї—В–∞, –Є –µ—Б—В–µ—Б—В–≤–µ–љ–љ–Њ, —З—В–Њ –і–ї—П –Љ–µ–љ—П —В–∞–Ї–Є–µ —В—П–ґ–µ–ї–Њ–≤–µ—Б–љ—Л–µ —Д—Г–љ–Ї—Ж–Є–Є –љ–µ –њ–Њ–і—Е–Њ–і—П—В. –°–і–µ–ї–∞—В—М –Ј–∞–і–µ—А–ґ–Ї—Г –≤ 1 —В–∞–Ї—В –њ–Њ–ї–љ–Њ—Ж–µ–љ–љ–Њ–є (–Є –Њ–±—Л–Ї–љ–Њ–≤–µ–љ–љ–Њ–є) —Д—Г–љ–Ї—Ж–Є–µ–є –љ–µ–ї—М–Ј—П: –і–∞–ґ–µ –µ—Б–ї–Є —Н—В–Њ –±—Г–і–µ—В —Б–Њ–≤–µ—А—И–µ–љ–љ–Њ –њ—Г—Б—В–∞—П —Д—Г–љ–Ї—Ж–Є—П, –Є–љ—Б—В—А—Г–Ї—Ж–Є—П call –≤—Л–њ–Њ–ї–љ—П–µ—В—Б—П –Ј–∞ 4 —В–∞–Ї—В–∞, –Є –Є–љ—Б—В—А—Г–Ї—Ж–Є—П ret вАФ –µ—Й—С 4 —В–∞–Ї—В–∞, –Є—В–Њ–≥–Њ 8 —В–∞–Ї—В–Њ–≤ –љ–∞ –≤—Л–Ј–Њ–≤ –њ—Г—Б—В–Њ–є —Д—Г–љ–Ї—Ж–Є–Є.
–С–µ–Ј –Љ–∞–ї–µ–є—И–µ–є –ї–Є—И–љ–µ–є –Љ—Л—Б–ї–Є –њ–Њ–љ—П—В–љ–Њ, —З—В–Њ –Ј–∞–і–µ—А–ґ–Ї–Є –≤ –µ–і–Є–љ–Є—Ж—Л —В–∞–Ї—В–Њ–≤ (–Љ–µ–љ—М—И–µ 8) –Љ–Њ–≥—Г—В –±—Л—В—М —А–µ–∞–ї–Є–Ј–Њ–≤–∞–љ—Л —В–Њ–ї—М–Ї–Њ intrinsic-–∞–Љ–Є. –Ш —В–µ–њ–µ—А—М, —Б–Ї—А–µ—Б—В–Є–≤ –њ–∞–ї—М—Ж—Л, —Б–њ—А–Њ—Б–Є–Љ: –∞ –µ—Б—В—М –ї–Є –≤ avr-gcc delay-—Д—Г–љ–Ї—Ж–Є–Є (—Д—Г–љ–Ї—Ж–Є–Є –Ј–∞–і–µ—А–ґ–Ї–Є), –≤—Л–њ–Њ–ї–љ–µ–љ–љ—Л–µ –Ї–∞–Ї intrinsic-–Є?
–Ъ —Б—З–∞—Б—В—М—О, –њ–Њ–Ї–∞ –≤—Б—С —Е–Њ—А–Њ—И–Њ, –і–µ–є—Б—В–≤–Є—В–µ–ї—М–љ–Њ –µ—Б—В—М —В–∞–Ї–Њ–є intrinsic вАФ —Д—Г–љ–Ї—Ж–Є—П –љ–∞–Ј—Л–≤–∞–µ—В—Б—П __builtin_avr_delay_cycles().
–Э–∞ –њ–µ—А–≤—Л–є –≤–Ј–≥–ї—П–і, –µ—Б–ї–Є –Љ–µ–ґ–і—Г –≤—Л—Б—В–∞–≤–ї–µ–љ–Є–µ–Љ –∞–і—А–µ—Б–∞ –љ–∞ —И–Є–љ—Г –∞–і—А–µ—Б–∞ –Є —Б—З–Є—В—Л–≤–∞–љ–Є–µ–Љ –±–∞–є—В–∞ —Б —И–Є–љ—Л –і–∞–љ–љ—Л—Е –≤–Ї–ї–Є–љ–Є—В—М –Њ–і–љ—Г –ї–Є—И–љ—О—О –Є–љ—Б—В—А—Г–Ї—Ж–Є—О, —В–Њ —Б —Г—З—С—В–Њ–Љ –њ–µ—А–≤–Њ–є –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є –њ—А–Њ–є–і—С—В 2 √Ч 62.5ns = 125ns, —З—В–Њ –±–Њ–ї—М—И–µ 85 ns.
–Ґ–Њ –µ—Б—В—М –Љ—Л –Љ–Њ–≥–ї–Є –±—Л —Б–і–µ–ї–∞—В—М —В–∞–Ї:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
void DoRead(uint8_t *dstbuf)
{
uint8_t i;
for(i = 0; i < 128; i++)
{
ADDR_BUS = i;
__builtin_avr_delay_cycles(1);
dstbuf[i] = DATA_BUS;
}
}
–Т–Њ —З—В–Њ –±—Л —Н—В–Њ –Љ–Њ–≥–ї–Њ –±—Л —Б–Ї–Њ–Љ–њ–Є–ї–Є—А–Њ–≤–∞—В—М—Б—П?
–ѓ –љ–µ –Ј—А—П –њ–Є—Б–∞–ї –≤—Л—И–µ –њ—А–Њ –њ–µ—А–µ—Б—В–∞–љ–Њ–≤–Ї—Г –Є–љ—Б—В—А—Г–Ї—Ж–Є–є. –Я–Њ—Б–Ї–Њ–ї—М–Ї—Г __builtin_avr_delay_cycles вАФ —Н—В–Њ intrinsic, —В–Њ –µ—Б—В—М –Ї–Њ–і–Њ–≥–µ–љ–µ—А–∞—Ж–Є—П –≤—Л–Ј–Њ–≤–∞ —Н—В–Њ–є —Д—Г–љ–Ї—Ж–Є–Є –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –≤ —Б–∞–Љ–Њ–Љ —Б–µ—А–і—Ж–µ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–∞, –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –Є–Љ–µ–µ—В –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –і–ї—П —Б–Њ–Ј–і–∞–љ–Є—П –Ј–∞–і–µ—А–ґ–Ї–Є –Є–Љ–µ–љ–љ–Њ –≤ —Н—В–Њ–Љ –Љ–µ—Б—В–µ –њ–µ—А–µ–љ–µ—Б—В–Є —Б—О–і–∞ –Ї–∞–Ї—Г—О-–љ–Є–±—Г–і—М –Є–љ—Б—В—А—Г–Ї—Ж–Є—О (–Ј–∞–љ–Є–Љ–∞—О—Й—Г—О 1 —В–∞–Ї—В), –љ–µ –љ–∞—А—Г—И–∞—П –Ј–∞–≤–Є—Б–Є–Љ–Њ—Б—В–µ–є –њ–Њ ¬Ђ–њ–Њ–±–Њ—З–љ—Л–Љ —Н—Д—Д–µ–Ї—В–∞–Љ¬ї.
–Ш —П –љ–µ –Ј—А—П –њ—А–Њ—Б–Є–ї –Њ–±—А–∞—В–Є—В—М –≤–љ–Є–Љ–∞–љ–Є–µ, —З—В–Њ —А–µ–≥–Є—Б—В—А R25 –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П —В–Њ–ї—М–Ї–Њ –і–ї—П –≤—Л—Б—В–∞–≤–ї–µ–љ–Є—П –∞–і—А–µ—Б–∞ (–Є –љ–µ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –і–ї—П –і–Њ—Б—В—Г–њ–∞ –Ї –±—Г—Д–µ—А—Г, –љ–µ—Б–Љ–Њ—В—А—П –љ–∞ –Є—Б—Е–Њ–і–љ—Л–є —Б–Є—И–љ—Л–є –Ї–Њ–і). –Я–Њ—Н—В–Њ–Љ—Г –Є–љ—Б—В—А—Г–Ї—Ж–Є—О, –Є–љ–Ї—А–µ–Љ–µ–љ—В–Є—А—Г—О—Й—Г—О R25, –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –Љ–Њ–ґ–µ—В —Б–≤–Њ–±–Њ–і–љ–Њ –њ–Њ–і—Л–Љ–∞—В—М –≤—Л—И–µ –≤–њ–ї–Њ—В—М –і–Њ —В–Њ–≥–Њ –Љ–µ—Б—В–∞, –≥–і–µ –љ–∞–Љ –љ—Г–ґ–љ–∞ –Њ–і–љ–Њ—В–∞–Ї—В–љ–∞—П –Ј–∞–і–µ—А–ґ–Ї–∞, —В–∞–Ї –Ї–∞–Ї —В–∞–Ї–Њ–є –њ–µ—А–µ–љ–Њ—Б –љ–Є–Ї–∞–Ї –љ–µ –≤–ї–Є—П–µ—В –љ–∞ –ї–Њ–≥–Є–Ї—Г –Ї–Њ–і–∞, –љ–Њ –Ј–∞—В–Њ –Њ–±–µ—Б–њ–µ—З–Є–≤–∞–µ—В –ґ–µ–ї–∞–µ–Љ—Г—О –Ј–∞–і–µ—А–ґ–Ї—Г –≤ –љ—Г–ґ–љ–Њ–Љ –Љ–µ—Б—В–µ:
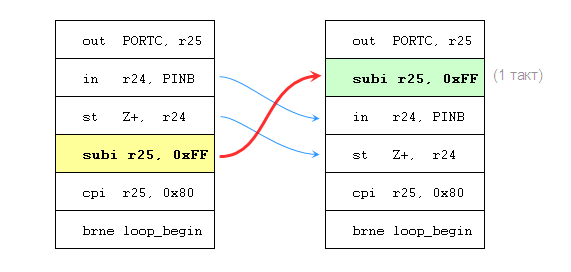
–Т—Л–≥–ї—П–і–Є—В –Ј–∞–Љ–µ—З–∞—В–µ–ї—М–љ–Њ: –≤ —Ж–Є–Ї–ї–µ –Ї–∞–Ї –±—Л–ї–Њ, —В–∞–Ї –Є –Њ—Б—В–∞–ї–Њ—Б—М 6 –Є–љ—Б—В—А—Г–Ї—Ж–Є–є, –Њ–±—Й–µ–µ –≤—А–µ–Љ—П –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Њ–і–љ–Њ–є –Є—В–µ—А–∞—Ж–Є–Є (–ї—О–±–Њ–є –Ї—А–Њ–Љ–µ –њ–Њ—Б–ї–µ–і–љ–µ–є) вАФ 8 —В–∞–Ї—В–Њ–≤, –∞ –≤ –љ—Г–ґ–љ–Њ–Љ –љ–∞–Љ –Љ–µ—Б—В–µ –≤–Њ–Ј–љ–Є–Ї–ї–∞ –Ј–∞–і–µ—А–ґ–Ї–∞ –≤ 1 —В–∞–Ї—В.
–Э–Њ –µ—Б–ї–Є –≤–љ–Є–Љ–∞—В–µ–ї—М–љ–Њ –њ–Њ—Б–Љ–Њ—В—А–µ—В—М —В—Г —З–∞—Б—В—М –і–∞—В–∞—И–Є—В–∞, –Ї–Њ—В–Њ—А–∞—П –Њ–њ–Є—Б—Л–≤–∞–µ—В —З—В–µ–љ–Є–µ –і–∞–љ–љ—Л—Е —Б –њ–Њ—А—В–∞, —В–∞–Љ –Љ–Њ–ґ–љ–Њ –Њ–±–љ–∞—А—Г–ґ–Є—В—М —Б–ї–µ–і—Г—О—Й–µ–µ:

–≠—В–∞ –≤—А–µ–Љ–µ–љ–љ–∞—П –і–Є–∞–≥—А–∞–Љ–Љ–∞ –≥–Њ–≤–Њ—А–Є—В –љ–∞–Љ, —З—В–Њ –Є–љ—Б—В—А—Г–Ї—Ж–Є—П in r17, PINx –њ—А–Њ—З–Є—В–∞–µ—В —Б –њ–Њ—А—В–∞ –Ј–љ–∞—З–µ–љ–Є–µ, –Ї–Њ—В–Њ—А–Њ–µ –±—Г–і–µ—В –Ј–∞—Й—С–ї–Ї–љ—Г—В–Њ –љ–∞ —Б–µ—А–µ–і–Є–љ–µ –њ—А–µ–і—Л–і—Г—Й–µ–≥–Њ —Ж–Є–Ї–ї–∞. –Ъ–∞–ґ–і—Л–є –љ–Њ–≤—Л–є –њ—А–Њ—Ж–µ—Б—Б–Њ—А–љ—Л–є —Ж–Є–Ї–ї –љ–∞—З–Є–љ–∞–µ—В—Б—П –њ–Њ –≤–Њ—Б—Е–Њ–і—П—Й–µ–Љ—Г —Д—А–Њ–љ—В—Г —В–∞–Ї—В–Є—А—Г—О—Й–µ–≥–Њ —Б–Є–≥–љ–∞–ї–∞, —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–µ–љ–љ–Њ –њ–∞–і–∞—О—Й–Є–є —Д—А–Њ–љ—В –њ—А–Є—Е–Њ–і–Є—В—Б—П –љ–∞ —Б–µ—А–µ–і–Є–љ—Г —Ж–Є–Ї–ї–∞. –Т –љ–∞—З–∞–ї–µ —Ж–Є–Ї–ї–∞ (–њ–Њ –≤–Њ—Б—Е–Њ–і—П—Й–µ–Љ—Г —Д—А–Њ–љ—В—Г) –Ј–∞—Й—С–ї–Ї–∞ —Б—В–∞–љ–Њ–≤–Є—В—Б—П –њ—А–Њ–Ј—А–∞—З–љ–Њ–є –Є –Њ—Б—В–∞—С—В—Б—П —В–∞–Ї–Њ–є –і–Њ —Б–њ–∞–і–∞—О—Й–µ–≥–Њ —Д—А–Њ–љ—В–∞ (–Ј–∞—И—В—А–Є—Е–Њ–≤–∞–љ–љ–∞—П –Њ–±–ї–∞—Б—В—М –љ–∞ –і–Є–∞–≥—А–∞–Љ–Љ–µ). –Я–Њ —Б–њ–∞–і–∞—О—Й–µ–Љ—Г —Д—А–Њ–љ—В—Г –Ј–∞—Й—С–ї–Ї–∞ –Ј–∞—Й—С–ї–Ї–Є–≤–∞–µ—В—Б—П –Є —Б—З–Є—В–∞–љ–љ–Њ–µ —Б –≤–љ–µ—И–љ–Є—Е –њ–Є–љ–Њ–≤ –Ј–љ–∞—З–µ–љ–Є–µ –Њ—Б—В–∞—С—В—Б—П –љ–µ–Є–Ј–Љ–µ–љ–љ—Л–Љ –≤ —Б–∞–Љ–Њ–є –Ј–∞—И—С–ї–Ї–µ, –∞ –њ—А–Є —Б–ї–µ–і—Г—О—Й–µ–Љ –ґ–µ –≤–Њ—Б—Е–Њ–і—П—Й–µ–Љ —Д—А–Њ–љ—В–µ —Н—В–Њ —Б—З–Є—В–∞–љ–љ–Њ–µ –Ј–љ–∞—З–µ–љ–Є–µ —Б–і–≤–Є–≥–∞–µ—В—Б—П –≤ PINx.
–≠—В–Њ –Њ–Ј–љ–∞—З–∞–µ—В, —З—В–Њ –Њ–і–љ–Њ—В–∞–Ї—В–љ–Њ–є –Ј–∞–і–µ—А–ґ–Ї–Є –Љ–µ–ґ–і—Г –≤—Л—Б—В–∞–≤–ї–µ–љ–Є–µ–Љ –∞–і—А–µ—Б–∞ –Є —Б—З–Є—В—Л–≤–∞–љ–Є–µ–Љ –і–∞–љ–љ—Л—Е –Љ–∞–ї–Њ, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –≤ —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ –±—Г–і–µ—В —Б—З–Є—В–∞–љ–Њ —В–Њ —Б–Њ—Б—В–Њ—П–љ–Є–µ —И–Є–љ—Л –і–∞–љ–љ—Л—Е, –≤ –Ї–Њ—В–Њ—А–Њ–Љ –Њ–љ–∞ –±—Л–ї–∞ –љ–∞ —Б–µ—А–µ–і–Є–љ–µ –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Ј–∞–і–µ—А–ґ–Є–≤–∞—О—Й–µ–є –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є, –∞ –≤ —Н—В–Њ—В –Љ–Њ–Љ–µ–љ—В –≤—А–µ–Љ–µ–љ–Є —Б –Љ–Њ–Љ–µ–љ—В–∞ –≤—Л—Б—В–∞–≤–ї–µ–љ–Є—П –∞–і—А–µ—Б–∞ –љ–∞ —И–Є–љ—Г –њ—А–Њ—И–ї–Њ —В–Њ–ї—М–Ї–Њ –њ–Њ–ї—Ж–Є–Ї–ї–∞ (–њ–Њ–ї—В–∞–Ї—В–∞). –Я–Њ—Н—В–Њ–Љ—Г –љ—Г–ґ–љ–∞ –Ј–∞–і–µ—А–ґ–Ї–∞ –≤ –і–≤–∞ —В–∞–Ї—В–∞, –Є–±–Њ –≤ —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ —Б –Љ–Њ–Љ–µ–љ—В–∞ –≤—Л—Б—В–∞–≤–ї–µ–љ–Є—П –∞–і—А–µ—Б–∞ –і–Њ —А–µ–∞–ї—М–љ–Њ–≥–Њ –Љ–Њ–Љ–µ–љ—В–∞ –Ј–∞—Й—С–ї–Ї–Є–≤–∞–љ–Є—П —Б–Њ—Б—В–Њ—П–љ–Є—П —И–Є–љ—Л –і–∞–љ–љ—Л—Е –±—Г–і–µ—В –њ—А–Њ—Е–Њ–і–Є—В—М —Г–ґ–µ –њ–Њ–ї—В–Њ—А–∞ —Ж–Є–Ї–ї–∞.
–Х—Б—В–µ—Б—В–≤–µ–љ–љ–Њ, –і–ї—П –Љ–µ–љ—П —Н—В–Њ –љ–µ —Б—О—А–њ—А–Є–Ј: —П —Б–њ–µ—Ж–Є–∞–ї—М–љ–Њ –Є–Ј–љ–∞—З–∞–ї—М–љ–Њ –љ–∞–њ–Є—Б–∞–ї ¬Ђ–Э–∞ –њ–µ—А–≤—Л–є –≤–Ј–≥–ї—П–і¬ї.
–Э—Г –Њ–Ї–µ–є, —В–Њ–≥–і–∞ —В–∞–Ї:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
void DoRead(uint8_t *dstbuf)
{
uint8_t i;
for(i = 0; i < 128; i++)
{
ADDR_BUS = i;
__builtin_avr_delay_cycles(2);
dstbuf[i] = DATA_BUS;
}
}
–Т–Њ —З—В–Њ –±—Л —Н—В–Њ –Љ–Њ–≥–ї–Њ —Б–Ї–Њ–Љ–њ–Є–ї–Є—А–Њ–≤–∞—В—М—Б—П?
–Ю–њ—П—В—М –ґ–µ, —Б–Њ–Ј–і–∞—В—М –≤ –Ї–Њ–і–µ –Ј–∞–і–µ—А–ґ–Ї—Г –љ–∞ –і–≤–∞ —Ж–Є–Ї–ї–∞ (—В–∞–Ї—В–∞) –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –≤–њ–Њ–ї–љ–µ –Љ–Њ–ґ–µ—В –њ–µ—А–µ–Љ–µ—Й–µ–љ–Є–µ–Љ –Є–љ—Б—В—А—Г–Ї—Ж–Є–є. –Т –њ—А–Њ—И–ї—Л–є —А–∞–Ј –Љ—Л –і–≤–Є–≥–∞–ї–Є –Є–љ–Ї—А–µ–Љ–µ–љ—В–Є—А—Г—О—Й—Г—О –Є–љ—Б—В—А—Г–Ї—Ж–Є—О, –љ–Њ –љ–Є—З–µ–≥–Њ –љ–µ –Љ–µ—И–∞–µ—В –љ–∞–Љ –њ–µ—А–µ–і–≤–Є–љ—Г—В—М –Є —Б—А–∞–≤–љ–Є–≤–∞—О—Й—Г—О –Є–љ—Б—В—А—Г–Ї—Ж–Є—О (cpi R25, 0x80):

–Т–Њ—В —Г –љ–∞—Б –µ—Б—В—М —Г–ґ–µ 2 —В–∞–Ї—В–∞ –Ј–∞–і–µ—А–ґ–Ї–Є –Љ–µ–ґ–і—Г out –Є in, –∞ –≤ —Ж–Є–Ї–ї–µ –њ–Њ –њ—А–µ–ґ–љ–µ–Љ—Г 6 –Є–љ—Б—В—А—Г–Ї—Ж–Є–є, –≤—Л–њ–Њ–ї–љ–µ–љ–Є–µ –Ї–Њ—В–Њ—А—Л—Е –Ј–∞–љ–Є–Љ–∞–µ—В 8 –њ—А–Њ—Ж–µ—Б—Б–Њ—А–љ—Л—Е —Ж–Є–Ї–ї–Њ–≤ (–і–ї—П –≤—Б–µ—Е –Є—В–µ—А–∞—Ж–Є–є, –Ї—А–Њ–Љ–µ –њ–Њ—Б–ї–µ–і–љ–µ–є, –Є–±–Њ –Њ–љ–∞ –Ј–∞–є–Љ—С—В 7 —В–∞–Ї—В–Њ–≤ вАФ –љ–µ –≤—Л–њ–Њ–ї–љ–Є–≤—И–µ–µ—Б—П –≤–µ—В–≤–ї–µ–љ–Є–µ –±–µ—А—С—В 1 —Ж–Є–Ї–ї, –≤–Љ–µ—Б—В–Њ –і–≤—Г—Е).
–Ґ–∞–Ї–∞—П –њ–µ—А–µ—Б—В–∞–љ–Њ–≤–Ї–∞ –≤–Њ–Ј–Љ–Њ–ґ–љ–∞, —В–∞–Ї –Ї–∞–Ї –Њ–љ–∞ –љ–µ –љ–∞—А—Г—И–∞–µ—В –ї–Њ–≥–Є–Ї–Є —А–∞–±–Њ—В—Л –Ї–Њ–і–∞: –Є–љ—Б—В—А—Г–Ї—Ж–Є—П —Б—А–∞–≤–љ–µ–љ–Є—П –љ–µ –Њ–±—П–Ј–∞–љ–∞ –Є–і—В–Є –≤–њ–ї–Њ—В–љ—Г—О –Ї –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є –≤–µ—В–≤–ї–µ–љ–Є—П, –∞ –њ—А–Њ—Б—В–Њ –Ї–∞–Ї –Є –≤ –±–Њ–ї—М—И–Є–љ—Б—В–≤–µ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–љ—Л—Е –∞—А—Е–Є—В–µ–Ї—В—Г—А, –Є–љ—Б—В—А—Г–Ї—Ж–Є—П —Б—А–∞–≤–љ–µ–љ–Є—П –≤—Л—Б—В–∞–≤–ї—П–µ—В —Д–ї–∞–≥–Є –≤ —Б—В–∞—В—Г—Б–љ–Њ–Љ —А–µ–≥–Є—Б—В—А–µ, –∞ –Є–љ—Б—В—А—Г–Ї—Ж–Є—П —Г—Б–ї–Њ–≤–љ–Њ–≥–Њ –њ–µ—А–µ—Е–Њ–і–∞ –њ—А–Њ–≤–µ—А—П–µ—В —Н—В–Є —Д–ї–∞–≥–Є. –Я–Њ—Б–Ї–Њ–ї—М–Ї—Г –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є in –Є st –≤–Њ–Њ–±—Й–µ –љ–Є–Ї–∞–Ї –љ–µ —В—А–Њ–≥–∞—О—В —Д–ї–∞–≥–Є, –Є—Е –Љ–Њ–ґ–љ–Њ —Б—В–∞–≤–Є—В—М –Љ–µ–ґ–і—Г cpi –Є brne.
–Ю—Е –Є –ї—О–±–ї—О –ґ–µ —П —В—П–љ—Г—В—М...
–Р —В–µ–њ–µ—А—М —Б–∞–Љ–Њ–µ –≥–ї–∞–≤–љ–Њ–µ.
–Т–Њ —З—В–Њ —Н—В–Њ —А–µ–∞–ї—М–љ–Њ —Б–Ї–Њ–Љ–њ–Є–ї–Є—А—Г–µ—В—Б—П?
–ѓ –і–∞–ґ–µ –љ–µ –±—Г–і—Г –њ–Њ–Ї–∞–Ј—Л–≤–∞—В—М –Ї–Њ–і, –∞ –њ—А–Њ—Б—В–Њ —Б–Ї–∞–ґ—Г, —З—В–Њ –≤ —Б–ї—Г—З–∞–µ __builtin_avr_delay_cycles(1); –Љ–µ–ґ–і—Г out –Є in –≤—Б—В–∞–≤–ї—П–µ—В—Б—П –Њ–і–љ–∞ –Є–љ—Б—В—А—Г–Ї—Ж–Є—П nop, –∞ –≤ —Б–ї—Г—З–∞–µ —Б __builtin_avr_delay_cycles(2); –≤—Б—В–∞–≤–ї—П–µ—В—Б—П –Є–љ—Б—В—А—Г–Ї—Ж–Є—П rjmp .+0, –Ї–Њ—В–Њ—А–∞—П –њ–Њ —Б—Г—В–Є –≤—Л–њ–Њ–ї–љ—П–µ—В –њ—А—Л–ґ–Њ–Ї –љ–∞ —Б–ї–µ–і—Г—О—Й—Г—О –њ—А—П–Љ–Њ –Ј–∞ –љ–µ–є –Є–љ—Б—В—А—Г–Ї—Ж–Є—О (—Б–ґ–Є—А–∞—П 2 –њ—А–Њ—Ж–µ—Б—Б–Њ—А–љ—Л—Е —Ж–Є–Ї–ї–∞, –Ї–∞–Ї –Є —В—А–µ–±—Г–µ—В—Б—П).
–Ш–љ—Л–Љ–Є —Б–ї–Њ–≤–∞–Љ–Є, –љ–Є–Ї–∞–Ї–Њ–є –њ–µ—А–µ—Б—В–∞–љ–Њ–≤–Ї–Є –Є–љ—Б—В—А—Г–Ї—Ж–Є–є –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –љ–µ –і–µ–ї–∞–µ—В, —Е–Њ—В—П, –µ—Б—В–µ—Б—В–≤–µ–љ–љ–Њ, –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є—П –≤–Ї–ї—О—З–µ–љ–∞, –Є —Н—В–Њ –њ—А–Є —В–Њ–Љ, —З—В–Њ —Г –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–∞ –±—Л–ї–∞ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М —Б–Њ–Ј–і–∞—В—М –Ј–∞–і–µ—А–ґ–Ї–Є –≤ —В—А–µ–±—Г–µ–Љ—Л—Е –њ—А–Њ–≥—А–∞–Љ–Љ–Є—Б—В–Њ–Љ –Љ–µ—Б—В–∞—Е, –љ–µ —Г–≤–µ–ї–Є—З–Є–≤–∞—П –њ—А–Є —Н—В–Њ–Љ –Њ–±—Й–µ–µ –≤—А–µ–Љ—П –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Њ–і–љ–Њ–є –Є—В–µ—А–∞—Ж–Є–Є —Ж–Є–Ї–ї–∞.
–Ч–∞–љ–∞–≤–µ—Б...
–Ґ–∞–Ї—В—Л вАФ –љ–∞ –≤–µ—Б –Ј–Њ–ї–Њ—В–∞
–Т —Б–Њ–≤—А–µ–Љ–µ–љ–љ–Њ–Љ –Љ–Є—А–µ, –≥–і–µ –і–µ—Б–Ї—В–Њ–њ–љ—Л–µ –Є –Љ–Њ–±–Є–ї—М–љ—Л–µ –њ—А–Њ—Ж–µ—Б—Б–Њ—А—Л (–Љ–Њ–ї—З—Г –њ—А–Њ —Б–µ—А–≤–µ—А–љ—Л–µ) –Љ–Њ–≥—Г—В –Є–Љ–µ—В—М –±–Њ–ї—М—И–µ –і–µ—Б—П—В–Ї–∞ —П–і–µ—А, –∞ —В–∞–Ї—В–Њ–≤—Л–µ —З–∞—Б—В–Њ—В—Л –њ—А–µ–≤—Л—И–∞—О—В 1 –У–У—Ж, –Є –њ–Њ—Н—В–Њ–Љ—Г —Б–Њ—Д—В –Љ–Њ–ґ–µ—В –≤—Л–њ–Њ–ї–љ—П—В—М –Љ–Є–ї–ї–Є–Њ–љ—Л –ї–Є—И–љ–Є—Е –Є–љ—Б—В—А—Г–Ї—Ж–Є–є –њ—А–Њ—Б—В–Њ –њ–Њ—В–Њ–Љ—Г, —З—В–Њ –њ—А–Њ–≥—А–∞–Љ–Љ–Є—Б—В—Г –љ–µ —Е–Њ—В–µ–ї–Њ—Б—М –њ–Њ–і–љ–∞–њ—А—П—З—М –Љ–Њ–Ј–≥–Є –Є –њ–Њ—В–Њ–Љ—Г —З—В–Њ —З–Є—Б–ї–∞ —Е—А–∞–љ—П—В –≤ —Б—В—А–Њ–Ї–∞—Е, –Љ–љ–Њ–≥–Є–Љ –Љ–Њ–ґ–µ—В –њ–Њ–Ї–∞–Ј–∞—В—М—Б—П, —З—В–Њ –Њ–і–љ–∞ –ї–Є—И–љ—П—П –Є–љ—Б—В—А—Г–Ї—Ж–Є—П вАФ —Н—В–Њ –љ–Є—З—В–Њ–ґ–љ–∞—П –Љ–µ–ї–Њ—З—М.
–Т –Љ–Є—А–µ —Н–ї–µ–Ї—В—А–Њ–љ–Є–Ї–Є, –≥–і–µ —Б–Є—Б—В–µ–Љ—Л –Љ–Њ–ґ–љ–Њ –Њ—В–љ–µ—Б—В–Є –Ї —Б–Є—Б—В–µ–Љ–∞–Љ —А–µ–∞–ї—М–љ–Њ–≥–Њ –≤—А–µ–Љ–µ–љ–Є, –∞ —В–∞–Ї—В–Њ–≤—Л–µ —З–∞—Б—В–Њ—В—Л –љ–µ —В–∞–Ї–Є–µ –±–Њ–ї—М—И–Є–µ (–≤–Њ –Є–Љ—П –і–µ—И–µ–≤–Є–Ј–љ—Л —З–Є–њ–Њ–≤), —В–∞–Ї—В—Л –Љ–Њ–≥—Г—В –±—Л—В—М –љ–∞ –≤–µ—Б –Ј–Њ–ї–Њ—В–∞.
–Х—Б–ї–Є –њ–Њ–і—Г–Љ–∞—В—М, —З—В–Њ –Њ–і–Є–љ –Є —В–Њ—В –ґ–µ –Ї—Г—Б–Њ—З–µ–Ї –Ї–Њ–і–∞ –Љ–Њ–ґ–µ—В –≤—Л–њ–Њ–ї–љ—П—В—М—Б—П 10 –Љ–ї–љ —А–∞–Ј, –ї–µ–≥–Ї–Њ –њ—А–Є–Ї–Є–љ—Г—В—М, —Б–Ї–Њ–ї—М–Ї–Њ –≤—А–µ–Љ–µ–љ–Є —Б–Њ–ґ—А—Г—В –ї–Є—И–љ–Є–µ –і–≤–∞ —В–∞–Ї—В–∞. –Т –љ–∞—И–µ–Љ —Б–ї—Г—З–∞–µ (–і–ї—П –љ–∞—И–µ–≥–Њ —Ж–Є–Ї–ї–∞) –ї–Є—И–љ–Є–µ –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є —Г–≤–µ–ї–Є—З–Є–≤–∞—О—В –≤—А–µ–Љ—П –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Њ–і–љ–Њ–є –Є—В–µ—А–∞—Ж–Є–Є –љ–∞ 25%! –Ґ–Њ –µ—Б—В—М —В–Њ, —З—В–Њ –Љ–Њ–≥–ї–Њ –≤—Л–њ–Њ–ї–љ–Є—В—М—Б—П –Ј–∞ –Љ–Є–љ—Г—В—Г, –±—Г–і–µ—В –≤—Л–њ–Њ–ї–љ—П—В—М—Б—П –Ј–∞ 75 —Б–µ–Ї—Г–љ–і. –Ш —Н—В–Њ –±–µ–Ј–і–∞—А–љ—Л–µ 25 –њ—А–Њ—Ж–µ–љ—В–Њ–≤, –љ–Є–Ї–Њ–Љ—Г –љ–µ –љ—Г–ґ–љ—Л–µ, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –Є–Ј–±–µ–ґ–∞—В—М –Є—Е –±—Л–ї–Њ –ї–µ–≥—З–µ –ї—С–≥–Ї–Њ–≥–Њ.
–Я–Њ–Љ–Є–Љ–Њ ¬Ђ–≤–Љ–µ—Б—В–Њ 60 —Б–µ–Ї—Г–љ–і –Њ–љ–Њ –Ј–∞–є–Љ—С—В 75¬ї (—З—В–Њ –≤ —А–µ–∞–ї—М–љ–Њ—Б—В–Є –Љ–Њ–ґ–µ—В –Њ–Ї–∞–Ј–∞—В—М—Б—П –љ–∞–Љ–љ–Њ–≥–Њ —Е—Г–ґ–µ, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –Љ—Л —А–∞—Б—Б–Љ–∞—В—А–Є–≤–∞–ї–Є –љ–∞–Є–њ—А–Њ—Б—В–µ–є—И–Є–є —Ж–Є–Ї–ї –Є –Њ–і–љ—Г –µ–і–Є–љ—Б—В–≤–µ–љ–љ—Г—О –Ј–∞–і–µ—А–ґ–Ї—Г, –∞ –≤ —А–µ–∞–ї—М–љ–Њ–Љ –і–µ–ї–µ, —А–∞–Ј—Г–Љ–µ–µ—В—Б—П, –Љ–µ—Б—В, –≥–і–µ –љ—Г–ґ–љ—Л–µ —В–∞–Ї–Є–µ –Ј–∞–і–µ—А–ґ–Ї–Є –љ–∞ –Њ–±—Й–µ–љ–Є–µ —Б –њ–µ—А–Є—Д–µ—А–Є–µ–є вАФ –љ–∞–Љ–љ–Њ–≥–Њ –±–Њ–ї—М—И–µ), –Ї–Њ—В–Њ—А–Њ–µ –љ–µ—Б—С—В —З–Є—Б—В–Њ –њ—Б–Є—Е–Њ–ї–Њ–≥–Є—З–µ—Б–Ї–Є –љ–µ–≥–∞—В–Є–≤–љ—Л–є —Н—Д—Д–µ–Ї—В (—Г—Б—В—А–Њ–є—Б—В–≤–Њ –≤—Б—С —А–∞–≤–љ–Њ –±—Г–і–µ—В —А–∞–±–Њ—В–∞—В—М, –љ–Њ —В–µ —В–∞–Ї –±—Л—Б—В—А–Њ, –Ї–∞–Ї —Е–Њ—В–µ–ї–Њ—Б—М –∞–≤—В–Њ—А—Г/–Ј–∞–Ї–∞–Ј—З–Є–Ї—Г), –µ—Б—В—М –Ї—Г–і–∞ –±–Њ–ї–µ–µ —Б–µ—А—М—С–Ј–љ—Л–є –Љ–Њ–Љ–µ–љ—В.
–Ч–∞—З–∞—Б—В—Г—О, –њ—А–Є—Е–Њ–і–Є—В—Б—П –Њ–±—А–∞–±–∞—В—Л–≤–∞—В—М –Ї–∞–Ї–Њ–є-—В–Њ –њ–Њ—В–Њ–Ї –і–∞–љ–љ—Л—Е –Є–ї–Є –≥–µ–љ–µ—А–Є—А–Њ–≤–∞—В—М –Ї–∞–Ї–Њ–є-—В–Њ –њ–Њ—В–Њ–Ї –і–∞–љ–љ—Л—Е (–Є–ї–Є —Б–Є–≥–љ–∞–ї). –Ш –≤ —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ, –≤–Ј—П–≤ —В–∞–Ї—В–Њ–≤—Г—О —З–∞—Б—В–Њ—В—Г –Є —Б–Ї–Њ—А–Њ—Б—В—М –њ–Њ—В–Њ–Ї–∞ –і–∞–љ–љ—Л—Е (–Є–ї–Є —З–∞—Б—В–Њ—В—Г –і–Є—Б–Ї—А–µ—В–Є–Ј–∞—Ж–Є–Є —Б–Є–≥–љ–∞–ї–∞) —Б—В–∞–љ–Њ–≤–Є—В—Б—П –њ–Њ–љ—П—В–љ–Њ, —З—В–Њ, –Ї –њ—А–Є–Љ–µ—А—Г, –љ–∞ –Њ–і–Є–љ –±–∞–є—В –њ–Њ—В–Њ–Ї–∞ –Љ–Њ–ґ–љ–Њ –њ–Њ—В—А–∞—В–Є—В—М 80 —В–∞–Ї—В–Њ–≤ вАФ –Є —Н—В–Њ –њ–Њ—В–Њ–ї–Њ–Ї, –Ї–Њ—В–Њ—А—Л–є –љ–Є–Ї–∞–Ї –љ–µ–ї—М–Ј—П —Б–і–≤–Є–љ—Г—В—М (–њ—А–µ–≤—Л—Б–Є—В—М). –Я–Њ—В–Њ–Љ—Г —З—В–Њ –Є–љ–∞—З–µ –і–∞–љ–љ—Л–µ –њ—А–Є—Е–Њ–і—П—В –±—Л—Б—В—А–µ–µ, —З–µ–Љ –Љ—Л —Г—Б–њ–µ–≤–∞–µ–Љ –Є—Е –Њ–±—А–∞–±–∞—В—Л–≤–∞—В—М, –Є —В–Њ–≥–і–∞ –љ–∞–Љ –љ—Г–ґ–љ–∞ –њ–∞–Љ—П—В—М –і–ї—П –Њ—З–µ—А–µ–і–Є, –≥–і–µ –Њ–љ–Є –±—Г–і—Г—В –љ–∞–Ї–∞–њ–ї–Є–≤–∞—В—М—Б—П, —З—В–Њ –≤–њ—А–Њ—З–µ–Љ –Ј–≤—Г—З–Є—В –Ї–∞–Ї –Ї–∞—В–∞—Б—В—А–Њ—Д–∞, –њ–Њ—В–Њ–Љ—Г –µ—Б–ї–Є –љ–∞–Љ –љ–µ –Њ–±–µ—Й–∞—О—В –њ–µ—А–µ—А—Л–≤–Њ–≤ –≤ –њ–Њ—В–Њ–Ї–µ –і–∞–љ–љ—Л—Е, –Ї–∞–Ї–Њ–є –±—Л –±–Њ–ї—М—И–Њ–є –љ–Є –±—Л–ї–∞ –њ–∞–Љ—П—В—М, –Њ–љ–∞ —А–∞–љ–Њ –Є–ї–Є –њ–Њ–Ј–і–љ–Њ –Ї–Њ–љ—З–Є—В—Б—П.
–Ю–і–Є–љ –Є–Ј –њ—А–Є–Љ–µ—А–Њ–≤, –Ї–Њ—В–Њ—А—Л–є —П –ї—О–±–ї—О –њ—А–Є—Е–Њ–і–Є—В—М: –Њ–і–љ–∞–ґ–і—Л –Љ–љ–µ –њ—А–Є—И–ї–Њ—Б—М –≥–µ–љ–µ—А–Є—А–Њ–≤–∞—В—М –љ–µ–Ї–Є–є —Б–Є–≥–љ–∞–ї —Б —З–∞—Б—В–Њ—В–Њ–є 44,1 –Ї–У—Ж (–љ–µ—Б–ї–Њ–ґ–љ–Њ –і–Њ–≥–∞–і–∞—В—М—Б—П, —З—В–Њ —Н—В–Њ –Ј–∞ —Б–Є–≥–љ–∞–ї). –Т–Ј–≤–µ—Б–Є–≤ –≤—Б–µ –Ј–∞ –Є –њ—А–Њ—В–Є–≤, –±—Л–ї–Њ –њ—А–Є–љ—П—В–Њ —А–µ—И–µ–љ–Є–µ –њ–Њ–љ–Є–Ј–Є—В—М —З–∞—Б—В–Њ—В—Г –і–Є—Б–Ї—А–µ—В–Є–Ј–∞—Ж–Є–Є –і–Њ 40 –Ї–У—Ж. –Я—А–Є –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ–є —З–∞—Б—В–Њ—В–µ –і–ї—П AVR-—З–Є–њ–Њ–≤ —В–Њ–≥–Њ –≤—А–µ–Љ–µ–љ–Є –≤ 20 –Ь–У—Ж (—Б–µ–є—З–∞—Б –µ—Б—В—М —З–Є–њ—Л AVR, –Ї–Њ—В–Њ—А—Л–µ –Љ–Њ–≥—Г—В —А–∞–±–Њ—В–∞—В—М –Є –љ–∞ 24 –Ь–У—Ж) –њ–Њ–ї—Г—З–∞–ї–Њ—Б—М, —З—В–Њ –љ–∞ –Њ–і–Є–љ –Њ—В—Б—З—С—В (sample) –Љ–Њ–ґ–љ–Њ –Ј–∞—В—А–∞—В–Є—В—М –љ–µ –±–Њ–ї–µ–µ 500 —В–∞–Ї—В–Њ–≤. –Э–∞ —Б–∞–Љ–Њ–Љ –ґ–µ –і–µ–ї–µ, –њ–Њ—Б–Ї–Њ–ї—М–Ї—Г –Ї—А–Њ–Љ–µ –≥–µ–љ–µ—А–∞—Ж–Є–Є —Г—Б—В—А–Њ–є—Б—В–≤—Г –њ—А–Є—Е–Њ–і–Є–ї–Њ—Б—М –і–µ–ї–∞—В—М –µ—Й—С –Љ–љ–Њ–≥–Њ —З–µ–≥–Њ, —В–Њ –њ–Њ —Б—Г—В–Є –і–∞–ґ–µ –Љ–µ–љ—М—И–µ, —З–µ–Љ 500 —В–∞–Ї—В–Њ–≤.
–° —Г—З—С—В–Њ–Љ —В–Њ–≥–Њ, —З—В–Њ —Б–Є–≥–љ–∞–ї –≥–µ–љ–µ—А–Є—А–Њ–≤–∞–ї—Б—П –њ–Њ –Њ—З–µ–љ—М —Б–ї–Њ–ґ–љ—Л–Љ –Ј–∞–Ї–Њ–љ–∞–Љ, –Ї–Њ—В–Њ—А—Л–µ —В—А–µ–±–Њ–≤–∞–ї–Є –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П FP-–Љ–∞—В–µ–Љ–∞—В–Є–Ї–Є, –Є –љ–∞ —Д–Њ–љ–µ —В–Њ–≥–Њ, —З—В–Њ –љ–Є–Ї–∞–Ї–Њ–≥–Њ FPU –≤ AVR –љ–µ—В, –Є –≤—Б—О FP-–Љ–∞—В–µ–Љ–∞—В–Є–Ї—Г –њ—А–Є—Е–Њ–і–Є–ї–Њ—Б—М —Н–Љ—Г–ї–Є—А–Њ–≤–∞—В—М —А—Г—З–Ї–∞–Љ–Є, –Є—Б–њ–Њ–ї—М–Ј—Г—П —В–Њ–ї—М–Ї–Њ —Ж–µ–ї–Њ—З–Є—Б–ї–µ–љ–љ—Л–µ –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є, –≤ —Н—В–Є 500 —В–∞–Ї—В–Њ–≤ —П –љ–Є–Ї–∞–Ї –љ–µ –Љ–Њ–≥ —Г–ї–Њ–ґ–Є—В—М—Б—П.
–Ґ–Њ–≥–і–∞ —П –≤—Л–Ї—А—Г—В–Є–ї—Б—П —В–∞–Ї: –≤—Б—О –Љ–∞—В–µ–Љ–∞—В–Є–Ї—Г —Г –Љ–µ–љ—П –≤—Л–њ–Њ–ї–љ—П–ї –љ–µ —Б–∞–Љ —З–Є–њ, –∞ –≤–љ–µ—И–љ–Є–µ —Ж–µ–њ–Є –љ–∞ –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ—Л—Е —Г—Б–Є–ї–Є—В–µ–ї—П—Е вАФ –≤ –ї—Г—З—И–Є—Е —В—А–∞–і–Є—Ж–Є—П—Е –∞–љ–∞–ї–Њ–≥–Њ–≤—Л—Е –Ї–Њ–Љ–њ—М—О—В–µ—А–Њ–≤. –°–Њ–±—Б—В–≤–µ–љ–љ–Њ –≥–Њ–≤–Њ—А—П, –Є–Љ–µ–љ–љ–Њ –і–ї—П —Н—В–Њ–є –Ј–∞–і–∞—З–Є вАФ –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Љ–∞—В–µ–Љ–∞—В–Є—З–µ—Б–Ї–Є—Е –Њ–њ–µ—А–∞—Ж–Є–µ–є вАФ –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ—Л–µ —Г—Б–Є–ї–Є—В–µ–ї–Є –Є –±—Л–ї–Є –Є–Ј–Њ–±—А–µ—В–µ–љ—Л, –Њ—В–Ї—Г–і–∞ –Є –Є–Љ–µ—О—В —Б–≤–Њ—С –љ–∞–Ј–≤–∞–љ–Є–µ.
–Ґ–∞–Ї —З—В–Њ —В–∞–Ї—В—Л вАФ –љ–∞ –≤–µ—Б –Ј–Њ–ї–Њ—В–∞. –Р avr-gcc –њ–Њ–Ј–Њ—А–љ–Њ —Н—В–Є —В–∞–Ї—В—Л –њ—А–Њ—Д—Г–Ї–∞–ї.
–Ш –Ї–∞–Ї–Њ–є –ґ–µ –≤—Л—Е–Њ–і?
–Ъ–Њ–љ–µ—З–љ–Њ –ґ–µ –Љ–Њ–ґ–љ–Њ, —З—Г—В—М –њ–Њ–і—Г–Љ–∞–≤, –Є–Ј–Љ–µ–љ–Є—В—М —Б–Є—И–љ—Л–є –Ї–Њ–і, —З—В–Њ–±—Л –њ–Њ—Б–ї–µ –Ї–Њ–Љ–њ–Є–ї—П—Ж–Є–Є –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є –≤—Л—Б—В—А–Њ–Є–ї–Є—Б—М –≤ –љ—Г–ґ–љ–Њ–Љ –љ–∞–Љ –њ–Њ—А—П–і–Ї–µ.
–Э–∞–њ—А–Є–Љ–µ—А —В–∞–Ї:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
void DoRead(uint8_t * dst)
{
uint8_t i;
for(ADDR_BUS = i = 0, __builtin_avr_delay_cycles(1); i < 128;)
{
*dst++ = DATA_BUS;
ADDR_BUS = ++i;
}
}
–І—В–Њ —Б–Ї–Њ–Љ–њ–Є–ї–Є—А—Г–µ—В—Б—П –≤:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
DoRead:
movw r30, r24
out PORTC, r1 ; –Ъ–Њ–Љ–њ–Є–ї—П—В–Њ—А —В–∞–Ї–ґ–µ —Б–Њ–Ј–і–∞—С—В –њ—А–µ–Є–љ–Є—Ж. –Ї–Њ–і, –Ї–Њ—В–Њ—А—Л–є –Ј–∞–љ–Њ—Б–Є—В 0 –≤ r1 –і–ї—П –њ–Њ–і–Њ–±–љ—Л—Е —Б–ї—Г—З–∞–µ–≤
nop
ldi r25, 0
loop_begin:
in r24, PINB
st Z+, r24
subi r25, 0xFF
out PORTC, r25
cpi r25, 0x80
brne loop_begin
ret
–Я–Њ –њ—А–µ–ґ–љ–µ–Љ—Г –≤—Б—С —В–µ –ґ–µ 6 –Є–љ—Б—В—А—Г–Ї—Ж–Є–є –љ–∞ –Њ–і–љ—Г –Є—В–µ—А–∞—Ж–Є—О, —В–Њ–ї—М–Ї–Њ —В–µ–њ–µ—А—М –Љ–µ–ґ–і—Г –≤—Л—Б—В–∞–≤–ї–µ–љ–Є–µ–Љ –∞–і—А–µ—Б–∞ –Є —Б—З–Є—В—Л–≤–∞–љ–Є–µ–Љ –µ—Б—В—М —В—А–µ–±—Г–µ–Љ–∞—П –Ј–∞–і–µ—А–ґ–Ї–∞.
–Э–Њ –Ј–љ–∞–µ—В–µ —З—В–Њ? –≠—В–Њ –Ї–Њ–і, –Ї–Њ—В–Њ—А—Л–є —Г—Б–њ–µ—И–љ–Њ —Б–Ї–Њ–Љ–њ–Є–ї–Є—А—Г–µ—В—Б—П, –Ї–Њ—В–Њ—А—Л–є —Г—Б–њ–µ—И–љ–Њ –±—Г–і–µ—В —А–∞–±–Њ—В–∞—В—М –љ–∞ —З–Є–њ–µ, –љ–Њ –≤–Њ–Њ–±—Й–µ-—В–Њ —Н—В–Њ –Њ—В–≤—А–∞—В–Є—В–µ–ї—М–љ—Л–є —Б–Є—И–љ—Л–є –Ї–Њ–і, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –Њ–љ –љ–∞—А—Г—И–∞–µ—В —Б–∞–Љ—Г –Є–і–µ—О –љ–∞–њ–Є—Б–∞–љ–Є –љ–∞ –°–Є.
–Э–µ—В –љ–Є–Ї–∞–Ї–Њ–≥–Њ —Г–і–Њ–≤–Њ–ї—М—Б—В–≤–Є—П –њ–Є—Б–∞—В—М –љ–∞ –°–Є, –µ—Б–ї–Є –њ–Њ—Б–ї–µ –і–Њ–±–∞–≤–ї–µ–љ–Є—П –Ї–∞–ґ–і–Њ–є —Б—В—А–Њ—З–Ї–Є –°–Є-–Ї–Њ–і–∞ –љ—Г–ґ–љ–Њ —Б–Љ–Њ—В—А–µ—В—М –∞—Б—Б–µ–Љ–±–ї–µ—А–љ—Л–є –ї–Є—Б—В–Є–љ–≥ –Є –њ—А–Њ–≤–µ—А—П—В—М, –∞ –≤ —В–Њ–Љ –ї–Є –њ–Њ—А—П–і–Ї–µ –ї–µ–≥–ї–Є –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є, –Ї–∞–Ї–Њ–є –Њ–±–µ—Б–њ–µ—З–Є—В –љ—Г–ґ–љ—Г—О –Ј–∞–і–µ—А–ґ–Ї—Г?
–Э–Њ, —З—В–Њ –±–Њ–ї–µ–µ –≤–∞–ґ–љ–Њ, –Є–і–µ—П –њ—А–Њ–≥—А–∞–Љ–Љ–Є—А–Њ–≤–∞–љ–Є—П –љ–∞ –°–Є –њ—А–Є–Љ–µ—А–љ–Њ —В–∞–Ї–∞—П: –њ—А–Њ–≥—А–∞–Љ–Љ–∞ –љ–∞—З–Є–љ–∞–µ—В –Є–Љ–µ—В—М –љ–µ–Љ–љ–Њ–≥–Њ –і–µ–Ї–ї–∞—А–∞—В–Є–≤–љ—Л–є —Е–∞—А–∞–Ї—В–µ—А. –Т—Л –њ—А–Њ—Б—В–Њ –і–Є–Ї—В—Г–µ—В–µ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А—Г, –Ї–∞–Ї–Є–µ –Љ–∞–љ–Є–њ—Г–ї—П—Ж–Є–Є –і–∞–љ–љ—Л–Љ–Є –Є –≤ –Ї–∞–Ї–Њ–Љ –њ–Њ—А—П–і–Ї–µ –і–Њ–ї–ґ–љ—Л –њ—А–Њ–Є–Ј–Њ–є—В–Є, –Є –≤–∞—Б –љ–Є –Ї–∞–њ–ї–Є –љ–µ –≤–Њ–ї–љ—Г–µ—В, –Ї–∞–Ї –Њ–љ —Н—В–Њ —Б–і–µ–ї–∞–µ—В вАФ –Ї–∞–Ї–Є–µ –∞–њ–њ–∞—А–∞—В–љ—Л–µ —А–µ—Б—Г—А—Б—Л –њ—А–Є–≤–ї–µ—З—С—В, –Ї–∞–Ї —А–∞—Б–њ–Њ—А—П–і–Є—В—Б—П —А–µ–≥–Є—Б—В—А–∞–Љ–Є, –Ї–∞–Ї–Є–µ –≤—Л–њ–Њ–ї–љ–Є—В –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є. –Ю–љ –Љ–Њ–ґ–µ—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —А–∞–Ј–љ—Л–µ —А–µ–≥–Є—Б—В—А—Л, —А–∞–Ј–љ—Л–µ –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є, –≤ –ї—О–±–Њ–Љ –њ–Њ—А—П–і–Ї–µ, –љ–Њ —З—В–Њ –Є–≥—А–∞–µ—В —А–Њ–ї—М, —В–∞–Ї —Н—В–Њ —В–Њ, —З—В–Њ –Љ–∞–љ–Є–њ—Г–ї—П—Ж–Є–Є –љ–∞–і –і–∞–љ–љ—Л–Љ–Є –њ—А–Њ–Є–Ј–Њ–є–і—С—В –Є–Љ–µ–љ–љ–Њ —В–∞–Ї, –Ї–∞–Ї —Г–Ї–∞–Ј–∞–ї –њ—А–Њ–≥—А–∞–Љ–Љ–Є—Б—В.
вАФ–†–∞—Б—И–Є–±–Є—Б—М –≤ –ї–µ–њ—С—И–Ї—Г, –љ–Њ —Б–і–µ–ї–∞–є —В–∞–Ї, —З—В–Њ–±—Л —В—А–µ–±—Г–µ–Љ—Л–µ –Љ–∞–љ–Є–њ—Г–ї—П—Ж–Є–Є —Б–Њ–≤–µ—А—И–Є–ї–Є—Б—М, –Є —Б–і–µ–ї–∞–є —Н—В–Њ –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ –±—Л—Б—В—А—Л–Љ –њ—Г—В—С–Љ, –њ–Њ–ґ–∞–ї—Г–є—Б—В–∞.
–≠—В–Њ –Є–Љ–µ–љ–љ–Њ —В–Њ, —З—В–Њ –њ–Њ–Ј–≤–Њ–ї—П–µ—В –њ–Є—Б–∞—В—М –љ–∞ –°–Є –Њ–і–Є–љ –Ї–Њ–і, –Ї–Њ—В–Њ—А—Л–є –Љ–Њ–ґ–љ–Њ —Б–Ї–Њ–Љ–њ–Є–ї–Є—А–Њ–≤–∞—В—М –њ–Њ–і –і–µ—Б—П—В–Ї–Є —А–∞–Ј–љ—Л—Е –∞—А—Е–Є—В–µ–Ї—В—Г—А, –Є –Њ–љ –±—Г–і–µ—В —А–∞–±–Њ—В–∞—В—М –≤–µ–Ј–і–µ, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –Љ—Л –њ—А–Њ—Б—В–Њ –і–µ–Ї–ї–∞—А–Є—А—Г–µ–Љ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А—Г, –≤ –Ї–∞–Ї–Њ–є –Љ–Њ–Љ–µ–љ—В –Ї–∞–Ї–Є–µ –≤–µ—Й–Є –љ–∞–і –і–∞–љ–љ—Л–Љ–Є –і–Њ–ї–ґ–љ—Л –±—Л—В—М —Б–і–µ–ї–∞–љ—Л (–∞ –љ–µ –Ї–∞–Ї –Є–Љ–µ–љ–љ–Њ). –Ш –Љ—Л –љ–µ –і—Г–Љ–∞–µ–Љ –љ–∞–і –њ–Њ—А—П–і–Ї–Њ–Љ –Є–љ—Б—В—А—Г–Ї—Ж–Є–є, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –≤—Л–±–Є—А–∞–µ—В –Њ–њ—В–Є–Љ–∞–ї—М–љ—Л–є –Є –њ—А–∞–≤–Є–ї—М–љ—Л–є. –Х—Б–ї–Є —Б—В—А–Њ–Ї–Є —Б–Є—И–љ–Њ–≥–Њ –Ї–Њ–і–∞ –њ—А–Є—Е–Њ–і–Є—В—Б—П –њ–Њ–і–≥–Њ–љ—П—В—М –њ–Њ–і —А–µ–Ј—Г–ї—В–Є—А—Г—О—Й–Є–є –∞—Б—Б–µ–Љ–±–ї–µ—А–љ—Л–є –ї–Є—Б—В–Є–љ–≥, —В–Њ —Н—В–Њ —Г–ґ–µ —Б–Є-–њ—А–Њ–≥—А–∞–Љ–Љ–Є—А–Њ–≤–∞–љ–Є–µ —Б –і—Г—А–љ—Л–Љ –Ј–∞–њ–∞—Е–Њ–Љ.
–Ш –≤–µ—И–µ–њ—А–Є–≤–µ–і—С–љ–љ—Л–є –њ–Њ—Б–ї–µ–і–љ–Є–є —Б–Є—И–љ—Л–є –ї–Є—Б—В–Є–љ–≥ –њ–ї–Њ—Е —В–µ–Љ, —З—В–Њ –µ—Б–ї–Є –µ–≥–Њ —Б–Ї–Њ–Љ–њ–Є–ї–Є—А–Њ–≤–∞—В—М –њ–Њ–і –љ–µ–Ї–Є–є –≥–Є–њ–Њ—В–µ—В–Є—З–µ—Б–Ї–Є–є —З–Є–њ, —Г –Ї–Њ—В–Њ—А–Њ–≥–Њ —В–∞–Ї—В–Њ–≤–∞—П —З–∞—Б—В–Њ—В–∞ –±—Г–і–µ—В –≤ 2 —А–∞–Ј –±–Њ–ї—М—И–µ, —В–Њ –њ–Њ–ї—Г—З–Є—И–Є–≤—И–Є–є—Б—П –Ї–Њ–і –Њ–њ—П—В—М –љ–µ –±—Г–і–µ—В —А–∞–±–Њ—В–∞—В—М.
–•–Њ—А–Њ—И–µ–µ –њ—А–Њ–≥—А–∞–Љ–Љ–Є—А–Њ–≤–∞–љ–Є–µ –°–Є —Б–Њ—Б—В–Њ–Є—В –≤ —В–Њ–Љ, —З—В–Њ —П –љ–µ –њ–Њ–і–≥–Њ–љ—П—О —Б–Є—И–љ—Л–є –Ї–Њ–і –њ–Њ–і —А–µ–∞–ї–Є–Є –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Є–љ—Б—В—А—Г–Ї—Ж–Є–є, –∞ –њ—А–Њ—Б—В–Њ –њ–Є—И—Г, —З—В–Њ –Љ–љ–µ –љ—Г–ґ–љ–Њ —Б–і–µ–ї–∞—В—М.
–Р –Љ–љ–µ –љ—Г–ґ–љ–Њ –≤—Л—Б—В–∞–≤–Є—В—М –∞–і—А–µ—Б, –њ–Њ–і–Њ–ґ–і–∞—В—М, –Є —Б—З–Є—В–∞—В—М –і–∞–љ–љ—Л–µ.
–Ч–љ–∞—З–Є—В —Н—В–Њ –і–Њ–ї–ґ–љ–Њ –±—Л—В—М –љ–∞–њ–Є—Б–∞–љ–Њ —В–∞–Ї:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
ADDR_BUS = i;
SMART_DELAY_NS(MEMORY_DELAY);
dstbuf[i] = DATA_BUS;
–У–і–µ SMART_DELAY_NS вАФ¬†–њ—А–Њ—Б—В–Њ –Љ–∞–Ї—А–Њ—Б, –Ї–Њ—В–Њ—А—Л–є –Ј–∞–і–µ—А–ґ–Ї—Г –≤ –љ–∞–љ–Њ—Б–µ–Ї—Г–љ–і–∞—Е –њ–µ—А–µ—Б—З–Є—В—Л–≤–∞–µ—В –≤ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —В–∞–Ї—В–Њ–≤, –Ї–Њ—В–Њ—А–Њ–µ –љ—Г–ґ–љ–Њ –њ–µ—А–µ–і–∞—В—М __builtin_avr_delay_cycles(), —З—В–Њ–±—Л –≤ –љ—Г–ґ–љ–Њ–Љ –Љ–µ—Б—В–µ –≤–Њ–Ј–љ–Є–Ї–ї–∞ –љ—Г–ґ–љ–∞—П –Ј–∞–і–µ—А–ґ–Ї–∞.
–Ґ–Њ –µ—Б—В—М –њ—А–Є–Љ–µ—А–љ–Њ —В–∞–Ї–Њ–є:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
#define CLOCK_PERIOD (1000000000 / F_CPU)
#define SMART_DELAY_NS(ns) __builtin_avr_delay_cycles((ns) / CLOCK_PERIOD + 1)
–Ш –≤—Б—С! –≠—В–Њ—В –њ–Њ—А—В–Є—А—Г–µ–Љ—Л–є –Ї–Њ–і —Б–Ї–Њ–Љ–њ–Є–ї–Є—А–Њ–≤–∞–ї—Б—П –±—Л –њ–Њ–і —З–Є–њ —Б –ї—О–±–Њ–є —В–∞–Ї—В–Њ–≤–Њ–є —З–∞—Б—В–Њ—В–Њ–є. –Я–Њ—В–Њ–Љ—Г —З—В–Њ –±—Г–і—М –Ї–Њ–Љ–њ–Є–ї—П—Ж–Є—П intrinsic-—Д—Г–љ–Ї—Ж–Є–Є __builtin_avr_delay_cycles() –і–Њ—Б—В–∞—В–Њ—З–љ–Њ —Г–Љ–љ–Њ–є (–Є–ї–Є –±—Г–і—М –Њ–њ—В–Є–Љ–Є–Ј–∞—В–Њ—А –і–Њ—Б—В–∞—В–Њ—З–љ–Њ —Г–Љ–љ—Л–Љ), –њ—А–Є –њ—А–µ–њ—А–Њ—Ж–µ—Б—Б–Є–љ–≥–µ –∞—А–≥—Г–Љ–µ–љ—В –і–ї—П __builtin_avr_delay_cycles() –њ–Њ–і—Б—В–∞–≤–Є–ї—Б—П –±—Л –љ—Г–ґ–љ—Л–є, –∞ —Б–∞–Љ ¬Ђ–≤—Л–Ј–Њ–≤¬ї __builtin_avr_delay_cycles() –Ј–∞—Б—В–∞–≤–Є–ї –±—Л –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А —Б–Њ–Ј–і–∞—В—М —В—А–µ–±—Г–µ–Љ—Г—О –Ј–∞–і–µ—А–ґ–Ї—Г –њ–µ—А–µ—Б—В–∞–≤–ї—П—П –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є, –Ї–Њ—В–Њ—А—Л–µ –Љ–Њ–ґ–љ–Њ –њ–µ—А–µ—Б—В–∞–≤–ї—П—В—М, –Є –љ–µ —Г–≤–µ–ї–Є—З–Є–≤–∞—П –≤—А–µ–Љ—П –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Ї–Њ–і–∞. –Ш —В–Њ–ї—М–Ї–Њ –Ї–Њ–≥–і–∞ –≤—Б–µ—Е –Є–љ—Б—В—А—Г–Ї—Ж–Є–є, –Ї–Њ—В–Њ—А—Л–µ –Љ–Њ–ґ–љ–Њ –њ–µ—А–µ—Б—В–∞–≤–Є—В—М, –љ–µ —Е–≤–∞—В–∞–ї–Њ –±—Л –і–ї—П –Њ–±–µ—Б–њ–µ—З–µ–љ–Є—П –Ј–∞–њ—А–Њ—И–µ–љ–љ–Њ–є –Ј–∞–і–µ—А–ґ–Ї–Є, –±—Л–ї–Њ –±—Л –і–Њ–њ—Г—Б—В–Є–Љ–Њ –і–Њ–±–∞–≤–ї—П—В—М –≤ –Ї–Њ–і NOP-—Л –і–ї—П –і–Њ–њ. —В–∞–Ї—В–Њ–≤.
–Р—Б—Б–µ–Љ–±–ї–µ—А vs. –°–Є?
–Э–Њ —Г–≤—Л, –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –Њ–Ї–∞–Ј–∞–ї—Б—П –љ–µ —В–∞–Ї–Є–Љ —Г–Љ–љ—Л–Љ, –∞ –њ–Њ—Н—В–Њ–Љ—Г –≤ –Њ—З–µ—А–µ–і–љ–Њ–є —А–∞–Ј –њ—А–Є–і—С—В—Б—П –њ–Є—Б–∞—В—М –Ї–Њ–і –љ–∞ –∞—Б—Б–µ–Љ–±–ї–µ—А–µ, —Е–Њ—В—П –Њ—З–µ–љ—М —Е–Њ—В–µ–ї–Њ—Б—М –љ–∞–њ–Є—Б–∞—В—М –љ–∞¬†–°–Є.
–Т –і–Њ–≤–µ—Б–Њ–Ї
–Ъ—В–Њ-—В–Њ –Љ–Њ–ґ–µ—В —Б–Ї–∞–Ј–∞—В—М:
вАФ –Ґ—Л —Е–Њ—З–µ—И—М –Њ—В –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–∞ —Б–ї–Є—И–Ї–Њ–≥–Њ –Љ–љ–Њ–≥–Њ: —Б–Ї–Њ—А–µ–є –≤—Б–µ–≥–Њ, –Ї–Њ–Љ–њ–Є–ї—П—Ж–Є—П intrinsic-—Д—Г–љ–Ї—Ж–Є–Є –њ—А–Њ—Б—В–Њ –њ–Њ—А–Њ–ґ–і–∞–µ—В –љ—Г–ґ–љ–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –њ–∞—А–∞–Ј–Є—В–љ—Л—Е –Є–љ—Б—В—А—Г–Ї—Ж–Є–є –Є –љ–µ –Є–Љ–µ–µ—В –њ—А–∞–≤–∞ –Њ—Б—Г—Й–µ—Б—В–≤–ї—П—В—М –њ–µ—А–µ—Б—В–∞–љ–Њ–≤–Ї–Є –і—А—Г–≥–Є—Е –Є–љ—Б—В—А—Г–Ї—Ж–Є–є, –Є –ї–Є—И—М –Њ–њ—В–Є–Љ–Є–Ј–∞—В–Њ—А –Є–Љ–µ–µ—В –њ–Њ–ї–љ–Њ–Љ–Њ—З–Є—П –њ–µ—А–µ–Ї—А–∞–Є–≤–∞—В—М –Ї–Њ–і, –≤—Л—А–µ–Ј–∞—П –Є –њ–µ—А–µ—Б—В–∞–≤–ї—П—П –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є, –љ–Њ –Њ–љ –љ–µ –Є–Љ–µ–µ—В –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є –Ј–љ–∞—В—М, –Љ–Њ–ґ–љ–Њ –ї–Є –ї–Є–Ї–≤–Є–і–Є—А–Њ–≤–∞—В—М nop-–Є–љ—Б—В—А—Г–Ї—Ж–Є—О, –Є–±–Њ –њ–Њ–Љ–Є–Љ–Њ —Б–ї—Г—З–∞–µ–≤, –Ї–Њ–≥–і–∞ nop –њ–Њ—П–≤–Є–ї—Б—П –Є–Ј-–Ј–∞ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П delay-—Д—Г–љ–Ї—Ж–Є–Є, nop –Љ–Њ–≥ –њ–Њ—П–≤–Є—В—Б—П –Є–Ј-–Ј–∞ –∞—Б—Б–µ–Љ–±–ї–µ—А–љ–Њ–є –≤—Б—В–∞–≤–Ї–Є, –Є —В–Њ–≥–і–∞, –µ—Б–ї–Є –µ–≥–Њ —Г–±—А–∞—В—М, –±—Г–і–µ—В –Љ–љ–Њ–≥–Њ –Ї—А–Є–Ї–Њ–≤, —З—В–Њ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А —З—Г–і–Є—В –Є –њ—А–∞–≤–Є—В –Ї—Г—Б–Ї–Є –∞—Б–Љ-–Ї–Њ–і–∞, –≤—Б—В–∞–≤–ї–µ–љ–љ—Л–µ –∞—Б–Љ-–≤—Б—В–∞–≤–Ї–∞–Љ–Є.
–Я—А–µ–Ї—А–∞—Б–љ–Њ –њ–Њ–љ–Є–Љ–∞—О, —З—В–Њ —Б–Ї–Њ—А–µ–µ –≤—Б–µ–≥–Њ –Є–Љ–µ–љ–љ–Њ —В–∞–Ї –≤—Б—С –Є –Њ–±—Б—В–Њ–Є—В. –Э–Њ –≤ —А–∞–Ј—А–∞–±–Њ—В–Ї–µ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–Њ–≤ –Њ–±—Л—З–љ–Њ —Г—З–∞—Б—В–≤—Г—О—В —Г–Љ–љ—Л–µ –ї—О–і–Є, –∞ –љ—Г–ґ–љ–Њ –±—Л—В—М –і—Г—А–∞–Ї–Њ–Љ, —З—В–Њ–±—Л –љ–µ –і–Њ–≥–∞–і–∞—В—М—Б—П –≤ —Б—В—А—Г–Ї—В—Г—А–µ –і–∞–љ–љ—Л—Е, –њ—А–µ–і—Б—В–∞–≤–ї—П—О—Й–µ–є —Б–≥–µ–љ–µ—А–Є—А–Њ–≤–∞–љ–љ—Г—О –Є–љ—Б—В—А—Г–Ї—Ж–Є—О, –љ–µ —Б–і–µ–ї–∞—В—М —Д–ї–∞–≥, –Ї–Њ—В–Њ—А—Л–є –±—Л –Є–љ—Д–Њ—А–Љ–Є—А–Њ–≤–∞–ї –Њ–њ—В–Є–Љ–Є–Ј–∞—В–Њ—А –Њ —В–Њ–Љ, —П–≤–ї—П–µ—В—Б—П –ї–Є –љ–∞—Е–Њ–ґ–і–µ–љ–Є–µ —Н—В–Њ–є –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є –≤ —Н—В–Њ–Љ –Љ–µ—Б—В–µ –ґ–µ–ї–µ–Ј–љ–Њ–є –≤–Њ–ї–µ–є –њ—А–Њ–≥—А–∞–Љ–Љ–Є—Б—В–∞ (—В–Њ –µ—Б—В—М –Є–љ—Б—В—А—Г–Ї—Ж–Є—П –±—Л–ї–∞ —З–∞—Б—В—М—О –∞—Б—Б–µ–Љ–±–ї–µ—А–љ–Њ–є –≤—Б—В–∞–≤–Ї–Є), –ї–Є–±–Њ –ґ–µ –Њ–љ–∞ –±—Л–ї–∞ —Б–≥–µ–љ–µ—А–Є—А–Њ–≤–∞–љ–∞ –∞–≤—В–Њ–Љ–∞—В–Є—З–µ—Б–Ї–Є, –Є –Ј–љ–∞—З–Є—В —Н—В–Њ—В –Ї—Г—Б–Њ—З–µ–Ї –Љ–Њ–ґ–љ–Њ –њ–µ—А–µ–Ї—А–∞–Є–≤–∞—В—М –Ї–∞–Ї —Г–≥–Њ–і–љ–Њ.
–Ґ–∞–Ї —З—В–Њ —Н—В–Њ –≤–Њ–≤—Б–µ –љ–µ –Њ–њ—А–∞–≤–і–∞–љ–Є–µ.
–Э–Њ –Є –њ–Њ–Љ–Є–Љ–Њ —В–Њ–≥–Њ, —З—В–Њ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –і–µ–ї–∞–µ—В –Ј–∞–і–µ—А–ґ–Ї–Є nop-–∞–Љ–Є, –≤–Љ–µ—Б—В–Њ —В–Њ–≥–Њ, —З—В–Њ–±—Л –њ–Њ–і—Б—В–∞–≤–Є—В—М —В—Г–і–∞ –њ–Њ–ї–µ–Ј–љ—Л–µ –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є, –і–∞–ґ–µ –љ–∞ —Н—В–Њ–Љ –Ї—А–Њ—Е–Њ—В–љ–Њ–Љ –і–µ–Љ–Њ–љ—Б—В—А–∞—Ж–Є–Њ–љ–љ–Њ–Љ –њ—А–Є–Љ–µ—А–µ –µ—Б—В—М –µ—Й—С –Њ–і–љ–Њ –њ—А–Њ—П–≤–ї–µ–љ–Є–µ –њ–ї–Њ—Е–Њ–є –Ї–Њ–і–Њ–≥–µ–љ–µ—А–∞—Ж–Є–Є.
–Ю–±—А–∞—В–Є—В–µ –≤–љ–Є–Љ–∞–љ–Є–µ, –Ї–∞–Ї –Ї–Њ–Љ–њ–Є–ї–Є—А—Г–µ—В—Б—П —Г—Б–ї–Њ–≤–Є–µ –њ—А–Њ–і–Њ–ї–ґ–µ–љ–Є–µ/–≤—Л—Е–Њ–і–∞ for-—Ж–Є–Ї–ї–∞ i < 128.
–Т –њ—А–Є–љ—Ж–Є–њ–µ, –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А—Г —Е–≤–∞—В–∞–µ—В —Г–Љ–∞ –њ–Њ–љ—П—В—М, —З—В–Њ, –њ–Њ—Б–Ї–Њ–ї—М–Ї—Г i –Њ–±—К—П–≤–ї–µ–љ–∞ –±–µ–Ј volatile –Є —Г–Ї–∞–Ј–∞—В–µ–ї—М –љ–∞ i –≤–љ—Г—В—А–Є —Ж–Є–Ї–ї–∞ –љ–µ –њ–µ—А–µ–і–∞—С—В—Б—П –≤ –Ї–∞–Ї–Є–µ-—В–Њ –≤–љ–µ—И–љ–Є–µ –њ—А–Њ—Ж–µ–і—Г—А—Л, –Ї–Њ—В–Њ—А—Л–µ –Љ–Њ–≥–ї–Є –±—Л —Б–і–µ–ї–∞—В—М —Б –µ—С –Ј–љ–∞—З–µ–љ–Є–µ–Љ —З—В–Њ —Г–≥–Њ–і–љ–Њ), –Ј–љ–∞—З–µ–љ–Є–µ –њ–µ—А–µ–Љ–µ–љ–Њ–є i –љ–Є–Ї–Њ–≥–і–∞ –љ–µ –і–Њ—Б—В–Є–≥–љ–µ—В –Ј–љ–∞—З–µ–љ–Є—П –±–Њ–ї—М—И–µ 128.
–Я–Њ—Н—В–Њ–Љ—Г –Њ–љ –≤–Љ–µ—Б—В–Њ {—Б—А–∞–≤–љ–Є—В—М; –µ—Б–ї–Є –Љ–µ–љ—М—И–µ вАФ –≤–µ—А–љ—Г—В—М—Б—П –≤ –љ–∞—З–∞–ї–Њ —Ж–Є–Ї–ї–∞} –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В –њ–Њ–і—Е–Њ–і {—Б—А–∞–≤–љ–Є—В—М;¬†–µ—Б–ї–Є¬†–љ–µ¬†—А–∞–≤–љ–Њ¬†вАФ¬†–≤–µ—А–љ—Г—В—М—Б—П¬†–≤¬†–љ–∞—З–∞–ї–Њ¬†—Ж–Є–Ї–ї–∞}. –Т–Њ—В —В–Њ–ї—М–Ї–Њ –≤—Л–≥–Њ–і—Л –Њ—В —В–∞–Ї–Њ–≥–Њ —В—А—О–Ї–∞ вАФ –љ–Є–Ї–∞–Ї–Њ–є.
–Ч–∞—В–Њ –µ—Б—В—М –Ї–Њ–µ-—З—В–Њ, –і–Њ —З–µ–≥–Њ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А –љ–µ –і–Њ–≥–∞–і–∞–ї—Б—П. AVR, –Ї–∞–Ї –Є –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ –і—А—Г–≥–Є—Е –њ—А–Њ—Ж–µ—Б—Б–Њ—А–љ—Л—Е –∞—А—Е–Є—В–µ–Ї—В—Г—А, –і–ї—П –њ—А–µ–і—Б—В–∞–≤–ї–µ–љ–Є—П –Њ—В—А–Є—Ж–∞—В–µ–ї—М–љ—Л—Е —З–Є—Б–µ–ї –њ–Њ–ї—М–Ј—Г–µ—В—Б—П –Є–і–µ–µ–є, —З—В–Њ –Њ—В—А–Є—Ж–∞—В–µ–ї—М–љ—Л–µ —З–Є—Б–ї–∞ –Є–Љ–µ—О—В —Б—В–∞—А—И–Є–є –±–Є—В —А–∞–≤–љ—Л–є –µ–і–Є–љ–Є—Ж–µ, –њ—А–Є—З—С–Љ –Ј–∞ 127 (0x7F) —Б–ї–µ–і—Г–µ—В вАУ128 (0x80), —В–Њ –µ—Б—В—М –≤—Б–µ —З–Є—Б–ї–∞, –Ї–Њ—В–Њ—А—Л–µ –±–Њ–ї—М—И–µ 127 –≤ —Б–≤–Њ–µ–є –±–µ–Ј–Ј–љ–∞–Ї–Њ–≤–Њ–є –Є–љ—В–µ—А–њ—А–µ—В–∞—Ж–Є–Є, –≤ –Ј–љ–∞–Ї–Њ–≤–Њ–є –Є–љ—В–µ—А–њ—А–µ—В–∞—Ж–Є–Є –Є–Љ–µ—О—В —Б–Љ—Л—Б–ї–Њ–≤–Њ–µ –Ј–љ–∞—З–µ–љ–Є–µ —А–∞–≤–љ–Њ–µ (–±–µ–Ј–Ј–љ–∞–Ї–Њ–≤–Њ–µ вАУ 256), (–њ–Њ—Н—В–Њ–Љ—Г 255 (0xFF) –Њ–Ј–љ–∞—З–∞–µ—В –Љ–Є–љ—Г—Б 1).
–Р –љ–∞–Љ, –љ–∞–њ–Њ–Љ–љ—О, –љ—Г–ґ–љ–Њ –≤—Л—Е–Њ–і–Є—В—М –Є–Ј —Ж–Є–Ї–ї–∞, –Ї–Њ–≥–і–∞ i –Љ–µ–љ—П–µ—В—Б—П —Б–Њ 127 –љ–∞ 128. –Р —Н—В–Њ, –њ—А–Є –≤–Ј–≥–ї—П–і–µ —Б –і—А—Г–≥–Њ–є —Б—В–Њ—А–Њ–љ—Л, –Њ–Ј–љ–∞—З–∞–µ—В, —З—В–Њ –≤—Л—Е–Њ–і–Є—В—М –Є–Ј —Ж–Є–Ї–ї–∞ –љ—Г–ґ–љ–Њ, –Ї–Њ–≥–і–∞ —Б—В–∞—А—И–Є–є –±–Є—В —А–µ–≥–Є—Б—В—А–∞ R25 —Б—В–∞–≤–Є—В—Б—П –µ–і–Є–љ–Є—З–Ї–Њ–є (–і–Њ —Н—В–Њ–≥–Њ –њ–Њ —Е–Њ–і—Г —Ж–Є–Ї–ї–∞ –Њ–љ –±—Л–ї 0). –Р —Г AVR –≤–Њ —Д–ї–∞–≥–Њ–≤–Њ–Љ (—Б—В–∞—В—Г—Б–љ–Њ–Љ) —А–µ–≥–Є—Б—В—А–µ –µ—Б—В—М —Д–ї–∞–≥ N, —Б–Љ—Л—Б–ї –Ї–Њ—В–Њ—А–Њ–≥–Њ вАФ ¬Ђ—А–µ–Ј—Г–ї—М—В–∞—В –њ–Њ—Б–ї–µ–і–љ–µ–є –Њ–њ–µ—А–∞—Ж–Є–Є –±—Л–ї –Њ—В—А–Є—В—Ж–∞—В–µ–ї—М–љ—Л–Љ¬ї. –Ш–ї–Є, –і—А—Г–≥–Є–Љ–Є —Б–ї–Њ–≤–∞–Љ–Є: –њ–Њ—Б–ї–µ –∞—А–Є—Д–Љ–µ—В–Є—З–µ—Б–Ї–Є—Е –Њ–њ–µ—А–∞—Ж–Є–є —Д–ї–∞–≥ N —А–∞–≤–µ–љ —Б—В–∞—А—И–µ–Љ—Г –±–Є—В—Г —А–µ–Ј—Г–ї—М—В–∞—В–∞ –Њ–њ–µ—А–∞—Ж–Є–Є.
–Р —А–∞–Ј –µ—Б—В—М —Д–ї–∞–≥, –µ—Б—В—М –Є —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й–∞—П –Є–љ—Б—В—А—Г–Ї—Ж–Є—П —Г—Б–ї–Њ–≤–љ–Њ–≥–Њ –њ–µ—А–µ—Е–Њ–і–∞, –≤–µ—А–љ–µ–µ, –і–∞–ґ–µ –і–≤–µ:
- BRMI вАФ Branch if Minus вАФ¬†–њ–µ—А–µ—Е–Њ–і –Њ—Б—Г—Й–µ—Б—В–≤–ї—П–µ—В—Б—П, –µ—Б–ї–Є —А–µ–Ј—Г–ї—М—В–∞—В –Њ–њ–µ—А–∞—Ж–Є–Є –±—Л–ї –Њ—В—А–Є—Ж–∞—В–µ–ї—М–љ—Л–Љ (—В–Њ –µ—Б—В—М –µ—Б–ї–Є N = 1).
- BRPL вАФ Branch if Plus вАФ¬†–њ–µ—А–µ—Е–Њ–і –Њ—Б—Г—Й–µ—Б—В–≤–ї—П–µ—В—Б—П, –µ—Б–ї–Є —А–µ–Ј—Г–ї—М—В–∞—В –±—Л–ї –љ–µ –Њ—В—А–Є—Ж–∞—В–µ–ї—М–љ—Л–Љ (—В–Њ –µ—Б—В—М –µ—Б–ї–Є N = 0).
–Э–∞–Љ –љ—Г–ґ–љ–Њ –≤–Њ–Ј–≤—А–∞—Й–∞—В—М—Б—П –≤ –љ–∞—З–∞–ї–Њ —Ж–Є–Ї–ї–∞, –µ—Б–ї–Є i –љ–µ –і–Њ—Б—В–Є–≥ 0x80 (128), —В–Њ –µ—Б—В—М –µ—Б–ї–Є N —Б–±—А–Њ—И–µ–љ.
–≠—В–Њ –Њ–Ј–љ–∞—З–∞–µ—В, —З—В–Њ –≤–Љ–µ—Б—В–Њ –њ–∞—А—Л –Є–љ—Б—В—А—Г–Ї—Ж–Є–є (cpi+brne)
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
subi r25, 0xFF
cpi r25, 0x80
brne loop_begin
–Љ–Њ–ґ–љ–Њ –±—Л–ї–Њ –Њ–±–Њ–є—В–Є—Б—М –Њ–і–љ–Њ–є (brpl):
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
subi r25, 0xFF
brpl loop_begin
–Т–Њ—В –µ—Й—С –Њ–і–Є–љ —Б—Н–Ї–Њ–љ–Њ–Љ–ї–µ–љ–љ—Л–є —В–∞–Ї—В (cpi –Ј–∞–љ–Є–Љ–∞–µ—В –Њ–і–Є–љ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–љ—Л–є —Ж–Є–Ї–ї).
–Р —В–∞–Ї—В—Л вАФ –љ–∞ –≤–µ—Б –Ј–Њ–ї–Њ—В–∞ (–Є–љ–Њ–≥–і–∞ —Д–ї–µ—И-–њ–∞–Љ—П—В—М, –≤ –Ї–Њ—В–Њ—А–Њ–є —Е—А–∞–љ–Є—В—Б—П –Ї–Њ–і вАФ —В–Њ–ґ–µ).
–Э–∞ –≥–ї—Г–њ–Њ–є –Њ–±—А–∞–±–Њ—В–Ї–µ __builtin_avr_delay_cycles() –Љ—Л –њ–Њ–ї—Г—З–∞–ї–Є —Г–≤–µ–ї–Є—З–µ–љ–Є–µ –≤—А–µ–Љ–µ–љ–Є –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –љ–∞ 25%, –∞ –Ј–і–µ—Б—М –Є–Ј-–Ј–∞ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П –ї–Є—И–љ–µ–є –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є вАФ —Г–≤–µ–ї–Є—З–µ–љ–Є–µ –≤—А–µ–Љ–µ–љ–Є –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –љ–∞ 14.2%.
_______
–Я—А–µ–і–ї–∞–≥–∞—О –і–∞–≤–∞—В—М —Б—Б—Л–ї–Ї—Г –љ–∞ —Н—В–Њ—В —В–Њ–њ–Є–Ї, –µ—Б–ї–Є –≤–∞–Љ –і–Њ–≤–µ–і—С—В—Б—П –≤—Б—В—А–µ—В–Є—В—М —Е–Њ–ї–Є–≤–∞—А ¬Ђ–°–Є vs. –∞—Б—Б–µ–Љ–±–ї–µ—А¬ї, –њ—А–Њ–≤–Њ–і–Є–Љ—Л–є –≤ —Б—А–µ–і–µ —Н–ї–µ–Ї—В—А–Њ–љ—Й–Є–Ї–Њ–≤ –Є –њ—А–Њ–≥—А–∞–Љ–Љ–Є—Б—В–Њ–≤ –і–ї—П –Љ–Є–Ї—А–Њ–Ї–Њ–љ—В—А–Њ–ї–ї–µ—А–Њ–≤. –Я–Њ–љ–Є–Љ–∞—О, —З—В–Њ –≤ —Ж–µ–ї–Њ–Љ —В–µ–Љ–∞—В–Є–Ї–∞ VBStreets –і–∞–ї–µ–Ї–∞ –Њ—В —Н—В–Њ–є –Њ–±–ї–∞—Б—В–Є –Ј–љ–∞–љ–Є–є, –љ–Њ, —В–µ–Љ –љ–µ –Љ–µ–љ–µ–µ, —П –љ–µ–Њ–і–љ–Њ–Ї—А–∞—В–љ–Њ –≤—Б—В—А–µ—З–∞–ї –Ј–і–µ—Б—М –ї—О–і–µ–є, —Б–≤—П–Ј–∞–љ–љ—Л—Е —Б —В–µ–Љ–Њ–є.


