–Ы–µ—З–Є–Љ —А–Њ–і–љ–Њ–є –і—А–∞–є–≤–µ—А–Я–Њ —Н—В–Њ–є –њ—А–Є—З–Є–љ–µ —П –љ–∞—З–∞–ї —Б –і—А–∞–є–≤–µ—А–∞. –Ъ —В–Њ–Љ—Г –ґ–µ, —З—В–Њ–±—Л –Ј–∞–љ—П—В—М—Б—П –і—А–∞–є–≤–µ—А–Њ–Љ, –љ–µ –љ—Г–ґ–љ–Њ –≤–Њ–Њ–±—Й–µ –≤—Б—В–∞–≤–∞—В—М –Є–Ј-–Ј–∞ —Б—В–Њ–ї–∞ вАФ –≤—Б–µ –Є–љ—Б—В—А—Г–Љ–µ–љ—В—Л –њ–Њ–і —А—Г–Ї–Њ–є.
–Я–Њ–і—Е–Њ–і –±—Л–ї –њ—А–Њ—Б—В—Л–Љ: –њ—Л—В–∞—В—М—Б—П –њ–µ—З–∞—В–∞—В—М (—Е–Њ—В—М –Є–Ј –С–ї–Њ–Ї–љ–Њ—В–∞) –Є –Њ—В–ї–∞–і—З–Є–Ї–Њ–Љ —Б–Љ–Њ—В—А–µ—В—М, —З—В–Њ –≤—Л–Ј—Л–≤–∞–µ—В –њ–∞–і–µ–љ–Є–µ. –Ф—А–∞–є–≤–µ—А-—В–Њ –љ–µ —П–і–µ—А–љ—Л–є, –∞ —О–Ј–µ—А–Љ–Њ–і–љ—Л–є, —В–∞–Ї —З—В–Њ –≤—Б—С –≤–Њ–Њ–±—Й–µ –ї–µ–≥–Ї–Њ. –Ф–∞ –Є –±—Л–ї–Њ –њ–Њ–љ–Є–Љ–∞–љ–Є–µ, —З—В–Њ —Б –≤—Л—Б–Њ–Ї–Њ–є —Б—В–µ–њ–µ–љ—М—О –≤–µ—А–Њ—П—В–љ–Њ—Б—В–Є –≤—Б—С –ї–µ—З–µ–љ–Є–µ –±—Г–і–µ—В —Б—Г–њ–µ—А-—В—А–Є–≤–Є–∞–ї—М–љ—Л–Љ: —З—В–Њ —Б–Ї–Њ—А–µ–µ –≤—Б–µ–≥–Њ —П –љ–∞—В–Ї–љ—Г—Б—М –љ–∞ –≤—Л–Ј–Њ–≤
VirtualAlloc/
HeapAlloc, –њ—А–Є –Ї–Њ—В–Њ—А–Њ–Љ –њ–∞–Љ—П—В—М –≤—Л–і–µ–ї—П–µ—В—Б—П –±–µ–Ј X-–∞—В—А–Є–±—Г—В–∞. –°—В–Њ–Є–ї–Њ –±—Л —З—Г—В—М-—З—Г—В—М –њ–Њ–і–њ—А–∞–≤–Є—В—М –≤—Л–Ј–Њ–≤ –≤—Л–і–µ–ї—П—О—Й–µ–є —Д—Г–љ–Ї—Ж–Є–Є –Є –≤—Б—С –±—Л –Ј–∞—А–∞–±–Њ—В–∞–ї–Њ.
–Ґ–∞–Ї–Њ–є —Д–Є–Ї—Б –Ј–∞–Ї–ї—О—З–∞–ї—Б—П –±—Л –≤ –њ—А–∞–≤–Ї–µ –Њ–і–љ–Њ–≥–Њ –µ–і–Є–љ—Б—В–≤–µ–љ–љ–Њ–≥–Њ –±–∞–є—В–∞ –≤ —Д–∞–є–ї–µ! –Ю—З–µ–љ—М –Ј–∞–Љ–∞–љ—З–Є–≤–∞—П –њ–µ—А—Б–њ–µ–Ї—В–Є–≤–∞!
–Ш—В–∞–Ї, —П –њ–Њ–≥—А—Г–Ј–Є–ї—Б—П –≤ –Њ—В–ї–∞–і–Ї—Г. –°—В–Њ–Є–ї–Њ –Њ—В–њ—А–∞–≤–Є—В—М –∞–±—А–∞–Ї–∞–і–∞–±—А—Г –Є–Ј –С–ї–Њ–Ї–љ–Њ—В–∞ –љ–∞ –њ–µ—З–∞—В—М, –Ї–∞–Ї –С–ї–Њ–Ї–љ–Њ—В –≤—Л–ї–µ—В–µ–ї, –Є —П –њ–Њ–і–Ї–ї—О—З–Є–ї—Б—П –Ї –љ–µ–Љ—Г –Њ—В–ї–∞–і—З–Є–Ї–Њ–Љ (OllyDbg).
–Т–Њ—В –Є—Б–Ї–ї—О—З–µ–љ–Є–µ –Є –Љ–µ—Б—В–Њ, –≥–і–µ –Њ–љ–Њ –≤–Њ–Ј–љ–Є–Ї–ї–Њ:
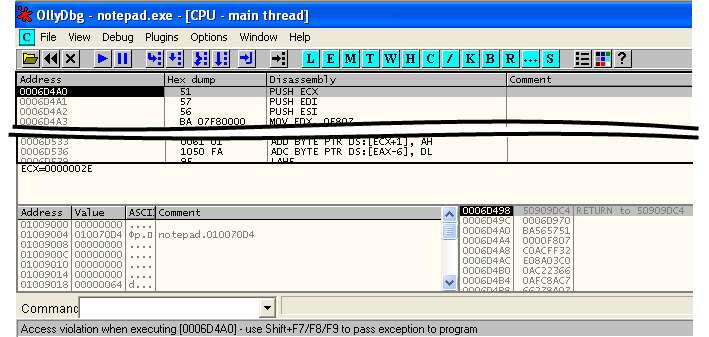
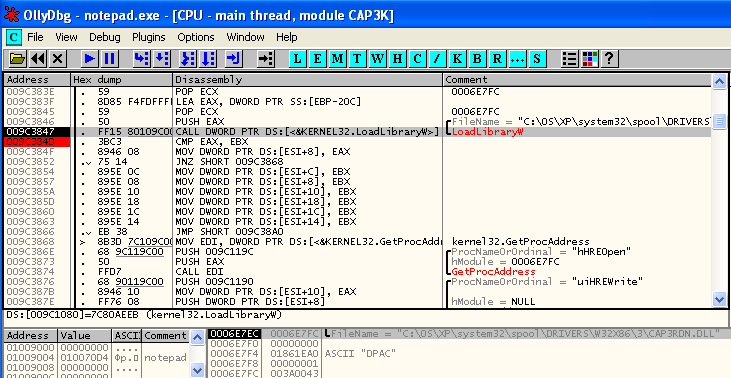
–Ъ–∞–Ї –Є —Б–ї–µ–і–Њ–≤–∞–ї–Њ –Њ–ґ–Є–і–∞—В—М, –±—Л–ї –Њ—Б—Г—Й–µ—Б—В–≤–ї—С–љ –њ–µ—А–µ—Е–Њ–і –љ–∞ –∞–і—А–µ—Б
0x0006D4A0, –Ї–Њ—В–Њ—А—Л–є –њ—А–Є–љ–∞–і–ї–µ–ґ–Є—В —Б—В—А–∞–љ–Є—Ж–µ, –Є–Љ–µ—О—Й–µ–є
RW- –Є–ї–Є
R-- –∞—В—А–Є–±—Г—В—Л, —В–Њ –µ—Б—В—М –±–µ–Ј X-—Д–ї–∞–≥–∞. –≠—В–Њ –Є –≤—Л–Ј—Л–≤–∞–µ—В —Б—А–∞–±–∞—В—Л–≤–∞–љ–Є–µ DEP –Є –Є—Б–Ї–ї—О—З–µ–љ–Є–µ –Ї–∞–Ї –Є—В–Њ–≥.
–Т –Ј–∞–≥–Њ–ї–Њ–≤–Ї–µ –Њ—В–ї–∞–і—З–Є–Ї–∞ –љ–∞–њ–Є—Б–∞–љ–Њ —В–Њ–ї—М–Ї–Њ ¬ЂMain thread¬ї –Є –љ–µ —Б–Њ–і–µ—А–ґ–Є—В—Б—П —Г–њ–Њ–Љ–Є–љ–∞–љ–Є–µ –Љ–Њ–і—Г–ї—П, —З—В–Њ –≥–Њ–≤–Њ—А–Є—В –Њ —В–Њ–Љ, —З—В–Њ —В–µ–Ї—Г—Й–Є–є —Д—А–∞–≥–Љ–µ–љ—В –Ї–Њ–і–∞ –љ–µ –Њ—В–љ–Њ—Б–Є—В—Б—П –Ї –Ї–∞–Ї–Њ–Љ—Г-–ї–Є–±–Њ –Ј–∞–≥—А—Г–ґ–µ–љ–љ–Њ–Љ—Г –Љ–Њ–і—Г–ї—О (EXE –Є–ї–Є DLL). –Э–∞–ґ–Є–Љ–∞–µ–Љ Ctrl+A (–Ї–Њ–Љ–∞–љ–і–∞ Analyze) –Є –≤–Є–і–Є–Љ, —З—В–Њ –љ–Є—З–µ–≥–Њ –љ–µ –Љ–µ–љ—П–µ—В—Б—П, —З—В–Њ —В–Њ–ї—М–Ї–Њ –њ–Њ–і—В–≤–µ—А–ґ–і–∞–µ—В, —З—В–Њ –Љ—Л –≤–Є–і–Є–Љ –Ї–Њ–і, —А–∞–Ј–Љ–µ—Й—С–љ–љ—Л–є –≤ –њ–∞–Љ—П—В–Є ¬Ђ–љ–∞ –њ—А–∞–≤–∞—Е¬ї –і–∞–љ–љ—Л—Е.
–Э–∞—И–∞ –Ї–Њ–љ–µ—З–љ–∞—П —Ж–µ–ї—М вАФ –љ–∞–є—В–Є –Љ–µ—Б—В–Њ, –≥–і–µ –≤—Л–і–µ–ї—П–µ—В—Б—П —Д—А–∞–≥–Љ–µ–љ—В –њ–∞–Љ—П—В–Є, –≤ –Ї–Њ—В–Њ—А—Л–є –Ј–∞—В–µ–Љ –Ї–Њ–њ–Є—А—Г–µ—В—Б—П –Ї–Њ–і, —З–∞—Б—В—М—О –Ї–Њ—В–Њ—А–Њ–≥–Њ —П–≤–ї—П–µ—В—Б—П –Є–љ—Б—В—А—Г–Ї—Ж–Є—П –њ–Њ –∞–і—А–µ—Б—Г
0x0006D4A0, –љ–∞ –Ї–Њ—В–Њ—А—Г—О –њ–Њ—В–Њ–Љ –≤–њ–Њ—Б–ї–µ–і—Б—В–≤–Є–Є –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –њ–µ—А–µ—Е–Њ–і, –Ї–Њ—В–Њ—А—Л–є –≤—Б—С —А—Г—И–Є—В. –Ф–Њ–±—А–∞—В—М—Б—П –і–Њ —Н—В–Њ–≥–Њ –Љ–µ—Б—В–∞ –њ—А–Њ—Й–µ –≤—Б–µ–≥–Њ –і–≤–Є–≥–∞—П—Б—М –≤ –Њ–±—А–∞—В–љ–Њ–Љ –њ–Њ—А—П–і–Ї–µ.
–Ґ–Њ –µ—Б—В—М –≤ –њ–µ—А–≤—Г—О –Њ—З–µ—А–µ–і—М –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ –≤—Л—П—Б–љ–Є—В—М,
–Њ—В–Ї—Г–і–∞ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –њ–µ—А–µ—Е–Њ–і –љ–∞ –∞–і—А–µ—Б
0x0006D4A0. –Я–µ—А–µ—Е–Њ–і –Љ–Њ–≥ –±—Л—В—М –Њ—Б—Г—Й–µ—Б—В–≤–ї—С–љ –Є–љ—Б—В—А—Г–Ї—Ж–Є–µ–є
JMP (–Є–ї–Є —Г—Б–ї–Њ–≤–љ—Л–Љ –і–ґ–∞–Љ–њ–Њ–Љ), –Є –≤ —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ –љ–∞–є—В–Є –Љ–µ—Б—В–Њ, –Њ—В–Ї—Г–і–∞ –±—Л–ї —Б–і–µ–ї–∞–љ –њ–µ—А–µ—Е–Њ–і, –Љ–Њ–ґ–љ–Њ —В–Њ–ї—М–Ї–Њ –њ–Њ—И–∞–≥–Њ–≤–Њ–є —В—А–∞—Б—Б–Є—А–Њ–≤–Ї–Њ–є, –ї–Є–±–Њ –Є–љ—Б—В—А—Г–Ї—Ж–Є–µ–є
CALL, –Є —В–Њ–≥–і–∞ –Љ–µ—Б—В–Њ, –Њ—В–Ї—Г–і–∞ –±—Л–ї —Б–і–µ–ї–∞–љ –њ–µ—А–µ—Е–Њ–і, –Љ–Њ–ґ–љ–Њ –≤—Л—З–Є—Б–ї–Є—В—М –њ–Њ –∞–і—А–µ—Б—Г –≤–Њ–Ј–≤—А–∞—В–∞, –Ї–Њ—В–Њ—А—Л–є –≤ –і–∞–љ–љ—Л–є –Љ–Њ–Љ–µ–љ—В –ї–µ–ґ–Є—В –љ–∞ –≤–µ—А—Е—Г—И–Ї–µ —Б—В–µ–Ї–∞.
–Т—Л—П—Б–љ–Є—В—М, –Ї–∞–Ї–Њ–є –≤–∞—А–Є–∞–љ—В –Є–Ј –і–≤—Г—Е вАФ –њ—А–∞–≤–Є–ї—М–љ—Л–є, –Љ–Њ–ґ–љ–Њ —В–Њ–ї—М–Ї–Њ –њ—А–Њ–≤–µ—А–Є–≤ –≤—В–Њ—А–Њ–є. –Х—Б–ї–Є –Њ–љ –Њ–Ї–∞–ґ–µ—В—Б—П –љ–µ–≤–µ—А–љ—Л–Љ, –Ј–љ–∞—З–Є—В –≤–µ—А–љ—Л–є вАФ –њ–µ—А–≤—Л–є.
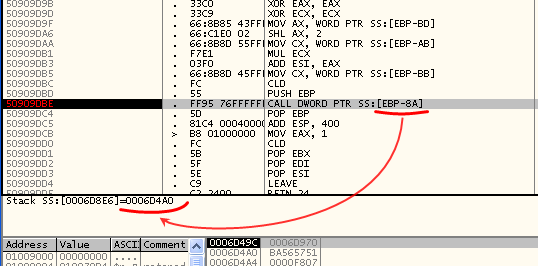
–Э–µ –≤–µ—А—Е—Г—И–Ї–µ —Б—В–µ–Ї–∞ –ї–µ–ґ–Є—В DWORD
0x50909DC4 —Б –њ–Њ–Љ–µ—В–Ї–Њ–є –Њ—В –Њ—В–ї–∞–і—З–Є–Ї–∞ ¬ЂRETURN to 50909DC4¬ї. –°—Г–і—П –њ–Њ –Њ—В—Б—Г—В—Б—В–≤–Є—О –≤ —Н—В–Њ–є –њ–Њ–Љ–µ—В–Ї–µ –љ–∞–Ј–≤–∞–љ–Є—П –Љ–Њ–і—Г–ї—П, –∞–і—А–µ—Б
0x50909DC4 –≤–µ—А–Њ—П—В–љ–Њ —В–Њ–ґ–µ –љ–µ –њ—А–Є–љ–∞–і–ї–µ–ґ–Є—В –Ї–∞–Ї–Њ–Љ—Г-–ї–Є–±–Њ –Љ–Њ–і—Г–ї—О. –Я—А–Є –њ–Њ–њ—Л—В–Ї–µ –Ї–ї–Є–Ї–љ—Г—В—М –њ–Њ —Н—В–Њ–Љ—Г DWORD-—Г –њ—А–∞–≤–Њ–є –Ї–љ–Њ–њ–Ї–Њ–є –Є –њ–Њ—Б–Љ–Њ—В—А–µ—В—М –Ї–Њ–і –њ–Њ —Н—В–Њ–Љ—Г –∞–і—А–µ—Б—Г –Љ—Л –≤–Є–і–Є–Љ, —З—В–Њ –≤ –Љ–µ–љ—О –љ–µ—В –њ—Г–љ–Ї—В–∞ ¬ЂFollow in Disassembler¬ї. –Х—Б—В—М —В–Њ–ї—М–Ї–Њ ¬ЂFollow in Dump¬ї. –Ч–љ–∞—З–Є—В –Њ—В–ї–∞–і—З–Є–Ї –љ–µ –њ—А–µ–і–њ–Њ–ї–∞–≥–∞–µ—В, —З—В–Њ –њ–Њ –∞–і—А–µ—Б—Г
0x50909DC4 –Љ–Њ–ґ–µ—В –±—Л—В—М –Ї–∞–Ї–Њ–є-—В–Њ –Ї–Њ–і.
–Э–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ, —Н—В–Њ –µ—Й—С –љ–Є—З–µ–≥–Њ –љ–µ –Њ–Ј–љ–∞—З–∞–µ—В. –ѓ –≤—Б—С —А–∞–≤–љ–Њ –њ–µ—А–µ—Е–Њ–ґ—Г –љ–∞ —Н—В–Њ—В –∞–і—А–µ—Б –Є—Б–њ–Њ–ї—М–Ј—Г—П –Ї–Њ–Љ–∞–љ–і—Г
at dword[esp] –≤ –Ї–Њ–Љ–∞–љ–і–љ–Њ–є —Б—В—А–Њ–Ї–µ –Њ—В–ї–∞–і—З–Є–Ї–∞, –Є –≤–Њ—В —З—В–Њ —В–∞–Љ –Ј–∞ –Ї–Њ–і:
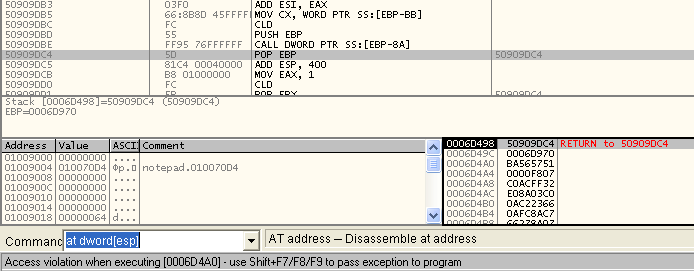
–Т—Л–≥–ї—П–і–Є—В –Ї–∞–Ї –≤–њ–Њ–ї–љ–µ –љ–Њ—А–Љ–∞–ї—М–љ—Л–є –Ї–Њ–і, –≤–њ–Њ–ї–љ–µ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ, —З—В–Њ –Є–љ—Б—В—А—Г–Ї—Ж–Є—П
call dword[ebp-8a] –Ї–∞–Ї —А–∞–Ј –Є –њ–µ—А–µ–і–∞–ї–∞ —Г–њ—А–∞–≤–ї–µ–љ–Є–µ –љ–∞ –∞–і—А–µ—Б
0x0006D4A0 (–њ–Њ –Ї–Њ—В–Њ—А–Њ–Љ—Г –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –Є—Б–Ї–ї—О—З–µ–љ–Є–µ). –°—В–∞–≤–Є–Љ –±—А–µ–Ї–њ–Њ–Є–љ—В –љ–∞ —Н—В–Њ–є –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є, —З—В–Њ–±—Л —Г–±–µ–і–Є—В—М—Б—П, —З—В–Њ –Є–Љ–µ–љ–љ–Њ –Њ–љ–∞ –њ–µ—А–µ–і–∞—С—В —Г–њ—А–∞–≤–ї–µ–љ–Є–µ –љ–∞ –∞–і—А–µ—Б
0x0006D4A0.
–°—В–∞–≤–Є–Љ –Є –њ–µ—А–µ–Ј–∞–њ—Г—Б–Ї–∞–µ–Љ –њ—А–Њ—Ж–µ—Б—Б.
–Э–Њ –њ–Њ—Б–ї–µ –њ–Њ–≤—В–Њ—А–љ–Њ–≥–Њ –њ—А–Њ–≥–Њ–љ–∞ –Њ—В–ї–∞–і—З–Є–Ї –љ–µ –Њ—Б—В–∞–љ–∞–≤–ї–Є–≤–∞–µ—В—Б—П –љ–∞ –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є CALL, –∞ –Њ—Б—В–∞–љ–∞–≤–ї–Є–≤–∞–µ—В—Б—П –Њ–њ—П—В—М –љ–∞ –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є –њ–Њ –∞–і—А–µ—Б—Г
0x0006D4A0, —Б –Ї–Њ—В–Њ—А–Њ–є –Љ—Л –љ–∞—З–∞–ї–Є –љ–∞—И –њ–Њ–Є—Б–Ї.
–Ч–љ–∞—З–Є—В –ї–Є —Н—В–Њ, —З—В–Њ –њ–µ—А–µ—Е–Њ–і –љ–∞
0006D4A0 –і–µ–ї–∞–µ—В—Б—П –љ–µ –Є–љ—Б—В—А—Г–Ї—Ж–Є–µ–є CALL –њ–Њ –∞–і—А–µ—Б—Г
50909DBE, –∞ –Ї–∞–Ї–Њ–є-—В–Њ –і—А—Г–≥–Њ–є –Є–љ—Б—В—А—Г–Ї—Ж–Є–µ–є, –∞ —З–Є—Б–ї–Њ –љ–∞ –≤–µ—А—Е—Г—И–Ї–µ —Б—В–µ–Ї–∞ вАФ —Н—В–Њ —З–Є—Б—В–∞—П —Б–ї—Г—З–∞–є–љ–Њ—Б—В—М? –Т–µ–і—М –њ–µ—А–µ–і –њ–Њ–њ–∞–і–∞–љ–Є–µ–Љ –љ–∞
0006D4A0 –Љ—Л –љ–µ —Б—В–Њ–њ–љ—Г–ї–Є—Б—М –љ–∞
50909DBE?
–Э–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ вАФ –Ї–Њ–љ–µ—З–љ–Њ –љ–µ—В! –Ф–ї—П —Г—Б–њ–µ—И–љ–Њ–є –Њ—В–ї–∞–і–Ї–Є –љ–∞–і–Њ –љ–µ —В–Њ–ї—М–Ї–Њ –Ј–љ–∞—В—М —Д–Є—З–Є –Є –Є–љ—Б—В—А—Г–Љ–µ–љ—В—Л –Њ—В–ї–∞–і—З–Є–Ї–∞, –љ–Њ –Є –њ–Њ–љ–Є–Љ–∞—В—М, –Ї–∞–Ї –Њ–љ–Є —Г—Б—В—А–Њ–µ–љ—Л –Є —А–∞–±–Њ—В–∞—О—В. –Ю–±—Л—З–љ—Л–µ –±—А–µ–Ї–њ–Њ–Є–љ—В—Л (—В–Њ—З–Ї–Є –Њ—Б—В–∞–љ–Њ–≤–∞) –≤ OllyDbg (–Є –±–Њ–ї—М—И–Є–љ—Б—В–≤–µ –і—А—Г–≥–Є—Е –Њ—В–ї–∞–і—З–Є–Ї–Њ–≤) —Г—Б—В—А–Њ–µ–љ—Л —В–∞–Ї: –њ—А–Є —Г—Б—В–∞–љ–Њ–≤–Ї–µ –±—А–µ–Ї–њ–Њ–Є–љ—В–∞ –љ–∞ –Є–љ—Б—В—А—Г–Ї—Ж–Є—О –Њ—В–ї–∞–і—З–Є–Ї –њ–µ—А–µ–Ј–∞–њ–Є—Б—Л–≤–∞–µ—В –њ–µ—А–≤—Л–є –±–∞–є—В –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є, –Љ–µ–љ—П—П –µ–≥–Њ –љ–∞
0xCC, —З—В–Њ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є
INT3.
INT3 —Н—В–Њ —Б–њ–µ—Ж–Є–∞–ї—М–љ–∞—П –Ї–Њ—А–Њ—В–Ї–∞—П (–Њ–і–љ–Њ–±–∞–є—В–Њ–≤–∞—П) —Д–Њ—А–Љ–∞ –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є
INT xx (–Ї–Њ–і–Є—А—Г–µ–Љ–Њ–є –Ї–∞–Ї
CD xx вАФ –≤ —Б–ї—Г—З–∞–µ int 3 —Н—В–Њ –±—Г–і–µ—В –њ–∞—А–∞ –±–∞–є—В–Њ–≤
CD 03), –Ї–Њ—В–Њ—А–∞—П –≤–Њ–Ј–±—Г–ґ–і–∞–µ—В –Њ—В–ї–∞–і–Њ—З–љ–Њ–µ –њ—А–µ—А—Л–≤–∞–љ–Є–µ, –Ї–Њ—В–Њ—А–Њ–µ —П–і—А–Њ–Љ Windows —В—А–∞–љ—Б—Д–Њ—А–Љ–Є—А—Г–µ—В—Б—П –≤ –Њ—В–ї–∞–і–Њ—З–љ–Њ–µ –Є—Б–Ї–ї—О—З–µ–љ–Є–µ, –Ї–Њ—В–Њ—А–Њ–µ –Њ—Б—В–∞–љ–∞–≤–ї–Є–≤–∞–µ—В –≤—Л–њ–Њ–ї–љ–µ–љ–Є–µ –Њ—В–ї–∞–ґ–Є–≤–∞–µ–Љ–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ –Є –њ–µ—А–µ–і–∞—С—В —Г–њ—А–∞–≤–ї–µ–љ–Є–µ –Њ—В–ї–∞–і—З–Є–Ї—Г. –Ю—В–ї–∞–і—З–Є–Ї –≤ —Н—В–Њ—В –Љ–Њ–Љ–µ–љ—В –≤–Њ—Б—Б—В–∞–љ–∞–≤–ї–Є–≤–∞–µ—В –њ–µ—А–≤—Л–є –±–∞–є—В –Љ–Њ–і–Є—Д–Є—Ж–Є—А–Њ–≤–∞–љ–љ–Њ–є –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є –Є –Њ—Б—В–∞–≤–ї—П–µ—В –Ј–∞ –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–Љ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –і–µ–є—Б—В–≤–Њ–≤–∞—В—М. –Х—Б–ї–Є –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М —А–µ—И–∞–µ—В –њ—А–Њ–і–Њ–ї–ґ–Є—В—М –≤—Л–њ–Њ–ї–љ–µ–љ–Є–Є, –њ–µ—А–≤—Л–є –±–∞–є—В –Њ–њ—П—В—М –Ј–∞–Љ–µ–љ—П–µ—В—Б—П –љ–∞
CC. –Ф–ї—П –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—П –Њ—В–ї–∞–і—З–Є–Ї–∞ –Љ–µ—Е–∞–љ–Є–Ј–Љ –±—А–µ–Ї–њ–Њ–Є–љ—В–Њ–≤ –Ї–∞–ґ–µ—В—Б—П –њ—А–Њ–Ј—А–∞—З–љ—Л–Љ, –љ–Њ –љ–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ (–њ–Њ–і –Ї–∞–њ–Њ—В–Њ–Љ) –Ї–∞–ґ–і—Л–є –±—А–µ–Ї–њ–Њ–Є–љ—В вАФ —Н—В–Њ –≤–љ–µ—Б—С–љ–љ–∞—П –Њ—В–ї–∞–і—З–Є–Ї–Њ–Љ –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є—П –≤ –Њ—В–ї–∞–ґ–Є–≤–∞–µ–Љ—Л–є –Ї–Њ–і (–Ї–Њ—В–Њ—А–∞—П –Њ—В–Љ–µ–љ—П–µ—В—Б—П –љ–∞ –≤—А–µ–Љ –њ–∞—Г–Ј –≤ –Њ—В–ї–∞–і—З–Є–Ї–µ –Є –і–µ–ї–∞–µ—В—Б—П –≤–љ–Њ–≤—М –њ—А–Є –њ—А–Њ–і–Њ–ї–ґ–µ–љ–Є–Є –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Њ—В–ї–∞–ґ–Є–≤–∞–µ–Љ–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞).
–Ш–Ј-–Ј–∞ —В–∞–Ї–Њ–≥–Њ –њ—А–Є–љ—Ж–Є–њ–∞ —Г—Б—В—А–Њ–є—Б—В–≤–∞ –±—А–µ–Ї–њ–Њ–Є–љ—В–Њ–≤ –љ–∞–і–Њ –њ–Њ–љ–Є–Љ–∞—В—М, —З—В–Њ –±—А–µ–Ї–њ–Њ–Є–љ—В –љ–µ —Б—А–∞–±–Њ—В–∞–µ—В, –µ—Б–ї–Є –Њ—В–ї–∞–ґ–Є–≤–∞–µ–Љ—Л–є –њ—А–Њ—Ж–µ—Б—Б —Б–∞–Љ –њ–µ—А–µ–Ј–∞–њ–Є—Б—Л–≤–∞–µ—В –Ї–Њ–і –≤ —Б–≤–Њ—С–Љ –Р–Я, –њ–Њ—Б–ї–µ —В–Њ–≥–Њ, –Ї–∞–Ї –±—А–µ–Ї–њ–Њ–Є–љ—В —Г—Б—В–∞–љ–Њ–≤–ї–µ–љ. –Ґ–Њ—З–љ–Њ —В–∞–Ї –ґ–µ –±—А–µ–Ї–њ–Њ–Є–љ—В –љ–µ —Б—А–∞–±–Њ—В–∞–µ—В, –µ—Б–ї–Є –Њ–љ —Г—Б—В–∞–љ–Њ–≤–ї–µ–љ –љ–∞ –Ї–Њ–і–µ, –Ї–Њ—В–Њ—А—Л–є –±—Л–ї –≤—Л–≥—А—Г–ґ–µ–љ, –∞ –њ–Њ—В–Њ–Љ –≤–љ–Њ–≤—М –Ј–∞–≥—А—Г–ґ–µ–љ –њ–Њ —В–Њ–Љ—Г –ґ–µ –∞–і—А–µ—Б—Г (–Є –Њ—В–ї–∞–і—З–Є–Ї –Њ–± —Н—В–Њ–Љ –љ–µ –≤ –Ї—Г—А—Б–µ).
OllyDbg –њ—А–Є –Ј–∞–≤–µ—А—И–µ–љ–Є–Є –Њ—В–ї–∞–і–Ї–Є —Б–Њ—Е—А–∞–љ—П–µ—В —Б–њ–Є—Б–Њ–Ї –≤—Б–µ—Е —Г—Б—В–∞–љ–Њ–≤–ї–µ–љ–љ—Л—Е –±—А–µ–Ї–њ–Њ–Є–љ—В–Њ–≤ –Є –≤ —Б–ї–µ–і—Г—О—Й–Є–є —А–∞–Ј –њ—А–Є –њ–Њ–і–Ї–ї—О—З–µ–љ–Є–Є –Ї –Њ—В–ї–∞–ґ–Є–≤–∞–µ–Љ–Њ–Љ—Г –њ—А–Њ—Ж–µ—Б—Б—Г —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞–µ—В —Н—В–Є –±—А–µ–Ї–њ–Њ–Є–љ—В—Л –≤–љ–Њ–≤—М. –Ю–і–љ–∞–Ї–Њ, –µ—Б–ї–Є –≤ –Љ–Њ–Љ–µ–љ—В –њ–Њ–і–Ї–ї—О—З–µ–љ–Є—П –Ї –Њ—В–ї–∞–ґ–Є–≤–∞–µ–Љ–Њ–Љ—Г –њ—А–Њ—Ж–µ—Б—Б—Г –Є–ї–Є –Ј–∞–њ—Г—Б–Ї—Г –њ—А–Њ—Ж–µ—Б—Б–∞ —Б –љ—Г–ї—П –њ–Њ–і –Њ—В–ї–∞–і—З–Є–Ї–Њ–Љ, –µ—Б–ї–Є –њ–Њ –љ—Г–ґ–љ–Њ–Љ—Г –∞–і—А–µ—Б—Г –≤ –њ–∞–Љ—П—В–Є –≤ –њ—А–Є–љ—Ж–Є–њ–µ –љ–Є—З–µ–≥–Њ –љ–µ—В, OllyDbg –≤ –њ—А–Є–љ—Ж–Є–њ–µ –љ–µ –Љ–Њ–ґ–µ—В —Г—Б—В–∞–љ–Њ–≤–Є—В—М —В–∞–Љ –±—А–µ–Ї–њ–Њ–Є–љ—В—Л (–њ–Њ—В–Њ–Љ—Г —З—В–Њ —Г—Б—В–∞–љ–Њ–≤–Ї–∞ –µ–≥–Њ –µ—Б—В—М –Ј–∞–њ–Є—Б—М –±–∞–є—В–∞
CC, –∞ –љ–µ–ї—М–Ј—П –Ј–∞–њ–Є—Б—Л–≤–∞—В—М —З—В–Њ-—В–Њ –≤
–љ–µ–≤—Л–і–µ–ї–µ–љ–љ—Г—О –њ–∞–Љ—П—В—М).
–Т –љ–∞—И–µ–Љ —Б–ї—Г—З–∞–µ —Б–ї—Г—З–∞–µ –њ–Њ—Б–ї–µ –њ–µ—А–µ–Ј–∞–њ—Г—Б–Ї–∞ –С–ї–Њ–Ї–љ–Њ—В–∞ –њ–Њ–і –Њ—В–ї–∞–і–Ї–Њ–є –њ–Њ –∞–і—А–µ—Б—Г
50909DBE –љ–µ—В –∞–±—Б–Њ–ї—О—В–љ–Њ –љ–Є—З–µ–≥–Њ, –њ–Њ—Н—В–Њ–Љ—Г OllyDbg –Є –љ–µ –Љ–Њ–ґ–µ—В —Г—Б—В–∞–љ–Њ–≤–Є—В—М —В–∞–Љ –±—А–µ–Ї–њ–Њ–Є–љ—В. –Р –Љ–Њ–Љ–µ–љ—В, –Ї–Њ–≥–і–∞ –њ–Њ —Н—В–Њ–Љ—Г –∞–і—А–µ—Б—Г –њ–Њ—П–≤–ї—П–µ—В—Б—П –Ї–∞–Ї–Њ–є-—В–Њ –Ї–Њ–і (–≤ –Ї–Њ—В–Њ—А–Њ–Љ –љ—Г–ґ–љ–Њ –њ–Њ–њ—А–∞–≤–Є—В—М 1 –±–∞–є—В, —З—В–Њ–±—Л –љ–∞ –љ—С–Љ —Б—В–Њ–њ–∞–ї–Њ—Б—М –≤—Л–њ–Њ–ї–љ–µ–љ–Є–µ), –Њ—В–ї–∞–і—З–Є–Ї –Њ—В–ї–Њ–≤–Є—В—М –љ–µ –Љ–Њ–ґ–µ—В (—Е–Њ—В—П –Є –Љ–Њ–≥ –±—Л –њ—А–Є –і–Њ–ї–ґ–љ–Њ–Љ —Б—В–∞—А–∞–љ–Є–Є –∞–≤—В–Њ—А–∞ OllyDbg).
–Ф–µ–ї–Њ –≤ —В–Њ–Љ, —З—В–Њ –Ї–∞–Ї –Њ–±—Л—З–љ–Њ–µ –Њ–Ї–Њ–љ–љ–Њ–µ –њ—А–Є–ї–Њ–ґ–µ–љ–Є–µ –Њ–ґ–Є–і–∞–µ—В –≤ —Ж–Є–Ї–ї–µ –њ—А–Є—Е–Њ–і–∞ –љ–Њ–≤—Л—Е –Њ–Ї–Њ–љ–љ—Л—Е —Б–Њ–Њ–±—Й–µ–љ–Є–є, –Є –Њ–±—Л—З–љ–Њ –љ–µ –і–µ–ї–∞–µ—В –∞–±—Б–Њ–ї—О—В–љ–Њ –љ–Є—З–µ–≥–Њ (–њ–Њ–Ї–∞ –љ–Њ–≤—Л—Е —Б–Њ–Њ–±—Й–µ–љ–Є–є –љ–µ—В), –∞ —В—Г–њ–Њ —Б–њ–Є—В –Є –љ–µ –≤—Л–њ–Њ–ї–љ—П–µ—В—Б—П, —В–Њ—З–љ–Њ —В–∞–Ї –ґ–µ –Њ—В–ї–∞–і—З–Є–Ї –≤ —Ж–Є–Ї–ї–µ
–ґ–і—С—В –Њ—В–ї–∞–і–Њ—З–љ—Л—Е —Б–Њ–±—Л—В–Є–є (debug events), –Є –њ–Њ–Ї–∞ –Њ—В–ї–∞–ґ–Є–≤–∞–µ–Љ—Л–є –њ—А–Њ—Ж–µ—Б—Б –≤—Л–њ–Њ–ї–љ—П–µ—В—Б—П –±–µ–Ј –Є—Б–Ї–ї—О—З–µ–љ–Є–є –Є –њ–∞—Г–Ј, –Њ—В–ї–∞–і—З–Є–Ї –љ–µ –њ–Њ–ї—Г—З–∞–µ—В —И–∞–љ—Б–∞, —З—В–Њ–±—Л –µ–≥–Њ –Ї–Њ–і –≤—Л–њ–Њ–ї–љ–Є–ї—Б—П. –Э–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ, –њ—А–Є –ґ–µ–ї–∞–љ–Є–Є –∞–≤—В–Њ—А–∞, –Њ—В–ї–∞–і—З–Є–Ї –Љ–Њ–ґ–µ—В –≤—Л–њ–Њ–ї–љ—П—В—М –Ї–∞–Ї–Є–µ-—В–Њ –і–µ–є—Б—В–≤–Є—П –≤ —Д–Њ–љ–µ –Є –±–µ–Ј –≤—Б—П–Ї–Є—Е –Њ—В–ї–∞–і–Њ—З–љ—Л—Е —Б–Њ–±—Л—В–Є–є (–Ї–∞–Ї –Љ–Є–љ–Є–Љ—Г–Љ GUI-–Њ—В–ї–∞–і—З–Є–Ї–Є –Њ–±—А–∞–±–∞—В—Л–≤–∞—О—В –Њ–Ї–Њ–љ–љ—Л–µ —Б–Њ–Њ–±—Й–µ–љ–Є—П), –љ–Њ –∞–≤—В–Њ—А OllyDbg –љ–µ —Б—В–∞–ї –і–µ–ї–∞—В—М –Љ–µ—Е–∞–љ–Є–Ј–Љ, –Ї–Њ—В–Њ—А—Л–є –±—Л –≤ —Д–Њ–љ–µ –њ—А–Њ–≤–µ—А—П–ї –њ–Њ—П–≤–ї–µ–љ–Є–µ –≤ –њ–∞–Љ—П—В–Є –љ–Њ–≤—Л—Е —Д—А–∞–≥–Љ–µ–љ—В–Њ–≤, –љ–∞ –Ї–Њ—В–Њ—А—Л–µ –±—Л –њ—А–Є—Е–Њ–і–Є–ї–Є—Б—М —А–∞–љ–µ–µ —Г—Б—В–∞–љ–Њ–≤–ї–µ–љ–љ—Л–µ –Ј–∞–њ–Њ–Љ–љ–µ–љ–љ—Л–µ –±—А–µ–Ї–њ–Њ–Є–љ—В—Л, –Є –Є—Е –њ–µ—А–µ—Г—Б—В–∞–љ–Њ–≤–Ї—Г –њ—Г—В—С–Љ –њ–Њ–і–Љ–µ–љ—Л –њ–µ—А–≤–Њ–≥–Њ –±–∞–є—В–∞ –Є–љ—Б—В—А—Г–Ї—Ж–Є–є –љ–∞
CC (—Е–Њ—В—П, –±–µ–Ј—Г—Б–ї–Њ–≤–љ–Њ, –Љ–Њ–≥).
–Я–Њ—Н—В–Њ–Љ—Г –љ–∞—И –±—А–µ–Ї–њ–Њ–Є–љ—В –њ–Њ –∞–і—А–µ—Б—Г
50909DBE –љ–µ —Б—А–∞–±–∞—В–∞–ї –≤ –њ–µ—А–≤—Г—О –Њ—З–µ—А–µ–і—М –Є–Ј-–Ј–∞ —В–Њ–≥–Њ, —З—В–Њ OllyDbg —В—Г–њ–Њ –њ—А–Њ–Ј–µ–≤–∞–ї –Љ–Њ–Љ–µ–љ—В, –Ї–Њ–≥–і–∞ –њ–Њ —Н—В–Њ–Љ—Г –∞–і—А–µ—Б—Г –њ–µ—А–µ—Б—В–∞–ї–∞ –±—Л—В—М –∞–±—Б–Њ–ї—О—В–љ–∞—П –њ—Г—Б—В–Њ—В–∞, –∞ –њ–Њ—П–≤–Є–ї—Б—П –Ї–∞–Ї–Њ–є-—В–Њ –Ї–Њ–і. –Я—А–Њ–Ј–µ–≤–∞–ї –Љ–Њ–Љ–µ–љ—В, –Ї–Њ–≥–і–∞ –µ–Љ—Г –љ—Г–ґ–љ–Њ –±—Л–ї–Њ –њ–Њ–і–Љ–µ–љ–Є—В—М –њ–µ—А–≤—Л–є –±–∞–є—В –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є –Є –љ–Є—З–µ–≥–Њ –љ–µ –њ–Њ–і–Љ–µ–љ–Є–ї, –њ–Њ—Н—В–Њ–Љ—Г –Є —Б—В–Њ–њ –љ–µ –њ—А–Њ–Є–Ј–Њ—И—С–ї.
–І—В–Њ–±—Л –±—А–µ–Ї–њ–Њ–Є–љ—В –њ–Њ —Н—В–Њ–Љ—Г –∞–і—А–µ—Б—Г –±—Л–ї –ґ–Є–Ј–љ–µ—Б–њ–Њ—Б–Њ–±–љ—Л–Љ, –љ—Г–ґ–љ–Њ —З—В–Њ–±—Л —Б –Љ–Њ–Љ–µ–љ—В–∞ –љ–∞—З–∞–ї–∞ –Њ—В–ї–∞–і–Ї–Є –њ—А–Њ—Ж–µ—Б—Б–∞ –њ—А–Њ–Є–Ј–Њ—И—С–ї —Е–Њ—В—П –±—Л –Њ–і–љ–∞ –Њ—Б—В–∞–љ–Њ–≤–Ї–∞ –њ–Њ—Б–ї–µ —В–Њ–≥–Њ, –Ї–∞–Ї –њ–Њ –∞–і—А–µ—Б—Г
50909DBE –њ–Њ—П–≤–ї—П–µ—В—Б—П –Ї–Њ–і, –љ–Њ –і–Њ —В–Њ–≥–Њ, –Ї–∞–Ї —Н—В–Њ—В –Ї–Њ–і –њ–Њ–ї—Г—З–Є—В —И–∞–љ—Б –≤—Л–њ–Њ–ї–љ–Є—В—М—Б—П.
–Я–Њ—Н—В–Њ–Љ—Г –љ–∞–Љ –љ—Г–ґ–љ–Њ –њ–Њ–љ—П—В—М, –Ї–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ –љ–µ–Ї–Є–є –Ї–Њ–і –Њ–Ї–∞–Ј—Л–≤–∞–µ—В—Б—П –њ–Њ –∞–і—А–µ—Б—Г
50909DBE. –Т–Њ–Њ–±—Й–µ-—В–Њ —Н—В–Њ—В –∞–і—А–µ—Б (—Б–∞–Љ–Њ —З–Є—Б–ї–Њ) –љ–µ –њ–Њ—Е–Њ–ґ –љ–∞ —В–Є–њ–Є—З–љ—Л–є –∞–і—А–µ—Б, –≤—Л–і–µ–ї—П–µ–Љ—Л–є —Д—Г–љ–Ї—Ж–Є—П–Љ–Є HeapAlloc –Є –Є–Љ –њ–Њ–і–Њ–±–љ—Л–Љ вАФ —Н—В–Њ –±–Њ–ї—М—И–µ –њ–Њ—Е–Њ–ґ–µ –љ–∞ –Ј–∞–≥—А—Г–ґ–µ–љ–љ—Л–є –Љ–Њ–і—Г–ї—М (DLL –Є EXE). –≠—В–Њ –Є –µ—Б—В—М –Ј–∞–≥—А—Г–ґ–µ–љ–љ—Л–є –Љ–Њ–і—Г–ї—М, –Є —Н—В–Њ –≤–Є–і–љ–Њ, –µ—Б–ї–Є –њ–µ—А–µ–є—В–Є –≤ –Њ–Ї–љ–Њ –Њ—В–ї–∞–і—З–Є–Ї–∞ ¬ЂModules¬ї (–Ї–љ–Њ–њ–Ї–∞ [E] –≤ —В—Г–ї–±–∞—А–µ).
–Ь–Њ–і—Г–ї–Є, –Ї–Њ—В–Њ—А—Л–µ –њ–Њ—П–≤–Є–ї–Є—Б—М –≤ –Р–Я –њ—А–Њ—Ж–µ—Б—Б–∞ —Б —В–µ—Е –њ–Њ—А, –Ї–∞–Ї –Њ—В–ї–∞–і—З–Є–Ї –≤ –њ–Њ—Б–ї–µ–і–љ–Є–є —А–∞–Ј ¬Ђ–њ—А–Њ–≤–µ—А–Є–ї¬ї —Б–њ–Є—Б–Њ–Ї –Ј–∞–≥—А—Г–ґ–µ–љ–љ—Л—Е –Љ–Њ–і—Г–ї–µ–є, –њ–Њ–і—Б–≤–µ—З–µ–љ—Л –Ї—А–∞—Б–љ—Л–Љ:
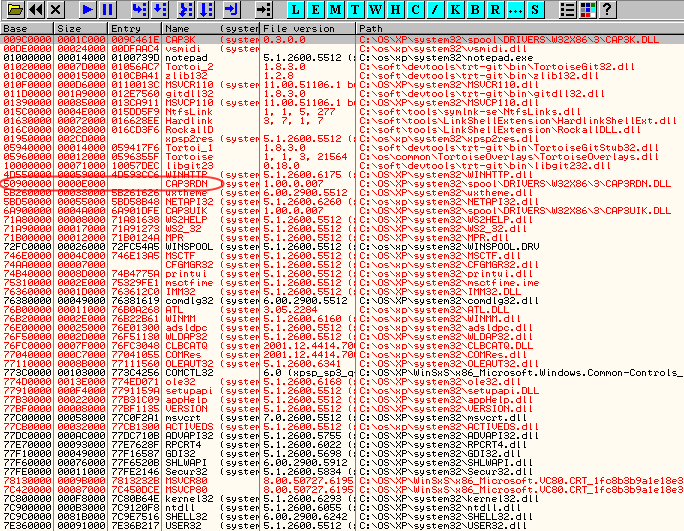
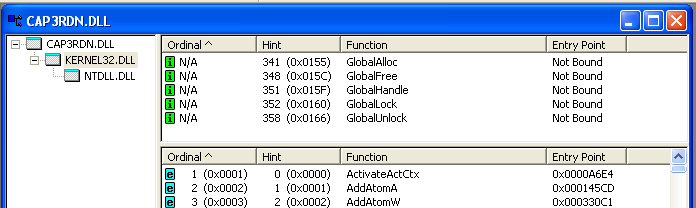
–°—А–µ–і–Є –љ–Є—Е –≤–Є–і–љ–Њ –Є
CAP3RDN.DLL —Б –±–∞–Ј–Њ–≤—Л–Љ –∞–і—А–µ—Б
50900000, –љ–∞ —Б–µ–Ї—Ж–Є—О –Ї–Њ–і–∞ –Ї–Њ—В–Њ—А–Њ–≥–Њ –Є –њ—А–Є—Е–Њ–і–Є—В—Б—П —В–∞ call-–Є–љ—Б—В—А—Г–Ї—Ж–Є—П –њ–Њ –∞–і—А–µ—Б—Г
50909DBE, –љ–∞ –Ї–Њ—В–Њ—А—Г—О –Љ—Л –±–µ–Ј—Г—Б–њ–µ—И–љ–Њ —Б—В–∞–≤–Є–ї–Є –±—А–µ–Ї–њ–Њ–Є–љ—В.
–Ъ—Б—В–∞—В–Є, –Ї–Њ–Љ–∞–љ–і–∞ –Ї–Њ–љ—В–µ–Ї—Б—В–љ–Њ–≥–Њ –Љ–µ–љ—О ¬ЂActualize¬ї (–≤ –Њ–Ї–љ–µ —Б–њ–Є—Б–Ї–∞ –Є—Б–њ–Њ–ї–љ—П–µ–Љ—Л—Е –Љ–Њ–і—Г–ї–µ–є) —Б–і–µ–ї–∞–µ—В –≤—Б–µ —Б—В—А–Њ–Ї–Є —З—С—А–љ—Л–Љ–Є –Є –њ–Њ–Ј–≤–Њ–ї–Є—В –Њ—В—Б–ї–µ–і–Є—В—М –µ—Й—С –љ–Њ–≤—Л–µ –Љ–Њ–і—Г–ї–Є, –Ј–∞–≥—А—Г–ґ–µ–љ–љ—Л–µ —Г–ґ–µ –њ–Њ—Б–ї–µ –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Ї–Њ–Љ–∞–љ–і—Л ¬ЂActualize¬ї.
–Х—Б–ї–Є –≤–µ—А–љ—Г—В—М—Б—П –Ї –Њ–Ї–љ—Г ¬ЂCPU¬ї –Њ—В–ї–∞–і—З–Є–Ї–∞, —В–Њ —Г–ґ–µ –≤–Є–і–љ–Њ, —З—В–Њ –њ–Њ—Б–ї–µ —В–Њ–≥–Њ, –Ї–∞–Ї –Њ—В–ї–∞–і—З–Є–Ї –Њ—Б–Њ–Ј–љ–∞–ї, —З—В–Њ –≤ –Р–Я –Њ—В–ї–∞–ґ–Є–≤–∞–µ–Љ–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞ –Ј–∞ –≤—А–µ–Љ—П –µ–≥–Њ —Б–љ–∞ –±—Л–ї –њ–Њ–і–≥—А—Г–ґ–µ–љ –Љ–Њ–і—Г–ї—М ¬ЂCAP3RDN¬ї (–њ–Њ–Љ–Є–Љ–Њ –њ—А–Њ—З–Є—Е), –Њ–љ —В–µ–њ–µ—А—М –Њ—В–Њ–±—А–∞–ґ–∞–µ—В –Є –љ–∞–Ј–≤–∞–љ–Є–µ –Љ–Њ–і—Г–ї—П –≤ –Ј–∞–≥–Њ–ї–Њ–≤–Ї–µ, –Є –≤ —Б—В–µ–Ї–µ –њ–Њ–Ї–∞–Ј—Л–≤–∞–µ—В –љ–µ –њ—А–Њ—Б—В–Њ ¬ЂRETURN to 50909DC4¬ї, –∞ ¬ЂRETURN to CAP3RDN.50909DC4¬ї:
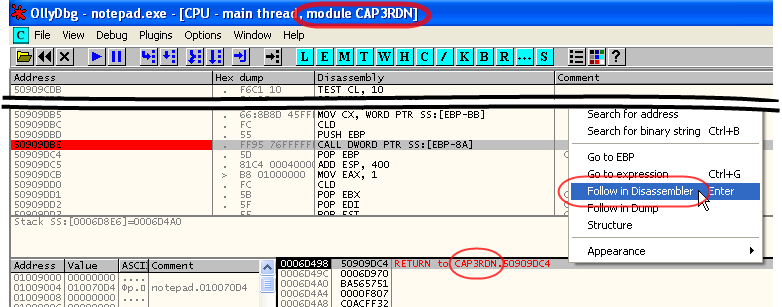
–Э–Њ —Н—В–Њ —В–Њ–ї—М–Ї–Њ –њ–Њ—В–Њ–Љ—Г, —З—В–Њ –Љ—Л –Ј–∞–≥–ї—П–љ—Г–ї–Є –≤ —Б–њ–Є—Б–Њ–Ї –Љ–Њ–і—Г–ї–µ–є, –Ј–∞—Б—В–∞–≤–Є–≤ OllyDbg –Ј–∞–љ–Њ–≤–Њ –њ—А–Њ—Б–Ї–∞–љ–Є—А–Њ–≤–∞—В—М —Н—В–Њ—В —Б–њ–Є—Б–Њ–Ї –Є —А–∞—Б—Б—В–∞–≤–Є—В—М –±—А–µ–Ї–њ–Њ–Є–љ—В—Л —А–∞–љ–µ–µ —Г—Б—В–∞–љ–Њ–≤–ї–µ–љ–љ—Л–µ –±—А–µ–Ї–њ–Њ–Є–љ—В—Л —В–∞–Љ, –≥–і–µ –Њ–љ –љ–µ –Љ–Њ–≥ —Г—Б—В–∞–љ–Њ–≤–Є—В—М —А–∞–љ—М—И–µ.
–Х—Б–ї–Є –Њ—В–ї–∞–ґ–Є–≤–∞–µ–Љ—Л–є –њ—А–Њ—Ж–µ—Б—Б –њ–µ—А–µ–Ј–∞–њ—Г—Б—В–Є—В—М, –±—А–µ–Ї–њ–Њ–Є–љ—В –њ–Њ –∞–і—А–µ—Б—Г
50909DBE –Њ–њ—П—В—М –љ–µ –±—Г–і–µ—В —Г—Б—В–∞–љ–Њ–≤–ї–µ–љ –≤–њ–ї–Њ—В—М –і–Њ —В–Њ–≥–Њ –Љ–Њ–Љ–µ–љ—В–∞, –њ–Њ–Ї–∞ –њ—А–Њ—Ж–µ—Б—Б –љ–µ —Б—В–Њ–ї–Ї–љ—С—В—Б—П —Б –Є—Б–Ї–ї—О—З–µ–љ–Є–µ–Љ —Г–ґ–µ –њ–Њ –∞–і—А–µ—Б—Г
0x0006D4A0 вАФ –љ–Њ —В–Њ–≥–і–∞ –±—Г–і–µ—В –њ–Њ–Ј–і–љ–Њ.
–І—В–Њ–±—Л –і–∞—В—М OllyDbg —И–∞–љ—Б –≤–Њ–≤—А–µ–Љ—П –њ—А–Њ–њ–∞—В—З–Є—В—М –Є–љ—Б—В—А—Г–Ї—Ж–Є—О –њ–Њ –∞–і—А–µ—Б—Г
50909DBE, –љ—Г–ґ–љ–Њ —Б–і–µ–ї–∞—В—М —В–∞–Ї, —З—В–Њ–±—Л –Њ—В–ї–∞–ґ–Є–≤–∞–µ–Љ—Л–є –њ—А–Њ—Ж–µ—Б—Б —Б—В–Њ–њ–љ—Г–ї—Б—П —Б—А–∞–Ј—Г –ґ–µ –њ–Њ—Б–ї–µ —В–Њ–≥–Њ, –Ї–∞–Ї
CAP3RDN.DLL –±—Г–і–µ—В –њ–Њ–і–≥—А—Г–ґ–µ–љ –≤ –Р–Я –Њ—В–ї–∞–ґ–Є–≤–∞–µ–Љ–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞. –Ф–ї—П —Н—В–Њ–≥–Њ –љ—Г–ґ–љ–Њ –љ–∞–є—В–Є –Љ–µ—Б—В–Њ –≤ –Ї–Њ–і–µ, –Ї–Њ—В–Њ—А–Њ–µ –њ–Њ–і–≥—А—Г–ґ–∞–µ—В
CAP3RDN.DLL. –≠—В–Њ –і–µ–ї–∞–µ—В—Б—П –ї–µ–≥–Ї–Њ: –Љ–Њ–ґ–љ–Њ —Г—Б—В–∞–љ–Њ–≤–Є—В—М –±—А–µ–Ї–њ–Њ–Є–љ—В—Л –љ–∞ LoadLibraryA/LoadLibraryW/LoadLibraryExA/LoadLibraryExW –≤ kernel32, –∞ –Љ–Њ–ґ–љ–Њ –≤ –Њ–њ—Ж–Є—П—Е OllyDbg –≤—А–µ–Љ–µ–љ–љ–Њ –≤–Ї–ї—О—З–Є—В—М –Њ–њ—Ж–Є—О ¬ЂBreak on new modules¬ї.
–Т –Є—В–Њ–≥–µ —Н—В–Њ –Љ–µ—Б—В–Њ –ї–µ–≥–Ї–Њ –љ–∞—Е–Њ–і–Є—В—Б—П:
–Ь–Њ–і—Г–ї—М
CAP3K.DLL –Ј–∞–њ—А–∞—И–Є–≤–∞–µ—В –Ј–∞–≥—А—Г–Ј–Ї—Г
CAP3RDN.DLL–Э—Г–ґ–љ–Њ –њ–Њ—Б—В–∞–≤–Є—В—М –±—А–µ–Ї–њ–Њ–Є–љ—В
–њ–Њ—Б–ї–µ –≤—Л–Ј–Њ–≤–∞
LoadLibraryW, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –µ—Б–ї–Є –Њ—В–ї–∞–і—З–Є–Ї —Б—В–Њ–њ–љ–µ—В—Б—П –і–Њ –Ј–∞–≥—А—Г–Ј–Ї–Є –±–Є–±–ї–Є–Њ—В–µ–Ї–Є, —В–Њ–ї–Ї—Г –Њ—В —Н—В–Њ–≥–Њ –љ–µ –±—Г–і–µ—В –љ–Є–Ї–∞–Ї–Њ–≥–Њ, –∞ –≤–Њ—В –µ—Б–ї–Є –њ–Њ—Б–ї–µ вАФ —В–Њ –Њ–љ —Г–≤–Є–і–Є—В –љ–Њ–≤—Л–є –Ї–Њ–і –њ–Њ –њ–Њ –∞–і—А–µ—Б–∞–Љ 50900000вАФ5090E000 –Є –њ—А–Є–Љ–µ–љ–Є—В –±—А–µ–Ї–њ–Њ–Є–љ—В (—В–Њ –µ—Б—В—М –њ—А–Њ–њ–∞—В—З–Є—В –њ–µ—А–≤—Л–є –±–∞–є—В –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є –њ–Њ –∞–і—А–µ—Б—Г
50909DBE) –Є —В–Њ–≥–і–∞ –Љ—Л —Б–Љ–Њ–ґ–µ–Љ –љ–∞ –љ–µ–є –Њ—Б—В–∞–љ–Њ–≤–Є—В—М—Б—П.
–Ґ–µ–њ–µ—А—М –њ–µ—А–µ–Ј–∞–њ—Г—Б–Ї–∞–µ–Љ –Њ—В–ї–∞–і–Ї—Г –њ—А–Њ—Ж–µ—Б—Б–∞ —Б –љ—Г–ї—П. –Т—Л–≤–Њ–і–Є–Љ –њ—А–Њ–Є–Ј–≤–Њ–ї—М–љ—Л–є —В–µ–Ї—Б—В –љ–∞ –њ–µ—З–∞—В—М. –°–љ–∞—З–∞–ї–∞ –Љ—Л —Б—В–Њ–њ–∞–µ–Љ—Б—П –њ–Њ—Б–ї–µ –Љ–Њ–Љ–µ–љ—В–∞ –њ–Њ–і–≥—А—Г–Ј–Ї–Є
CAP3RDN.DLL. –Т —Н—В–Њ—В –Љ–Њ–Љ–µ–љ—В –љ—Г–ґ–љ–Њ –≥–ї—П–љ—Г—В—М —Б–њ–Є—Б–Њ–Ї –Љ–Њ–і—Г–ї–µ–є –≤ OllyDbg –Є –њ—А–Њ–і–Њ–ї–ґ–Є—В—М –≤—Л–њ–Њ–ї–љ–µ–љ–Є–µ –Њ—В–ї–∞–ґ–Є–≤–∞–µ–Љ–Њ–≥–Њ –њ—А–Њ—Ж–µ—Б—Б–∞. –Р –≤–Њ—В —Б–ї–µ–і—Г—О—Й–∞—П –Њ—Б—В–∞–љ–Њ–≤–Ї–∞ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –Ї–∞–Ї —А–∞–Ј –љ–∞ –Є–љ—В–µ—А–µ—Б—Г—О—Й–µ–є –љ–∞—Б call-–Є–љ—Б—В—А—Г–Ї—Ж–Є–Є:
–Т –Є—В–Њ–≥–µ, –Љ—Л –Њ–Ї–∞–Ј–∞–ї–Є—Б—М –њ—А–∞–≤—Л —Б –Є–Ј–љ–∞—З–∞–ї—М–љ—Л–Љ –њ—А–µ–і–њ–Њ–ї–Њ–ґ–µ–љ–Є–µ–Љ, —З—В–Њ –Є–Љ–µ–љ–љ–Њ —Н—В–∞ call-–Є–љ—Б—В—А—Г–Ї—Ж–Є—П –њ–µ—А–µ–і–∞—С—В —Г–њ—А–∞–≤–ї–µ–љ–Є–µ –љ–∞ —Д—А–∞–≥–Љ–µ–љ—В –Ї–Њ–і–∞, –ї–µ–ґ–∞—Й–µ–є –≤ —Б—В—А–∞–љ–Є—Ж–µ, –љ–µ –Є–Љ–µ—О—Й–µ–є –њ—А–∞–≤–∞ –љ–∞ –≤—Л–њ–Њ–ї–љ–µ–љ–Є–µ. –Ґ–µ–њ–µ—А—М –і–Њ—Б—В–∞—В–Њ—З–љ–Њ –љ–∞–є—В–Є –Љ–µ—Б—В–Њ, –≥–і–µ —Н—В–Њ—В —Д—А–∞–≥–Љ–µ–љ—В –њ–∞–Љ—П—В–Є –≤—Л–і–µ–ї—П–µ—В—Б—П –Є –њ–Њ–Љ–µ–љ—П—В—М —Б–њ–Њ—Б–Њ–±, –Ї–Њ—В–Њ—А—Л–Љ –Њ–љ –≤—Л–і–µ–ї—П–µ—В—Б—П, –љ–∞ DEP-friendly.
–Ю—З–µ–≤–Є–і–љ–Њ, —З—В–Њ –і—А–∞–є–≤–µ—А –њ—А–Є–љ—В–µ—А–∞ –≤—Л–і–µ–ї—П–µ—В –≤ –њ–∞–Љ—П—В–Є –Ї—Г—Б–Њ—З–µ–Ї, –≤ –Ї–Њ—В–Њ—А—Л–є –Ј–∞–њ–Є—Б—Л–≤–∞–µ—В –Ї–Њ–і, –∞ –і–∞–ї–µ–µ –њ–Њ —Е–Њ–і—Г —А–∞–±–Њ—В—Л –њ–µ—А–µ–і–∞—С—В —Г–њ—А–∞–≤–ї–µ–љ–Є–µ —Н—В–Њ–Љ—Г –Ї–Њ–і—Г. –Э—Г–ґ–љ–Њ –љ–∞–є—В–Є –Љ–µ—Б—В–Њ, –≥–і–µ –≤—Л–і–µ–ї—П–µ—В—Б—П –њ–∞–Љ—П—В—М –њ–Њ–і —Н—В–Њ—В –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Є —Д–Њ—А–Љ–Є—А—Г–µ–Љ—Л–є –Ї–Њ–і, –Є –µ—Б–ї–Є —Н—В–Њ –±—Г–і–µ—В
VirtualAlloc, —В–Њ –Љ–Њ–і–Є—Д–Є—Ж–Є—А–Њ–≤–∞—В—М –Ї–Њ–Љ–±–Є–љ–∞—Ж–Є—О —Д–ї–∞–≥–Њ–≤, –њ–µ—А–µ–і–∞–≤–∞–µ–Љ—Г—О –≤ 4-–є –њ–∞—А–∞–Љ–µ—В—А, –і–Њ–±–∞–≤–Є–≤ –±–Є—В
PAGE_EXECUTE.
–Х—Б–ї–Є —Н—В–Њ –±—Г–і–µ—В
HeapAlloc, —В–Њ –љ—Г–ґ–љ–Њ –љ–∞–є—В–Є –Љ–Њ–Љ–µ–љ—В —Б–Њ–Ј–і–∞–љ–Є—П –Ї—Г—З–Є (–≤—Л–Ј–Њ–≤
HeapCreate) –Є –Њ–њ—П—В—М-—В–∞–Ї–Є –Љ–Њ–і–Є—Д–Є—Ж–Є—А–Њ–≤–∞—В—М –Ј–љ–∞—З–µ–љ–Є–µ, –њ–µ—А–µ–і–∞–≤–∞–µ–Љ–Њ–µ –≤ 1-–є –њ–∞—А–∞–Љ–µ—В—А (–і–Њ–±–∞–≤–Є–≤ –±–Є—В
HEAP_CREATE_ENABLE_EXECUTE).
–ѓ —А–µ—И–Є–ї –≤—Л—П—Б–љ–Є—В—М, –Ї–∞–Ї–Њ–є —Д—Г–љ–Ї—Ж–Є–µ–є –Љ–Њ–і—Г–ї—М
CAP3RDN.DLL –≤—Л–і–µ–ї—П–µ—В –њ–∞–Љ—П—В—М –њ–Њ–і –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Є —Д–Њ—А–Љ–Є—А—Г–µ–Љ—Л–є –Ї—Г—Б–Њ—З–µ–Ї –Ї–Њ–і–∞, –∞ –њ–Њ—В–Њ–Љ –љ–∞ –≤—Б–µ –≤—Л–Ј–Њ–≤—Л —Н—В–Њ–є —Д—Г–љ–Ї—Ж–Є–Є –њ–Њ—Б—В–∞–≤–Є—В—М –±—А–µ–Ї–њ–Њ–Є–љ—В—Л –Є –≤—Л—П—Б–љ–Є—В—М, –≥–і–µ –Є–Љ–µ–љ–љ–Њ (–Њ—В–Ї—Г–і–∞) –≤—Л–і–µ–ї—П–µ—В—Б—П –њ–∞–Љ—П—В—М –њ–Њ–і —Д—А–∞–≥–Љ–µ–љ—В –Є –њ—А–Њ–њ–∞—В—З–Є—В—М —Н—В–Њ—В –Ї–Њ–і.
–Ю–і–љ–∞–Ї–Њ, –њ–Њ—Б–Љ–Њ—В—А–µ–≤ –Є–Љ–њ–Њ—А—В—Л
CAP3RDN.DLL —П –≤ –њ–µ—А–≤—Л–є —А–∞–Ј —А–∞–Ј–Њ—З–∞—А–Њ–≤–∞–ї—Б—П: –Њ–љ–∞ –љ–µ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В –љ–Є
VirtualAlloc, –љ–Є
HeapAlloc.
–Т—Б–µ –≤—Л–і–µ–ї–µ–љ–Є—П –њ–∞–Љ—П—В–Є –і–µ–ї–∞—О—В—Б—П —Б –њ–Њ–Љ–Њ—Й—М—О GlobalAlloc, —З—В–Њ –њ–Њ—А—В–Є—В –і–µ–ї–Њ, –њ–Њ—В–Њ–Љ—Г —З—В–Њ —Д–Є–Ї—Б–Њ–Љ –≤ 1 –±–∞–є—В —Г–ґ–µ –љ–µ –Њ–±–Њ–є–і—С—В—Б—П: –њ—А–Є–і—С—В—Б—П –Љ–Њ–і–Є—Д–Є—Ж–Є—А–Њ–≤–∞—В—М —В–∞–±–ї–Є—Ж—Г –Є–Љ–њ–Њ—А—В–∞ –Є –і–Њ–±–∞–≤–ї—П—В—М –±–Њ–ї—М—И–µ –Ї–Њ–і–∞ –≤ —Б–µ–Ї—Ж–Є—О –і–∞–љ–љ—Л—Е.
–ѓ –њ–Њ—Б—В–∞–≤–Є–ї –±—А–µ–Ї–њ–Њ–Є–љ—В—Л –љ–∞ –≤—Б–µ –≤—Л–Ј–Њ–≤—Л
GlobalAlloc, —Б–і–µ–ї–∞–ї –њ—А–Њ–≥–Њ–љ, –љ–Њ —Б—А–µ–і–Є –≤—Л–і–µ–ї—П–µ–Љ—Л—Е —Д—А–∞–≥–Љ–µ–љ—В–Њ–≤ –љ–µ –Њ–Ї–∞–Ј–∞–ї–Њ—Б—М —Д—А–∞–≥–Љ–µ–љ—В–∞, –њ–Њ –Ї–Њ—В–Њ—А–Њ–Љ—Г –≤–њ–Њ—Б–ї–µ–і—Б—В–≤–Є–Є –Њ—Б—Г—Й–µ—Б—В–≤–ї—П–µ—В—Б—П –њ–µ—А–µ—Е–Њ–і. –Ъ–∞–Ї –ґ–µ —В–∞–Ї? –Т–µ–і—М –±–Њ–ї—М—И–µ –±–Є–±–ї–Є–Њ—В–µ–Ї–∞ –љ–Є–Ї–∞–Ї –њ–∞–Љ—П—В—М –≤—Л–і–µ–ї—П—В—М –љ–µ –Љ–Њ–ґ–µ—В, –Њ–љ–∞ –µ—С –≤—Л–і–µ–ї—П–µ—В, –љ–Њ –љ–µ –≤—Л–Ј–Њ–≤–Њ–Љ
GlobalAlloc. –Р —З–µ–Љ –ґ–µ –µ—Й—С?
–Ю—Б—В–∞–≤–∞–ї—Б—П —В–Њ–ї—М–Ї–Њ –Њ–і–Є–љ –≤–∞—А–Є–∞–љ—В, –Є —П –њ–Њ–і–Њ—И—С–ї –Ї –≤—Л—П—Б–љ–µ–љ–Є—О —Н—В–Њ–≥–Њ –Љ–Њ–Љ–µ–љ—В–∞ —Б –і—А—Г–≥–Њ–є —Б—В–Њ—А–Њ–љ—Л.
–Р–і—А–µ—Б, –њ–Њ –Ї–Њ—В–Њ—А–Њ–Љ—Г –љ—Г–ґ–љ–Њ –њ–µ—А–µ–є—В–Є, –Є–љ—Б—В—А—Г–Ї—Ж–Є—П
CALL –±–µ—А—С—В –њ–Њ –∞–і—А–µ—Б—Г
dword[EBP-8A]. –Р –Ї–∞–Ї —Н—В–Њ—В –∞–і—А–µ—Б –њ–Њ–њ–∞–і–∞–µ—В –њ–Њ–њ–∞–і–∞–µ—В –≤
DWORD[EBP-8A]?
–ѓ –њ—А–Њ—Б—В–Њ –њ—А–Њ—Б–Љ–Њ—В—А–µ–ї –Ї–Њ–і —Б–љ–Є–Ј—Г –≤–≤–µ—А—Е –Є –љ–∞—И—С–ї –Љ–µ—Б—В–Њ, –≥–і–µ –∞–і—А–µ—Б, –њ–Њ –Ї–Њ—В–Њ—А–Њ–Љ—Г –њ—А–Њ–Є–Ј–Њ–є–і—С—В –≤—Л–Ј–Њ–≤, –њ–Њ–Љ–µ—Й–∞–µ—В—Б—П –≤ —П—З–µ–є–Ї—Г –њ–Њ –∞–і—А–µ—Б—Г
EBP-8A:
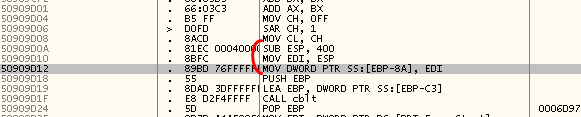
–Т–Њ—В –Њ–љ–Њ —З—В–Њ! –Ь–µ—Б—В–Њ –њ–Њ–і –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Є —Д–Њ—А–Љ–Є—А—Г–µ–Љ—Л–є –Ї—Г—Б–Њ–Ї –Ї–Њ–і–∞ –≤—Л–і–µ–ї—П–µ—В—Б—П –Є–Ј —Б—В–µ–Ї–∞! –Я–Њ—Н—В–Њ–Љ—Г –љ–Є –Њ–і–Є–љ –≤—Л–Ј–Њ–≤ GlobalAlloc –Є –љ–µ –≤–µ—А–љ—Г–ї –Є–љ—В–µ—А–µ—Б—Г—О—Й–Є–є –Љ–µ–љ—П –∞–і—А–µ—Б. –Т–Њ—В —В—Г—В —Е–Њ—А–Њ—И–Њ –≤–Є–і–љ–Њ, —З—В–Њ –Є–Ј —Б—В–µ–Ї–∞ –≤—Л–і–µ–ї—П–µ—В—Б—П 400h –±–∞–є—В–Њ–≤ –њ–∞–Љ—П—В–Є, –њ–Њ–ї—Г—З–µ–љ–љ—Л–є –∞–і—А–µ—Б –Ј–∞–њ–Є—Б—Л–≤–∞–µ—В—Б—П –≤ —А–µ–≥–Є—Б—В—А EDI, –∞ –Ј–∞—В–µ–Љ —Н—В–Њ –Ј–љ–∞—З–µ–љ–Є–µ –Ј–∞–њ–Є—Б—Л–≤–∞–µ—В—Б—П –≤ –ї–Њ–Ї–∞–ї—М–љ—Г—О –њ–µ—А–µ–Љ–µ–љ–љ—Г—О –њ–Њ –∞–і—А–µ—Б—Г
EBP-8A. –Ф–∞–ї–µ–µ –≤—Л–Ј—Л–≤–∞–µ—В—Б—П –њ—А–Њ—Ж–µ–і—Г—А–∞
cblt, –Ї–Њ—В–Њ—А–∞—П, –Ї–∞–Ї –Њ–Ї–∞–Ј–∞–ї–Њ—Б—М, –љ–∞ –Љ–µ—Б—В–µ –≤—Л–і–µ–ї–µ–љ–љ–Њ–≥–Њ –Є–Ј —Б—В–µ–Ї–∞ —Г—З–∞—Б—В–Ї–∞ –Є —Д–Њ—А–Љ–Є—А—Г–µ—В –Ї–Њ–і, –Ї–Њ—В–Њ—А—Л–є –њ–Њ–Ј–і–љ–µ–µ –±—Г–і–µ—В –≤—Л–њ–Њ–ї–љ–µ–љ. –І—Г—В—М –њ–Њ–Ј–ґ–µ –∞–і—А–µ—Б –Ї–Њ–і–∞ –Є–Ј–≤–ї–µ–Ї–∞–µ—В—Б—П –Є–Ј
DWORD[EBP-8A] –Є –і–µ–ї–∞–µ—В—Б—П –≤—Л–Ј–Њ–≤.
–°–њ–µ—А–≤–∞ —П –њ–Њ–і—Г–Љ–∞–ї, —З—В–Њ –Ї–Њ–і —Н—В–Њ–є –њ—А–Њ—Ж–µ–і—Г—А—Л (–љ–µ
cblt, –∞ —В–Њ–є, –Ї–Њ—В–Њ—А–∞—П –≤—Л–і–µ–ї—П–µ—В –њ–∞–Љ—П—В—М –љ–∞ —Б—В–µ–Ї–µ, –Њ–љ–∞ –љ–∞–Ј—Л–≤–∞–µ—В—Б—П
RP_BITMAP1T01) –љ–∞–њ–Є—Б–∞–љ –љ–∞ –°–Є –Є –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В
alloca. –Э–Њ –≤—Б–Ї–Њ—А–µ —П –њ–Њ–љ—П–ї, —З—В–Њ –Ї–Њ–і –љ–∞–њ–Є—Б–∞–љ –љ–µ –љ–∞ –°–Є, –∞ —Б–Ї–Њ—А–µ–µ –≤—Б–µ–≥–Њ –љ–∞ –∞—Б—Б–µ–Љ–±–ї–µ—А–µ, –њ–Њ –і–≤—Г–Љ –њ—А–Є—З–Є–љ–∞–Љ:
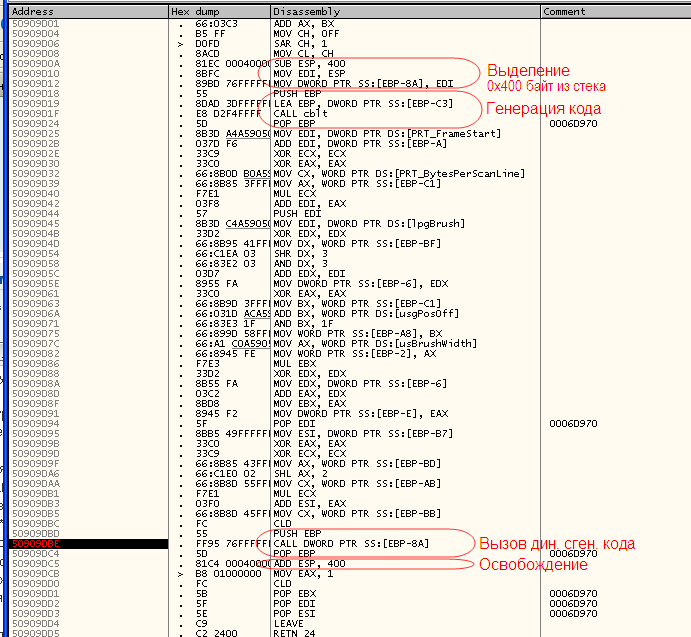
- –Я—А–Є –≤—Л–Ј–Њ–≤–µ cblt –∞–і—А–µ—Б –±—Г—Д–µ—А–∞, –≤ –Ї–Њ—В–Њ—А–Њ–Љ cblt —Б—Д–Њ—А–Љ–Є—А—Г–µ—В –Ї—Г—Б–Њ–Ї –Ї–Њ–і–∞, –њ–µ—А–µ–і–∞—С—В—Б—П —З–µ—А–µ–Ј —А–µ–≥–Є—Б—В—А EDI, —З—В–Њ –љ–µ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –љ–Є –Њ–і–љ–Њ–Љ—Г –Є–Ј —Б—В–∞–љ–і–∞—А—В–љ—Л—Е —Б–Њ–≥–ї–∞—И–µ–љ–Є–є –Њ –≤—Л–Ј–Њ–≤–µ (—Н—В–Њ –љ–µ fastcall!).
- –Я—А–Є —В–Њ–Љ, —З—В–Њ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П EBP-–Њ—В–љ–Њ—Б–Є—В–µ–ї—М–љ–∞—П –∞–і—А–µ—Б–∞—Ж–Є—П —Б—В–µ–Ї–∞, –њ–Њ—Б–ї–µ –Ј–ї–Њ—Б—З–∞—Б—В–љ–Њ–≥–Њ –≤—Л–Ј–Њ–≤–∞ –≤—Л–і–µ–ї–µ–љ–љ—Л–µ –Є–Ј —Б—В–µ–Ї–∞ 400h –±–∞–є—В–Њ–≤ ¬Ђ–Њ—Б–≤–Њ–±–Њ–ґ–і–∞—О—В—Б—П¬ї –Є–љ—Б—В—А—Г–Ї—Ж–Є–µ–є add esp, 400h, —З—В–Њ –љ–µ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В —В–Њ–Љ—Г, –Ї–∞–Ї–Њ–є –Ї–Њ–і –≥–µ–љ–µ—А–Є—А—Г–µ—В—Б—П —Б–Є—И–љ—Л–Љ–Є –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–∞–Љ–Є –њ—А–Є –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–Є alloca.
–Ъ–Њ–Љ—Г –Є–љ—В–µ—А–µ—Б–љ–Њ, –Ї—Г—Б–Њ–Ї –Є–Ј
RP_BITMAP1T01 –њ–Њ–ї–љ–Њ—Б—В—М—О: –≤—Л–і–µ–ї–µ–љ–Є–µ, –≥–µ–љ–µ—А–∞—Ж–Є—П –Ї–Њ–і–∞, –≤—Л–Ј–Њ–≤ —Б–≥–µ–љ–µ—А–Є—А–Њ–≤–∞–љ–љ–Њ–≥–Њ –Ї–Њ–і–∞, –Њ—Б–≤–Њ–±–Њ–ґ–і–µ–љ–Є–µ.
–І—В–Њ –Љ–Њ–ґ–љ–Њ —Б–Ї–∞–Ј–∞—В—М? –Р–≤—В–Њ—А—Л –і—А–∞–є–≤–µ—А–∞ вАФ —В–µ –µ—Й—С –Ј–∞—В–µ–є–љ–Є–Ї–Є. –Ь–∞–ї–Њ —В–Њ–≥–Њ, —З—В–Њ –Њ–љ–Є –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Є –≥–µ–љ–µ—А–Є—А—Г–µ–Љ—Л–є –Ї–Њ–і (–љ–µ –Є–Љ–µ—О –љ–Є—З–µ–≥–Њ –њ—А–Њ—В–Є–≤), —В–∞–Ї –Њ–љ–Є –Љ–µ—Б—В–Њ –њ–Њ–і –љ–µ–≥–Њ –≤—Л–і–µ–ї—П—О—В –њ—А—П–Љ–Њ –Є–Ј —Б—В–µ–Ї–∞! –•–Њ—В—П –љ–∞ –њ–µ—А–≤—Л–є –≤–Ј–≥–ї—П–і —Н—В–Њ –Љ–Њ–ґ–µ—В –њ–Њ–Ї–∞–Ј–∞—В—М—Б—П –Ї—А–Є–≤—Л–Љ –њ–Њ–і—Е–Њ–і–Њ–Љ, –≤ —Н—В–Њ–Љ –µ—Б—В—М —А–∞–Ј—Г–Љ–љ–Њ–µ –Ј–µ—А–љ–Њ: –≤–Є–і–Є–Љ–Њ –њ–Њ–і—Е–Њ–і —Б –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Њ–є –≥–µ–љ–µ—А–∞—Ж–Є–µ–є –Ї–Њ–і–∞ –њ—А–Є–Љ–µ–љ—С–љ –≤ —Ж–µ–ї—П—Е —Г–≤–µ–ї–Є—З–µ–љ–Є—П –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є. –Я—А–Є —Н—В–Њ–Љ –Ї–∞–ґ–і—Л–є —А–∞–Ј –≥–µ–љ–µ—А–Є—А—Г–µ—В—Б—П –љ–Њ–≤—Л–є –Ї–Њ–і (—А–∞–Ј —Д–Њ—А–Љ–Є—А–Њ–≤–∞–љ–Є–µ –Ї–Њ–і–∞ –љ–µ –≤—Л–љ–µ—Б–ї–Є ¬Ђ–Ј–∞ —Б–Ї–Њ–±–Ї–Є¬ї). –Р —А–∞–Ј —В–∞–Ї, –≤—Л–і–µ–ї—П—В—М –њ–∞–Љ—П—В—М –љ—Г–ґ–љ–Њ –Ї–∞–ґ–і—Л–є —А–∞–Ј. –Р –≤—Л–і–µ–ї–µ–љ–Є–µ –њ–∞–Љ—П—В–Є —Б –њ–Њ–Љ–Њ—Й—М—О WinAPI-—Д—Г–љ–Ї—Ж–Є–є —Г–±–Є–ї–Њ –±—Л –≤–µ—Б—М –≤—Л–Є–≥—А—Л—И –≤ —Б–Ї–Њ—А–Њ—Б—В–Є –Њ—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Є —Д–Њ—А–Љ–Є—А—Г–µ–Љ–Њ–≥–Њ –Ї–Њ–і–∞. –Т —В–Њ –≤—А–µ–Љ—П –Ї–∞–Ї –≤—Л–і–µ–ї–µ–љ–Є–µ –Ї—Г—Б–Њ—З–Ї–∞ –Є–Ј —Б—В–µ–Ї–∞ вАФ —З—А–µ–Ј–≤—Л—З–∞–є–љ–Њ –±—Л—Б—В—А–∞—П –≤–µ—Й—М –њ–Њ —Б—А–∞–≤–љ–µ–љ–Є—О —Б —Б–Є—Б—В–µ–Љ–љ—Л–Љ –≤—Л–Ј–Њ–≤–Њ–Љ (–µ—Б–ї–Є —В–Њ–ї—М–Ї–Њ –њ—А–Є —А–Њ—Б—В–µ —Б—В–µ–Ї–∞ –≤–≤–µ—А—Е –љ–µ –њ—А–Њ–Є–Ј–Њ–є–і—С—В —А–∞—Б—И–Є—А–µ–љ–Є–µ –љ–∞–±–Њ—А–∞ –Ј–∞–Ї–Њ–Љ–Љ–Є—З–µ–љ–љ—Л—Е —Б—В—А–∞–љ–Є—Ж —Б—В–µ–Ї–∞ (–љ–Њ –Њ–љ–Њ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В 1 —А–∞–Ј)).
–° –і—А—Г–≥–Њ–є —Б—В–Њ—А–Њ–љ—Л —П –њ–Њ—Б–Љ–Њ—В—А–µ–ї: –≤–Њ –≤—Б–µ–є –±–Є–±–ї–Є–Њ—В–µ–Ї–Є –µ—Б—В—М —В–Њ–ї—М–Ї–Њ 1 –Њ–±—А–∞—Й–µ–љ–Є–µ –Ї –њ—А–Њ—Ж–µ–і—Г—А–µ
cblt вАФ –≤–Њ—В —Н—В–Њ, –Ї–Њ—В–Њ—А–Њ–µ –Љ—Л –≤–Є–і–Є–Љ. –Ь–Њ–ґ–µ—В –±—Л—В—М –њ–Њ–Љ–Є–Љ–Њ
cblt –µ—Б—В—М –Є –і—А—Г–≥–Є–µ –њ—А–Њ—Ж–µ–і—Г—А—Л, –≤—Л–њ–Њ–ї–љ—П—О—Й–Є–µ –≥–µ–љ–µ—А–∞—Ж–Є—О –Ї–Њ–і–∞, –љ–Њ –µ—Б–ї–Є –љ–µ—В, —В–Њ –Ј–љ–∞—З–Є—В —Н—В–Њ –µ–і–Є–љ—Б—В–≤–µ–љ–љ–Њ–µ –Љ–µ—Б—В–Њ —Б –Ї–Њ–і–Њ–≥–µ–љ–µ—А–∞—Ж–Є–µ–є, –∞ —А–∞–Ј —В–∞–Ї, —В–Њ –≤—Л–і–µ–ї–µ–љ–Є–µ –±—Г—Д–µ—А–∞ –њ–Њ–і –≥–µ–љ–µ—А–Є—А—Г–µ–Љ—Л–є –Ї–Њ–і –Љ–Њ–ґ–љ–Њ –±—Л–ї–Њ –±—Л –≤—Л–љ–µ—Б—В–Є ¬Ђ–Ј–∞ —Б–Ї–Њ–±–Ї–Є¬ї, —В–Њ –µ—Б—В—М –і–µ–ї–∞—В—М 1 —А–∞–Ј вАФ –≤ —В–∞–Ї–Њ–Љ —Б–ї—Г—З–∞–µ –љ–µ—В –љ–Є—З–µ–≥–Њ –Ј–∞–Ј–Њ—А–љ–Њ–≥–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —Б–Є—Б—В–µ–Љ–љ—Л–µ –≤—Л–Ј–Њ–≤—Л.
–І—В–Њ –ґ, –њ–Њ –Ї—А–∞–є–љ–µ–є –Љ–µ—А–µ —В–µ–њ–µ—А—М —Г –љ–∞—Б –µ—Б—В—М –≤—Б–µ –Ј–љ–∞–љ–Є—П, –љ–µ–Њ–±—Е–Њ–і–Є–Љ—Л–µ, —З—В–Њ–±—Л –њ–Њ—Д–Є–Ї—Б–Є—В—М —Н—В–Њ—В –Љ–Њ–Љ–µ–љ—В. –Ь–Њ–ґ–µ—В –±—Л—В—М, –Ї–Њ–љ–µ—З–љ–Њ, –њ–Њ—Б–ї–µ —В–Њ–≥–Њ, –Ї–∞–Ї –Љ—Л —Б–і–µ–ї–∞–µ–Љ —Н—В–Њ –Љ–µ—Б—В–Њ DEP-friendly, –Љ—Л –≤—Л–≤–∞–ї–Є–Љ—Б—П —Б–ї–µ–і–Њ–Љ –≥–і–µ-–љ–Є–±—Г–і—М –µ—Й—С вАФ —Г–Ј–љ–∞–µ–Љ —В–Њ–ї—М–Ї–Њ –њ–Њ—Б–ї–µ —В–Њ–≥–Њ, –Ї–∞–Ї –њ–Њ–њ—А–Њ–±—Г–µ–Љ.
–Х—Б—В—М –і–≤–∞ —Б–њ–Њ—Б–Њ–±–∞ –≤—Л–ї–µ—З–Є—В—М —Н—В–Њ—В –Ї–Њ–і: –≤–Љ–µ—Б—В–Њ –≤—Л–і–µ–ї–µ–љ–Є—П –њ–∞–Љ—П—В–Є —Б–Њ —Б—В–µ–Ї–∞ –≤—Л–і–µ–ї—П—В—М –Є–Ј –Ї—Г—З–Є, –ї–Є–±–Њ –Њ—Б—В–∞–≤–Є—В—М –≤—Л–і–µ–ї–µ–љ–Є–µ –Є–Ј —Б—В–µ–Ї–∞, –љ–Њ –Љ–µ–љ—П—В—М –∞—В—А–Є–±—Г—В—Л –і–Њ—Б—В—Г–њ–∞ —Б—В—А–∞–љ–Є—Ж—Л —Б—В–µ–Ї–∞ (–Є—Б–Ї–ї—О—З–Є—В–µ–ї—М–љ–Њ –љ–∞ –≤—А–µ–Љ—П –≤—Л–і–µ–ї–µ–љ–Є—П 1024-–±–∞–є—В–Њ–≤–Њ–≥–Њ —Д—А–∞–≥–Љ–µ–љ—В–∞ —Б—В–µ–Ї–∞ –њ–Њ–і –Ї–Њ–і). –Т—В–Њ—А–Њ–є –≤–∞—А–Є–∞–љ—В –љ–µ –Њ—З–µ–љ—М —Е–Њ—А–Њ—И, –≤–µ–і—М –Њ–љ –і–µ–ї–∞–µ—В 1 –Є–ї–Є –і–∞–ґ–µ 2 —Б—В—А–∞–љ–Є—Ж—Л —Б—В–µ–Ї–∞ –њ–Њ—В–µ–љ—Ж–Є–∞–ї—М–љ–Њ –Њ–њ–∞—Б–љ—Л–Љ–Є —Б —В–Њ—З–Ї–Є –Ј—А–µ–љ–Є—П —Г—П–Ј–≤–Є–Љ–Є–Њ—Б—В–Є.
–Я–µ—А–≤—Л–є –ґ–µ –Њ—Б–ї–Њ–ґ–љ—С–љ —В–µ–Љ, —З—В–Њ –ї–Є–±–Њ –њ–∞–Љ—П—В—М –њ—А–Є–і—С—В—Б—П –≤—Л–і–µ–ї—П—В—М —Б –њ–Њ–Љ–Њ—Й—М—О
VirtualAlloc вАФ –∞ —Н—В–Њ –≤–ї–µ—З—С—В –Ј–∞ —Б–Њ–±–Њ–є –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ—Б—В—М –µ—Й—С –Є —А–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞—В—М –њ–∞–Љ—П—В—М. –†–µ–Ј–µ—А–≤–Є—А—Г–µ—В—Б—П –њ–∞–Љ—П—В—М –±–ї–Њ–Ї–∞–Љ–Є –њ–Њ 64–Ї–±, –∞ –≤—Л–і–µ–ї—П–µ—В—Б—П —Б—В—А–∞–љ–Є—Ж–∞–Љ–Є –њ–Њ 4–Ї–±, –∞ –≤–µ–і—М –љ–∞–Љ –љ—Г–ґ–љ–Њ-—В–Њ 1024 –±–∞–є—В–∞ –≤—Б–µ–≥–Њ! –Ф–∞ –Є —А–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞–љ–Є–µ+–≤—Л–і–µ–ї–µ–љ–Є–µ вАФ –і–Њ–ї–≥–∞—П –Њ–њ–µ—А–∞—Ж–Є—П. –Ы–Є–±–Њ –њ—А–Є–і—С—В—Б—П –≤—Л–і–µ–ї—П—В—М —Б –њ–Њ–Љ–Њ—Й—М—О HeapAlloc, –∞ —Н—В–Њ –≤–ї–µ—З—С—В –Ј–∞ —Б–Њ–±–Њ–є –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ—Б—В—М —Б–Њ–Ј–і–∞–≤–∞—В—М –Ї—Г—З—Г —Б –њ—А–∞–≤–Њ–Љ –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –і–ї—П –µ—С —Б—В–∞–љ–Є—Ж. –°–Њ–Ј–і–∞–љ–Є–µ –Ї—Г—З–Є вАФ —З–µ—А—В–Њ–≤—Б–Ї–Є —В—П–ґ–µ–ї–∞—П –Њ–њ–µ—А–∞—Ж–Є—П (–≤ —А–∞—Б—Б–Љ–∞—В—А–Є–≤–∞–µ–Љ—Л—Е –Љ–∞—Б—И—В–∞–±–∞—Е!), –Ї —В–Њ–Љ—Г –ґ–µ, –љ—Г–ґ–љ–Њ –≥–і–µ-—В–Њ —Е—А–∞–љ–Є—В—М —Е–µ–љ–і–ї –Ї—Г—З–Є, —З—В–Њ –њ—А–µ–і—Б—В–∞–≤–ї—П–µ—В —Б–Њ–±–Њ–є –Њ—Б–Њ–±—Г—О –њ—А–Њ–±–ї–µ–Љ—Г, –≤–µ–і—М –Ї–Њ–і –і—А–∞–є–≤–µ—А–∞ –љ–∞–≤–µ—А–љ—П–Ї–∞ –і–Њ–ї–ґ–µ–љ –±—Л—В—М –Љ–љ–Њ–≥–Њ–њ–Њ—В–Њ—З–љ—Л–Љ, –∞ –Ј–љ–∞—З–Є—В ¬Ђ–≤–Ј—П—В—М¬ї —Б–µ–±–µ –Љ–µ—Б—В–Њ –Є–Ј —Б–µ–Ї—Ж–Є–Є –і–∞–љ–љ—Л—Е –њ–Њ–і –њ–µ—А–µ–Љ–µ–љ–љ—Г—О –љ–µ –њ–Њ–ї—Г—З–Є—В—Б—П.
–Ь–Њ–і–Є—Д–Є—Ж–Є—А–Њ–≤–∞—В—М DllEntryPoint-–њ—А–Њ—Ж–µ–і—Г—А—Г –Є –≤—Л–і–µ–ї—П—В—М –њ–∞–Љ—П—В—М –≤ –љ–µ–є —В–Њ–ґ–µ –љ–µ –њ–Њ–ї—Г—З–Є—В—Б—П: —Г —Н—В–Њ–є DLL —В–Њ—З–Ї–Є –≤—Е–Њ–і–∞ –њ–Њ–њ—А–Њ—Б—В—Г –љ–µ—В! (–•–Њ—В—П –Љ–Њ–ґ–љ–Њ —Б–і–µ–ї–∞—В—М).
–Ґ–Њ–ї—М–Ї–Њ –і–∞–ї—М–љ–µ–є—И–µ–µ –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–µ –Љ–Њ–ґ–µ—В –њ–Њ–Ї–∞–Ј–∞—В—М, –Ї–∞–Ї–Њ–є –≤–∞—А–Є–∞–љ—В –≤—Л–±—А–∞—В—М –Є –Ї–∞–Ї –±—Л—В—М.
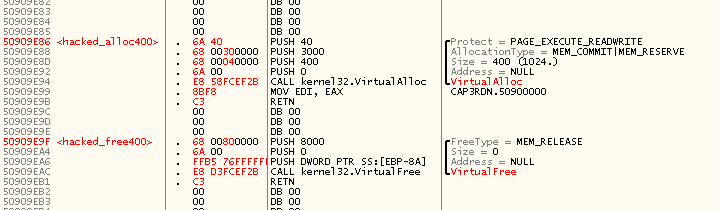
–Ф–ї—П –њ—А–Њ–≤–µ—А–Ї–Є —П –≤—Л–±—А–∞–ї –≤–∞—А–Є–∞–љ—В —Б VirtualAlloc, –њ—А–Є—З—С–Љ –љ–∞ –Ї–∞–ґ–і—Л–є –≤—Л–Ј–Њ–≤
RP_BITMAP1T01 –±—Г–і–µ—В –њ—А–Є—Е–Њ–і–Є—В—М—Б—П —А–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞–љ–Є–µ+–≤—Л–і–µ–ї–µ–љ–Є–µ, –∞ –Ј–∞—В–µ–Љ —А–∞–Ј—А–µ–Ј–µ—А–≤–Є—А–Њ–≤–∞–љ–Є–µ.
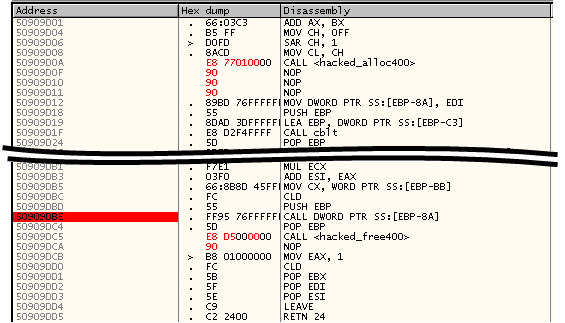
–ѓ –љ–∞–Ї–Є–і–∞–ї –њ—А—П–Љ–Њ –≤ –Њ—В–ї–∞–і—З–Є–Ї–µ –≤–Њ—В —В–∞–Ї–Є–µ –Ї—Г—Б–Њ—З–Ї–Є –Ї–Њ–і–∞, –Ї–Њ—В–Њ—А—Л–µ –≤—Л–і–µ–ї—П—О—В –Є –Њ—Б–≤–Њ–±–Њ–ґ–і–∞—О—В –њ–∞–Љ—П—В—М:
–Р –Ј–∞—В–µ–Љ –≤ –Њ—А–Є–≥–Є–љ–∞–ї—М–љ–Њ–Љ –Ї–Њ–і–µ –≤–Љ–µ—Б—В–Њ –≤—Л–і–µ–ї–µ–љ–Є—П/–Њ—Б–≤–Њ–±–Њ–ґ–і–µ–љ–Є—П —Г—З–∞—Б—В–Ї–∞ –љ–∞ —Б—В–µ–Ї–µ —Б–і–µ–ї–∞–ї –≤—Л–Ј–Њ–≤—Л –Љ–Њ–Є—Е –њ—А–Њ–±–љ—Л—Е –Ї—Г—Б–Њ—З–Ї–Њ–≤:
–Ч–∞–њ—Г—Б–Ї–∞–µ–Љ –љ–∞ –њ–µ—З–∞—В—М вАФ –Є –≤—Б—С —Б—А–∞–±–∞—В—Л–≤–∞–µ—В –љ–∞ —Г—А–∞. –Ч–∞–і–∞–љ–Є–µ —Г—Е–Њ–і–Є—В –љ–∞ –њ—А–Є–љ—В–µ—А, –њ—А–Є–љ—В–µ—А –љ–∞—З–Є–љ–∞–µ—В –Ј–∞–≤—Л–≤–∞—В—М, –њ—Л—В–∞—П—Б—М —А–∞—Б–Ї—А—Г—В–Є—В—М –Ј–µ—А–Ї–∞–ї–Њ, –∞ –њ–Њ—Б–ї–µ –њ—А–∞–≤–Є–ї—М–љ—Л—Е
—В–Њ—З–µ—З–љ—Л—Е —Г–і–∞—А–Њ–≤ вАФ —А–∞—Б–њ–µ—З–∞—В—Л–≤–∞–µ—В —В–Њ, —З—В–Њ –љ—Г–ґ–љ–Њ.
–Т–∞–ґ–љ—Л–µ –≤—Л–≤–Њ–і—Л:
- –Ь—Л –≤ –њ—А–Є–љ—Ж–Є–њ–µ –њ–Њ–±–µ–і–Є–ї–Є –Ї—А–Є–≤–Њ—Б—В—М –і—А–∞–є–≤–µ—А–∞, –њ—Г—Б—В—М –Є —З–µ—А–љ–Њ–≤—Л–Љ –њ—Г—В—С–Љ –њ–Њ–Ї–∞.
- –Т –і—А–∞–є–≤–µ—А–µ —В–Њ–ї—М–Ї–Њ 1 –Љ–µ—Б—В–Њ, –≥–і–µ –њ—А–Є–Љ–µ–љ–µ–љ–∞ –Ї–Њ–і–Њ–≥–µ–љ–µ—А–∞—Ж–Є—П –Є –≥–і–µ –≤ –Ї–∞—З–µ—Б—В–≤–µ –±—Г—Д–µ—А–∞ –і–ї—П –Ї–Њ–і–∞ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–ї—Б—П —Б—В–µ–Ї.
- –†–∞–Ј–Љ–µ—А —Н—В–Њ–≥–Њ –±—Г—Д–µ—А–∞ –≤—Б–µ–≥–і–∞ 0x400 –±–∞–є—В.
- –Ь–Њ–ґ–µ—В –±—Л—В—М –≤—Л–≤–Њ–і—Л 2 –Є 3 –Њ—И–Є–±–Њ—З–љ—Л вАФ –≤–µ–і—М —П —В–µ—Б—В–Є—А–Њ–≤–∞–ї –њ–Њ–Ї–∞ —В–Њ–ї—М–Ї–Њ –љ–∞ –С–ї–Њ–Ї–љ–Њ—В–µ, –∞ –њ–Њ–њ—Л—В–Ї–∞ –њ–µ—З–∞—В–Є —Б–ї–Њ–ґ–љ–Њ–є –≥—А–∞—Д–Є–Ї–Є –Љ–Њ–ґ–µ—В –і–∞—В—М –Њ–њ—П—В—М –Ї—А—Н—И.
¬Ђ–І—С—А–љ–Њ—Б—В—М¬ї —Н—В–Њ–≥–Њ —З–µ—А–љ–Њ–≤–Њ–≥–Њ —Б–њ–Њ—Б–Њ–±–∞ —Б–Њ—Б—В–Њ–Є—В –Є–Ј –і–≤—Г—Е –Ї–Њ–Љ–њ–Њ–љ–µ–љ—В–Њ–≤:
- –Р–±—Б–Њ–ї—О—В–љ–∞—П: –Љ—Л –љ–µ –Є–Љ–њ–Њ—А—В–Є—А—Г–µ–Љ —Д—Г–љ–Ї—Ж–Є–Є VirtualAlloc –Є VirtualFree, –Ї–∞–Ї —Н—В–Њ —Б–ї–µ–і–Њ–≤–∞–ї–Њ –±—Л –і–µ–ї–∞—В—М, –∞ –њ–Њ–Ї–∞ —З—В–Њ –ґ–µ—Б—В–Ї–Њ –≤—И–Є–ї–Є –Є—Е –∞–і—А–µ—Б–∞ –≤ —Б–≤–Њ–є –Ї–Њ–і–∞. –≠—В–Њ –Ј–љ–∞—З–Є—В, —З—В–Њ –њ–Њ–њ–∞–і–Є –і—А–∞–є–≤–µ—А –љ–∞ —З—Г—В—М –і—А—Г–≥—Г—О –≤–µ—А—Б–Є—О –Ю–° —Б –і—А—Г–≥–Њ–є kernel32.dll –Є–ї–Є –Њ–±–љ–Њ–≤–Є—Б—М —Б–∞–Љ–∞ kernel32.dll вАФ –Є –љ–Є—З–µ–≥–Њ —А–∞–±–Њ—В–∞—В—М –љ–µ –±—Г–і–µ—В.
- –Ю—В–љ–Њ—Б–Є—В–µ–ї—М–љ–∞—П: –Љ—Л –≤—Л–і–µ–ї—П–µ–Љ –Є –Њ—Б–≤–Њ–±–Њ–ґ–і–∞–µ–Љ –±–ї–Њ–Ї –њ–Њ –Ї–∞–ґ–і–Њ–Љ—Г —З–Є—Е—Г, —В–Њ –µ—Б—В—М —Г—Е—Г–і—И–∞–µ–Љ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М.
–І—В–Њ–±—Л –њ–Њ–љ—П—В—М, –љ–∞—Б–Ї–Њ–ї—М–Ї–Њ –Ї—А–Є—В–Є—З–µ–љ —В–∞–Ї–Њ–є –љ–∞–њ–ї–µ–≤–∞—В–µ–ї—М—Б–Ї–Є–є –њ–Њ–і—Е–Њ–і –Ї –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є, –∞ —В–∞–Ї–ґ–µ —А–∞–Ј–≤–µ—П—В—М —Б–Њ–Љ–љ–µ–љ–Є—П –Є–Ј –њ—Г–љ–Ї—В–∞ вДЦ4, —П —Е–Њ—З—Г –њ–Њ–≥–Њ–љ—П—В—М —Н—В–Њ—В —Д–Є–Ї—Б –≤ –і—А—Г–≥–Є—Е –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П—Е, –≤—Л–≤–Њ–і—П—Й–Є—Е —Б–ї–Њ–ґ–љ—Г—О —А–∞—Б—В—А–Њ–≤—Г—О –Є –≤–µ–Ї—В–Њ—А–љ—Г—О –≥—А–∞—Д–Є–Ї—Г. –Я–Њ—Б–Ї–Њ–ї—М–Ї—Г –њ–Њ—В–µ–љ—Ж–Є–∞–ї—М–љ—Л—Е –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є-–Ї–∞–љ–і–Є–і–∞—В–Њ–≤ –і–ї—П —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є—П –Љ–љ–Њ–≥–Њ, –Є –њ–Њ–і–Ї–ї—О—З–∞—В—М—Б—П –Њ—В–ї–∞–і—З–Є–Ї–Њ–Љ –Ї –Ї–∞–ґ–і–Њ–Љ—Г –Є –≤—Б—П–Ї–Є–є —А–∞–Ј –≤–љ–Њ—Б–Є—В—М –Њ–і–љ–Є –Є —В–µ –ґ–µ –њ—А–∞–≤–Ї–Є –≤ –Ї–Њ–і вАФ —Г—В–Њ–Љ–Є—В–µ–ї—М–љ–Њ, —П –њ—А–Њ–њ–∞—В—З–µ–љ–љ—Л–є –Њ–±—А–∞–Ј DLL –Љ–∞—В–µ—А–Є–∞–ї–Є–Ј—Г—О –≤ –≤–Є–і–µ DLL-—Д–∞–є–ї–∞.
–Э–Њ —А–∞–Ј –Љ—Л —Б–Њ–±–Є—А–∞–µ–Љ—Б—П –≥–Њ–љ—П—В—М –њ—А–Њ–њ–∞—В—З–µ–љ–љ—Л–є –і—А–∞–є–≤–µ—А –±–µ–Ј –Њ—В–ї–∞–і—З–Є–Ї–∞, –љ—Г–ґ–љ–Њ –ґ–µ –Ї–∞–Ї-—В–Њ –њ–Њ–ї—Г—З–∞—В—М –Њ—В –љ–µ–≥–Њ –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—О. –Я–Њ—Н—В–Њ–Љ—Г –і–Њ–±–∞–≤–ї—П–µ–Љ –≤ –љ–∞—З–∞–ї–Њ –Ї—Г—Б–Њ—З–Ї–∞
hacked_alloc400 –њ–∞—А—Г –Є–љ—Б—В—А—Г–Ї—Ж–Є–є –≤—Л–Ј–Њ–≤–∞
OutputDebugString, –љ—Г –Є —Б–∞–Љ—Г —Б—В—А–Њ—З–Ї—Г —З—Г—В—М –њ–Њ–Ј–ґ–µ –њ—А—П–Љ–Њ –≤ —Б–µ–Ї—Ж–Є—О –Ї–Њ–і–∞:
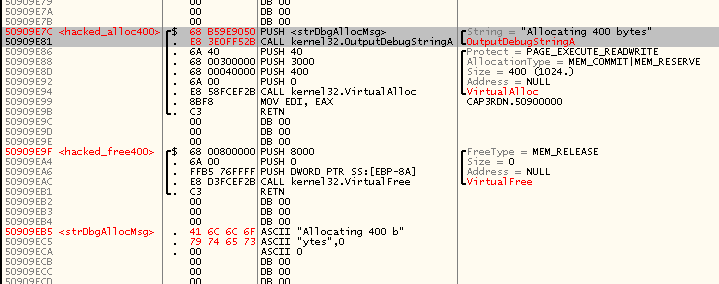
–Х—Б—В–µ—Б—В–≤–µ–љ–љ–Њ, –њ–Њ—Б–Ї–Њ–ї—М–Ї—Г –љ–∞—З–∞–ї–Њ –Ї—Г—Б–Њ—З–Ї–∞
hacked_alloc400 –њ–µ—А–µ–Љ–µ—Б—В–Є–ї–Њ—Б—М –љ–∞–Ј–∞–і –љ–∞ 10 –±–∞–є—В, –љ—Г–ґ–љ–Њ –њ–Њ–і–Ї–Њ—А—А–µ–Ї—В–Є—А–≤–Њ–∞—В—М –Є–љ—Б—В—А—Г–Ї—Ж–Є—О
call, –Ї–Њ—В–Њ—А–∞—П –≤—Л–Ј—Л–≤–∞–µ—В
hacked_alloc400.
–Я–Њ–Љ–Є–Љ–Њ —Н—В–Њ–≥–Њ, –µ—Б—В—М –µ—Й—С –Њ–і–Є–љ –Љ–Њ–Љ–µ–љ—В. –Ь–Њ–і—Г–ї—М
CAP3K.DLL –≤–Ј–∞–Є–Љ–Њ–і–µ–є—Б—В–≤—Г–µ—В —Б
CAP3RDN.DLL —З–µ—А–µ–Ј –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ —Н–Ї—Б–њ–Њ—А—В–Є—А—Г–µ–Љ—Л—Е –њ–Њ—Б–ї–µ–і–љ–µ–є —Д—Г–љ–Ї—Ж–Є–є.
–Т–Њ—В —З—В–Њ —Н–Ї—Б–њ–Њ—А—В–Є—А—Г–µ—В
CAP3RDN.DLL:
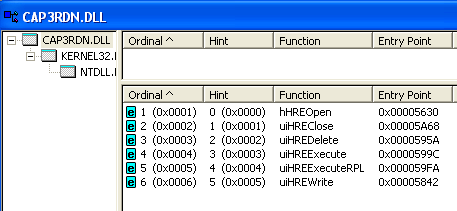
–Ш –≤–Њ—В –Ї–∞–Ї —Б—А–∞–Ј—Г –њ–Њ—Б–ї–µ –Ј–∞–≥—А—Г–Ј–Ї–Є (LoadLibrary, –≥–і–µ –Љ—Л —Б—В–∞–≤–Є–ї–Є –±—А–µ–Ї–њ–Њ–Є–љ—В –≤ –љ–∞—З–∞–ї–µ)
CAP3K.DLL –Њ—В–ї–Њ–ґ–µ–љ–љ–Њ –Є–Љ–њ–Њ—А—В–Є—А—Г–µ—В —Н—В–Є —Д—Г–љ–Ї—Ж–Є–Є:
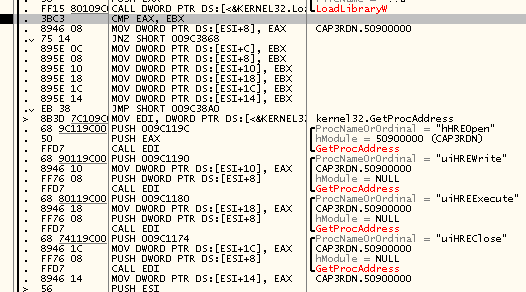
–Ґ–∞–Ї –≤–Њ—В, —П —Е–Њ—З—Г –њ–Њ–љ–∞–±–ї—О–і–∞—В—М, –Ї–∞–Ї –Ї–Њ—А—А–µ–ї–Є—А—Г–µ—В —Б–Њ–і–µ—А–ґ–Є–Љ–Њ–µ –≤—Л–≤–Њ–і–Є–Љ–Њ–≥–Њ –љ–∞ –њ–µ—З–∞—В—М –і–Њ–Ї—Г–Љ–µ–љ—В–∞ —Б –≤—Л–Ј–Њ–≤–∞–Љ–Є —Н—В–Є—Е —Д—Г–љ–Ї—Ж–Є–є, –Є –Ї–∞–Ї –≤—Л–Ј–Њ–≤—Л —Н—В–Є—Е —Д—Г–љ–Ї—Ж–Є–є —Б–Њ–Њ—В–љ–Њ—Б—П—В—Б—П —Б –≤—Л–Ј–Њ–≤–∞–Љ–Є –њ—А–Њ—Ж–µ–і—Г—А—Л
RP_BITMAP1T01 (–≤ –Ї–Њ—В–Њ—А–Њ–є –Љ—Л —В–µ–њ–µ—А—М –≤—Л–і–µ–ї—П–µ–Љ –њ–∞–Љ—П—В—М). –Ш –Ї–∞–Ї —Б–ї–µ–і—Б—В–≤–Є–µ —Г–Ј–љ–∞—В—М, —Б–Ї–Њ–ї—М–Ї–Њ —Ж–Є–Ї–ї–Њ–≤ –≤—Л–і–µ–ї–µ–љ–Є—П/–Њ—Б–≤–Њ–±–Њ–ґ–і–µ–љ–Є—П –њ—А–Є—Е–Њ–і–Є—В—Б—П –љ–∞ –Њ–±—А–∞–±–Њ—В–Ї—Г —А–∞–Ј–љ—Л—Е –і–Њ–Ї—Г–Љ–µ–љ—В–Њ–≤.
–Ф–ї—П —Н—В–Њ–≥–Њ —П ¬Ђ–њ–µ—А–µ—Е–≤–∞—З—Г¬ї, –≤–µ—А–љ–µ–µ –Љ–Њ–і–Є—Д–Є—Ж–Є—А—Г—О –њ—А–Њ–ї–Њ–≥–Є –≤—Б–µ—Е —Н—В–Є—Е —Н–Ї—Б–њ–Њ—А—В–Є—А—Г–µ–Љ—Л—Е —Д—Г–љ–Ї—Ж–Є–є, —Б–і–µ–ї–∞–≤ –≤—Л–≤–Њ–і –Њ—В–ї–∞–і–Њ—З–љ–Њ–≥–Њ —Б–Њ–Њ–±—Й–µ–љ–Є—П –≤ –љ–∞—З–∞–ї–µ –Ї–∞–ґ–і–Њ–є –Є–Ј –љ–Є—Е. –Я–µ—А–µ—Е–≤–∞—В –њ–Њ–Ї–∞–ґ—Г –љ–∞ –њ—А–Є–Љ–µ—А–µ
hHREOpen:
–Ф–ї–Є–љ–љ—Л–є –і–ґ–∞–Љ–њ (–Є–љ—Б—В—А—Г–Ї—Ж–Є—П) –Ј–∞–љ–Є–Љ–∞–µ—В 5 –±–∞–є—В–Њ–≤ (1 –±–∞–є—В –љ–∞ –Њ–њ–Ї–Њ–і –Є 4 –±–∞–є—В–∞ –Њ—В–љ–Њ—Б–Є—В–µ–ї—М–љ–Њ–µ —Б–Љ–µ—Й–µ–љ–Є–µ), –Ј–љ–∞—З–Є—В –њ–µ—А–≤—Л–µ 5 –±–∞–є—В–Њ–≤ —Д—Г–љ–Ї—Ж–Є–Є –љ—Г–ґ–љ–Њ –њ–µ—А–µ–љ–µ—Б—В–Є –≤ –і—А—Г–≥–Њ–µ –Љ–µ—Б—В–Њ.
–°—В–∞–≤–Є–Љ –≤ –Њ—А–Є–≥–Є–љ–∞–ї—М–љ–Њ–є —Д—Г–љ–Ї—Ж–Є–Є –Љ–µ—В–Ї—Г (
contOf_hHREOpen), –Ї—Г–і–∞ –Љ—Л —Б–Њ–±–Є—А–∞–µ–Љ—Б—П –≤–µ—А–љ—Г—В—М—Б—П –Є–Ј –њ–µ—А–µ–љ–µ—Б—С–љ–љ–Њ–≥–Њ –Ї—Г—Б–Њ—З–Ї–∞:
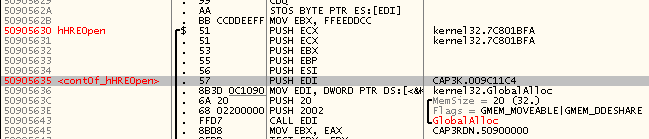
–Т –Ї–Њ–љ—Ж–µ —Б–µ–Ї—Ж–Є–Є –Ї–Њ–і–∞ –љ–∞–±–Є–≤–∞–µ–Љ –Ї—Г—Б–Њ—З–µ–Ї –Ї–Њ–і–∞ –Є–Ј 5 –Њ—А–Є–≥–Є–љ–∞–ї—М–љ—Л—Е push-–Є–љ—Б—В—А—Г–Ї—Ж–Є–є (–Ї–Њ—В–Њ—А—Л–µ –±—Г–і—Г—В –Ј–∞–Љ–µ–љ–µ–љ—Л –љ–∞ –і–ґ–∞–Љ–њ), –њ–∞—А—Г –Є–љ—Б—В—А—Г–Ї—Ж–Є–є –≤—Л–Ј–Њ–≤–∞
OutputDebugString –Є –≤–Њ–Ј–≤—А–∞—В –Ї –Њ—А–Є–≥–Є–љ–∞–ї—М–љ–Њ–Љ—Г –Ї–Њ–і—Г:

–Ш –≤ –љ–∞—З–∞–ї–µ –Њ—А–Є–≥–Є–љ–∞–ї—М–љ–Њ–є —Д—Г–љ–Ї—Ж–Є–Є —Б—В–∞–≤–Є–Љ –њ–µ—А–µ—Е–Њ–і –љ–∞ —Б–Њ–±—Б—В–≤–µ–љ–љ—Л–є –Ї—Г—Б–Њ—З–µ–Ї:

–Ю–±—А–∞—В–Є—В–µ –≤–љ–Є–Љ–∞–љ–Є–µ –љ–∞ –Љ–∞–ї–µ–љ—М–Ї—Г—О —Е–Є—В—А–Њ—Б—В—М: —Б—В—А–Њ—З–Ї—Г ¬ЂhHREOpen¬ї (–∞–і—А–µ—Б
5090B070) —П –≤–Ј—П–ї –≤ –і–Є—А–µ–Ї—В–Њ—А–Є–Є —Н–Ї—Б–њ–Њ—А—В–∞ DLL-–Љ–Њ–і—Г–ї—П вАФ –Ј–∞—З–µ–Љ –і—Г–±–ї–Є—А–Њ–≤–∞—В—М —В–Њ, —З—В–Њ —Г–ґ–µ –µ—Б—В—М.
–Р–љ–∞–ї–Њ–≥–Є—З–љ—Л–Љ –Њ–±—А–∞–Ј–Њ–Љ –њ–µ—А–µ—Е–≤–∞—В—Л–≤–∞–µ–Љ –≤—Б–µ –Њ—Б—В–∞–ї—М–љ—Л–µ —Н–Ї—Б–њ–Њ—А—В–Є—А—Г–µ–Љ—Л–µ —Д—Г–љ–Ї—Ж–Є–Є –Є –і–µ–ї–∞–µ–Љ —В–∞–Ї, —З—В–Њ –Ї–∞–ґ–і–∞—П –≤—Л–≤–Њ–і–Є—В –Њ—В–ї–∞–і–Њ—З–љ—Г—О —Б—В—А–Њ–Ї—Г –≤ –Љ–Њ–Љ–µ–љ—В –≤—Л–Ј–Њ–≤–∞. –Т–Њ—В –≤—Б–µ –Ї—Г—Б–Њ—З–Ї–Є –і–ї—П –≤—Б–µ—Е –њ–µ—А–µ—Е–≤–∞—З–µ–љ–љ—Л—Е —Д—Г–Ї–љ—Ж–Є–є:

–Т –њ—А–Є–љ—Ж–Є–њ–µ –Љ–Њ–ґ–љ–Њ –±—Л–ї–Њ (–Є —Н—В–Њ –±—Л–ї–Њ –±—Л –і–∞–ґ–µ –Ї—А–∞—Б–Є–≤–µ–µ!) –њ–µ—А–µ—Е–≤–∞—В–Є—В—М –љ–∞—З–∞–ї–∞ —Д—Г–љ–Ї—Ж–Є–є –Є–љ–∞—З–µ: –љ–µ —В—А–Њ–≥–∞—В—М –Є –љ–µ –Љ–Њ–і–Є—Д–Є—Ж–Є—А–Њ–≤–∞—В—М –њ—А–Њ–ї–Њ–≥–Є, –∞ –њ—А–Њ—Б—В–Њ –Љ–Њ–і–Є—Д–Є—Ж–Є—А–Њ–≤–∞—В—М RVA-—Г–Ї–∞–Ј–∞—В–µ–ї–Є –≤ —В–∞–±–ї–Є—Ж–µ —Н–Ї—Б–њ–Њ—А—В–∞, –њ–µ—А–µ–≤–µ—И–∞–≤ –Є—Е –љ–∞ —Б–Њ–±—Б—В–≤–µ–љ–љ—Л–µ –њ–µ—А–µ—Е–Њ–і–љ–Є—З–Ї–Є, –Ї–Њ—В–Њ—А—Л–µ —В–Њ–ї—М–Ї–Њ –≤—Л–≤–Њ–і—П—В –Њ—В–ї–∞–і–Њ—З–љ—Л–µ —Б—В—А–Њ–Ї–Є –Є —Б—А–∞–Ј—Г –њ—А—Л–≥–∞—О—В –љ–∞ –Њ—А–Є–≥–Є–љ–∞–ї—М–љ—Л–µ –љ–µ—В—А–Њ–љ—Г—В—Л–µ –њ—А–Њ–ї–Њ–≥–Є.
–Ш —Б–Њ—Е—А–∞–љ—П–µ–Љ –њ—А–Њ–њ–∞—В—З–µ–љ–љ—Л–є DLL —Д–∞–є–ї:
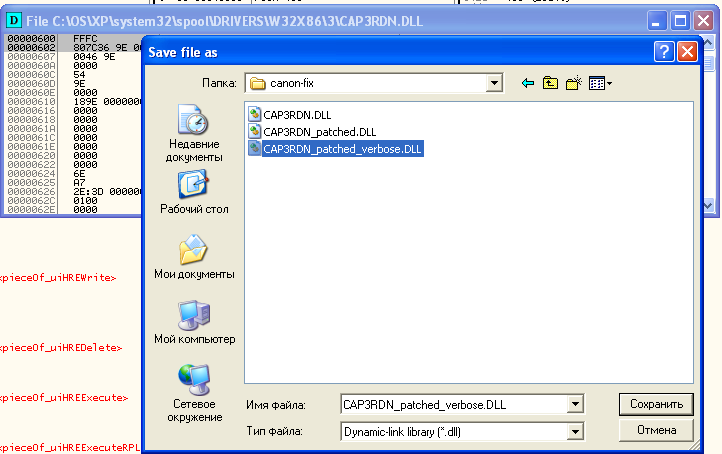
–ѓ —Б–Њ—Е—А–∞–љ–Є–ї –і–≤–∞ —Д–∞–є–ї–∞:
- CAP3RDN_patched.DLL вАФ —Б –Є—Б–њ—А–∞–≤–ї–µ–љ–љ—Л–Љ –±–∞–≥–Њ–Љ –њ–∞–і–µ–љ–Є—П –љ–Њ –±–µ–Ј –≤—Л–≤–Њ–і–∞ –Њ—В–ї–∞–і–Њ—З–љ—Л—Е —Б–Њ–Њ–±—Й–µ–љ–Є–є.
- CAP3RDN_patched_verbose.DLL вАФ –Є—Б–њ—А–∞–≤–ї–µ–љ–љ—Л–є + –≤—Л–≤–Њ–і –Њ—В–ї. —Б–Њ–Њ–±—Й–µ–љ–Є–є —Б –њ–Њ–Љ–Њ—Й—М—О OutputDebugString.
–Ґ–µ–њ–µ—А—М –њ–Њ–і–Љ–µ–љ—П–µ–Љ –Њ—А–Є–≥–Є–љ–∞–ї—М–љ—Л–є –і—А–∞–є–≤–µ—А –≤ system32: –±–ї–∞–≥–Њ –Њ–љ –љ–µ –Њ—Е—А–∞–љ—П–µ—В—Б—П SFP –Є –љ–µ –Є–Љ–µ–µ—В —Ж–Є—Д—А–Њ–≤–Њ–є –њ–Њ–і–њ–Є—Б–Є (–Ї–Њ—В–Њ—А–∞—П –±—Л –љ–∞—А—Г—И–Є–ї–∞—Б—М –Њ—В –љ–∞—И–Є—Е –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є–є).
–Ґ–µ–њ–µ—А—М –Љ—Л –Љ–Њ–ґ–µ–Љ
–Є–Ј –ї—О–±–Њ–≥–Њ –њ—А–Є–ї–Њ–ґ–µ–љ–Є—П –≤—Л–≤–Њ–і–Є—В—М —З—В–Њ-–ї–Є–±–Њ –љ–∞ –њ–µ—З–∞—В—М –Є –њ—А–Є –њ–Њ–Љ–Њ—Й–Є –њ—А–Њ–≥—А–∞–Љ–Љ—Л
DebugView (–Є–ї–Є –ї—О–±–Њ–≥–Њ –∞–љ–∞–ї–Њ–≥–∞) —Б–Љ–Њ—В—А–µ—В—М, –Ї–∞–Ї–Є–µ —Д—Г–љ–Ї—Ж–Є–Є –Є–Ј –і—А–∞–є–≤–µ—А–∞ –њ–µ—З–∞—В–Є –і—С—А–≥–∞—О—В—Б—П, —Б–Ї–Њ–ї—М–Ї–Њ —А–∞–Ј, –Є —Б–Ї–Њ–ї—М–Ї–Њ —В–∞–Љ —Ж–Є–Ї–ї–Њ–≤ –≤—Л–і–µ–ї–µ–љ–Є—П/–≤—Л—Б–≤–Њ–±–Њ–ґ–і–µ–љ–Є—П –њ–∞–Љ—П—В–Є.
–Т–Њ—В –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ —В–µ—Б—В–Њ–≤ (—Б–ї–µ–≤–∞ вАФ —З—В–Њ –њ–µ—З–∞—В–∞–µ–Љ, —Б–њ—А–∞–≤–∞ вАФ –ї–Њ–≥ –≤—Л–Ј–Њ–≤–Њ–≤ —Н–Ї—Б–њ–Њ—А—В–Є—А—Г–µ–Љ—Л—Е —Д-—Ж–Є–є –Є —Ж–Є–Ї–ї–Њ–≤ –≤—Л–і–µ–ї–µ–љ–Є—П –њ–∞–Љ—П—В–Є):
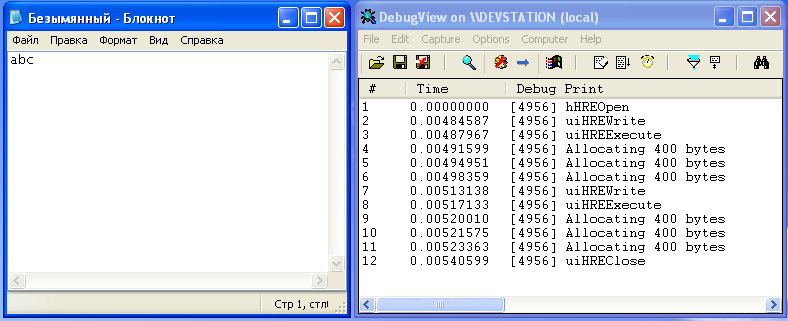
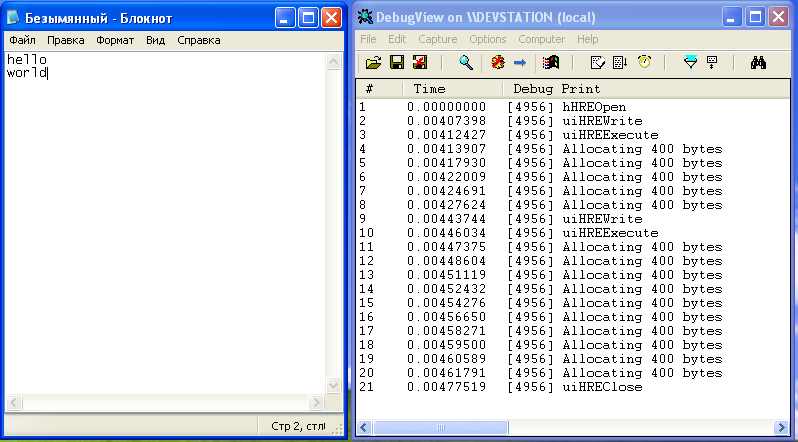
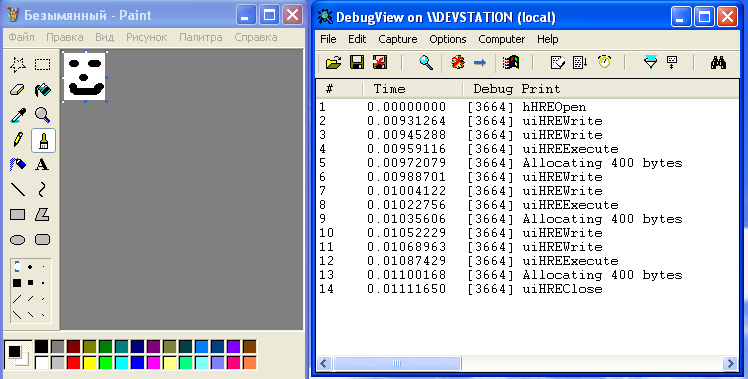
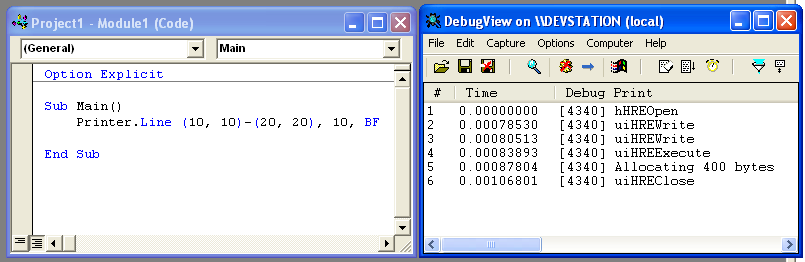
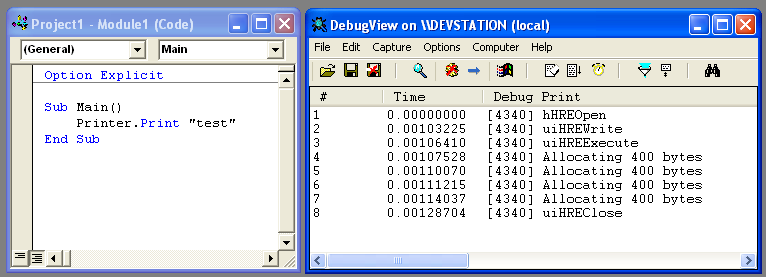
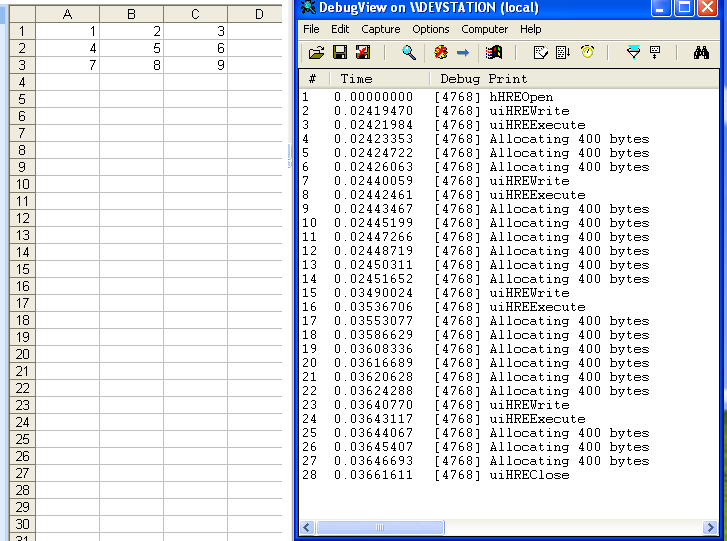
–Ъ–∞–Ї –Љ–Њ–ґ–љ–Њ —Г–≤–Є–і–µ—В—М –љ–∞ —Н—В–Є—Е —В–µ—Б—В–Њ–≤—Л—Е –њ—А–Є–Љ–µ—А–∞—Е, –љ–µ —В–∞–Ї —Г–ґ –Є –Љ–љ–Њ–≥–Њ —Ж–Є–Ї–ї–Њ–≤ –≤—Л–і–µ–ї–µ–љ–Є—П –њ–∞–Љ—П—В–Є (–≤ –≤—Л–Ј–Њ–≤–∞—Е
RP_BITMAP1T01) –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –њ—А–Є –њ–µ—З–∞—В–Є —З–µ–≥–Њ-—В–Њ –њ—А–Є–Љ–Є—В–Є–≤–љ–Њ–≥–Њ. –Э–∞–њ—А–Є–Љ–µ—А –Љ–Њ–ґ–љ–Њ —Б–і–µ–ї–∞—В—М –≤—Л–≤–Њ–і, —З—В–Њ –љ–∞ –Ї–∞–ґ–і—Г—О –≤—Л–≤–Њ–і–Є–Љ—Г—О –±—Г–Ї–≤—Г –њ—А–Є—Е–Њ–і–Є—В—Б—П –Њ–і–Є–љ —В–∞–Ї–Њ–є —Ж–Є–Ї–ї (–љ–Њ –љ–µ–Ї–Њ—В–Њ—А—Л–є —Б–Њ—Д—В –њ–µ—З–∞—В–∞–µ—В –љ–µ–Ї–Њ—В–Њ—А—Л–µ –≥—А—Г–њ–њ—Л –±—Г–Ї–≤ –і–≤–∞–ґ–і—Л?).
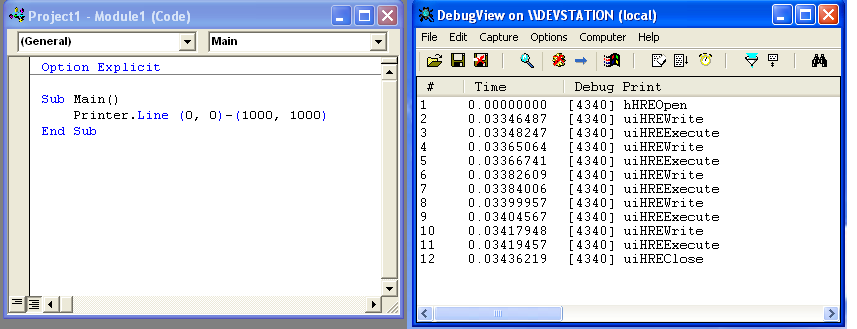
–Ы–∞–і–љ–Њ, —Н—В–Њ –≤—Б—С –±–∞–ї–Њ–≤—Б—В–≤–Њ. –Э–∞–њ–µ—З–∞—В–∞–µ–Љ —З—В–Њ-–љ–Є–±—Г–і—М —В—П–ґ–µ–ї–Њ–≤–µ—Б–љ–Њ–µ:
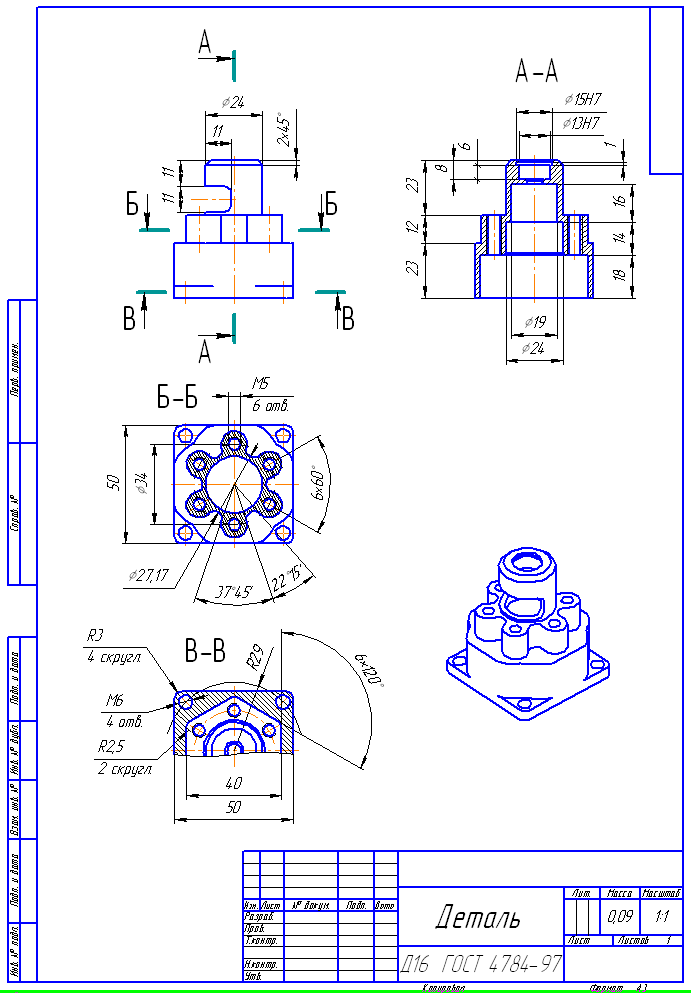
–Т—Л–≤–Њ–і —Н—В–Њ–≥–Њ —З–µ—А—В–µ–ґ–∞ –≤—Л–і–∞–ї –∞–ґ 153 —В—Л—Б—П—З–Є –Њ—В–ї–∞–і–Њ—З–љ—Л—Е —Б—В—А–Њ–Ї –≤
DebugView! –Ш –Њ–±—А–∞–±–Њ—В–Ї–∞ –Ј–∞–і–∞–љ–Є—П –Ј–∞–љ—П–ї–∞ –і—А–∞–є–≤–µ—А–Њ–Љ 20 —Б–µ–Ї—Г–љ–і! –Ф–ї—П –ґ–µ–ї–∞—О—Й–Є—Е —Б–∞–Љ–Њ—Б—В–Њ—П—В–µ–ї—М–љ–Њ –њ–Њ–Ї–Њ–њ–∞—В—М—Б—П –≤ —Н—В–Њ–Љ –ї–Њ–≥–µ, –≤–Њ—В –Њ–љ:
 prn_log_of_drawing.zip
prn_log_of_drawing.zip- –Ы–Њ–≥ –≤—Л–≤–Њ–і–∞ –Њ—В–ї–∞–і–Њ—З–љ—Л—Е —Б–Њ–Њ–±—Й–µ–љ–Є–є –њ—А–Є –њ–µ—З–∞—В–Є —З–µ—А—В–µ–ґ–∞
- (1.01 –Ь–Є–С) –°–Ї–∞—З–Є–≤–∞–љ–Є–є: 286
–Э–Њ —А–∞–љ–Њ –і—Г–Љ–∞—В—М, —З—В–Њ —В–∞–Ї–Њ–µ –њ–∞–і–µ–љ–Є–µ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є –≤—Л–Ј–≤–∞–љ–Њ –љ–∞—И–Є–Љ —Д–Є–Ї—Б–Њ–Љ (–Љ–љ–Њ–≥–Њ–Ї—А–∞—В–љ—Л–Љ –≤—Л–Ј–Њ–≤–Њ–Љ VirtualAlloc/VirtualFree) вАФ —Б–Ї–Њ—А–µ–µ –≤—Б–µ–≥–Њ bottleneck –≤ –і–∞–љ–љ–Њ–Љ —Б–ї—Г—З–∞–µ –Ї—А–Њ–µ—В—Б—П –≤ —Б–∞–Љ–Њ–Љ –≤—Л–≤–Њ–і–µ –Њ—В–ї–∞–і–Њ—З–љ–Њ–є –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Є.
–°–і–µ–ї–∞–µ–Љ –µ—Й—С –Њ–і–љ—Г –њ—А–Њ–њ–∞—В—З–µ–љ–љ—Г—О –≤–µ—А—Б–Є—О –і—А–∞–є–≤–µ—А–∞, —Г–±—А–∞–≤ –≤—Л–≤–Њ–і –Њ—В–ї–∞–і–Њ—З–љ–Њ–є –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Є –Њ—В–Њ–≤—Б—О–і—Г, –Ї—А–Њ–Љ–µ
hHREOpen –Є
uiHREClose (–Ї–Њ—В–Њ—А—Л–µ –≤—Л–Ј—Л–≤–∞—О—В—Б—П –≤ —Б–∞–Љ–Њ–Љ –љ–∞—З–∞–ї–µ –Є –≤ —Б–∞–Љ–Њ–Љ –Ї–Њ–љ—Ж–µ –Њ–±—А–∞–±–Њ—В–Ї–Є –Ј–∞–і–∞–љ–Є—П).
–Я–µ—З–∞—В–∞–µ–Љ —В–Њ—В –ґ–µ —Б–∞–Љ—Л–є —З–µ—А—В—С–ґ –Є –њ–Њ–ї—Г—З–∞–µ–Љ —Г–ґ–µ —Б–Њ–≤—Б–µ–Љ –љ–µ —В–∞–Ї—Г—О —Б—В—А–∞—И–љ—Г—О –Ї–∞—А—В–Є–љ—Г:
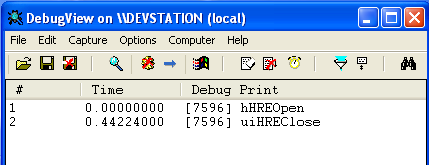
–І—Г—В—М –Љ–µ–љ—М—И–µ, —З–µ–Љ –њ–Њ–ї–Њ–≤–Є–љ–∞ —Б–µ–Ї—Г–љ–і—Л вАФ –≤–њ–Њ–ї–љ–µ —Б–µ–±–µ –њ—А–Є–µ–Љ–ї–µ–Љ—Л–є —А–µ–Ј—Г–ї—М—В–∞—В.
–Ы–∞–і–љ–Њ, –Љ–Њ–ґ–љ–Њ —Б—З–Є—В–∞—В—М –ї–µ—З–µ–љ–Є–µ —Г—Б–њ–µ—И–љ—Л–Љ. –Я–Њ—Б–ї–µ —В–Њ–≥–Њ, –Ї–∞–Ї –Њ—Б—В–∞–ї—М–љ—Л–µ –њ—А–Њ–±–ї–µ–Љ—Л —Б –њ—А–Є–љ—В–µ—А–Њ–Љ –±—Г–і—Г—В —Г—Б—В—А–∞–љ–µ–љ—Л, –Љ–Њ–ґ–љ–Њ –±—Г–і–µ—В –≤–µ—А–љ—Г—В—М—Б—П –Є —Г–ї—Г—З—И–Є—В—М —Д–Є–Ї—Б, –≤—Л–љ–µ—Б—П –≤—Л–і–µ–ї–µ–љ–Є–µ –њ–∞–Љ—П—В–Є ¬Ђ–Ј–∞ —Б–Ї–Њ–±–Ї–Є¬ї, –њ—А–Є–Љ–µ–љ–Є–≤ TLS –і–ї—П —Е—А–∞–љ–µ–љ–Є—П —Г–Ї–∞–Ј–∞—В–µ–ї—П –љ–∞ 400h-–±–∞–є—В–љ—Л–є –±—Г—Д–µ—А.
–Р –њ–Њ–Ї–∞ –љ—Г–ґ–љ–Њ –і–Њ–≤–µ—Б—В–Є –≤—Л–ї–µ—З–µ–љ–љ—Л–є –і—А–∞–є–≤–µ—А –і–Њ –Ї–Њ–љ–і–Є—Ж–Є–Є, —Б–і–µ–ї–∞–≤ –љ–Њ—А–Љ–∞–ї—М–љ—Л–є –Є–Љ–њ–Њ—А—В —Д—Г–љ–Ї—Ж–Є–є
VirtualAlloc –Є
VirtualFree.
–°–µ–є—З–∞—Б —Г –љ–∞—Б 5 –Є–Љ–њ–Њ—А—В–Њ–≤ –Є–Ј
kernel32.dll, –∞ –±—Г–і–µ—В 7. –Ф–ї—П —Н—В–Њ–≥–Њ —А–∞–Ј–Љ–µ—А —В–∞–±–ї–Є—Ж—Л IAT –Є —В–∞–±–ї–Є—Ж—Л –ї—Г–Ї–∞–њ–Њ–≤ –љ—Г–ґ–љ–Њ —Г–≤–µ–ї–Є—З–Є—В—М –љ–∞ 2 —П—З–µ–є–Ї–Є (–Ї–∞–ґ–і—Г—О). –Ґ—Г—В –љ–∞—Б –ґ–і—С—В –њ–µ—А–≤–∞—П —В—А—Г–і–љ–Њ—Б—В—М: —В–∞–±–ї–Є—Ж–∞ IAT, –≤ –Ї–Њ—В–Њ—А—Г—О –Ј–∞–≥—А—Г–Ј—З–Є–Ї —А–∞—Б—Б—В–∞–≤–Є—В –∞–і—А–µ—Б–∞ –Є–Љ–њ–Њ—А—В–Є—А—Г–µ–Љ—Л—Е —Д—Г–љ–Ї—Ж–Є–є, —А–∞—Б–њ–Њ–ї–Њ–ґ–µ–љ–љ–∞—П (–≤ –і–∞–љ–љ–Њ–Љ —Б–ї—Г—З–∞–µ) –≤ —Б–∞–Љ–Њ–Љ –љ–∞—З–∞–ї–µ —Б–µ–Ї—Ж–Є–Є –Ї–Њ–і–∞, –љ–µ –Љ–Њ–ґ–µ—В —А–∞—Б—В–Є –≤–љ–Є–Ј, –њ–Њ—В–Њ–Љ—Г —З—В–Њ —В–∞–Љ –ї–µ–ґ–∞—В –Ї–∞–Ї–Є–µ-—В–Њ –љ–µ–њ–Њ–љ—П—В–љ—Л–µ –і–∞–љ–љ—Л–µ, –Є —В–∞–±–ї–Є—Ж–∞ –ї—Г–Ї–∞–њ–Њ–≤ —В–Њ–ґ–µ –љ–µ –Љ–Њ–ґ–µ—В —А–∞—Б—В–Є –≤–љ–Є–Ј, –њ–Њ—В–Њ–Љ—Г —З—В–Њ —Б–ї–µ–і–Њ–Љ –Ј–∞ –љ–µ–є –Є–і—С—В —Ж–µ–њ–Њ—З–Ї–∞ —Б—В—А—Г–Ї—В—Г—А
IMAGE_IMPORT_BY_NAME.
–¶–µ–њ–Њ—З–Ї—Г —Б—В—А—Г–Ї—В—Г—А
IMAGE_IMPORT_BY_NAME –Љ—Л –ї–µ–≥–Ї–Њ –Љ–Њ–ґ–µ–Љ –њ–Њ–і–≤–Є–љ—Г—В—М (–њ–Њ–і–њ—А–∞–≤–Є–≤ –Є—Е RVA –≤ IAT –Є —В–∞–±–ї–Є—Ж–µ –ї—Г–Ї–∞–њ–Њ–≤), –∞ –≤–Њ—В —З—В–Њ –Ј–∞ –і–∞–љ–љ—Л–µ –Є–і—Г—В —Б–ї–µ–і–Њ–Љ –Ј–∞ IAT вАФ —Б–Њ–≤–µ—А—И–µ–љ–љ–Њ –љ–µ —П—Б–љ–Њ. –Я—А–Є—З—С–Љ —В–∞–Љ –Є–і—С—В –±–Њ–ї—М—И–Њ–є –±–ї–Њ–Ї –і–∞–љ–љ—Л—Е, –≤ –Ї–Њ—В–Њ—А–Њ–Љ –µ—Б—В—М –і–∞–ґ–µ —Б—В—А–Њ—З–Ї–∞
Win32 Render for CAPT. –Я—А–Є—З—С–Љ —П –Ј–∞—Б—В–∞–≤–Є–ї OllyDbg –њ–Њ–Є—Б–Ї–∞—В—М –≤—Б–µ —Б—Б—Л–ї–Ї–Є –Ї –Є–љ—В–µ—А–µ—Б—Г—О—Й–µ–Љ—Г –±–ї–Њ–Ї—Г –Є –Њ—В–ї–∞–і—З–Є–Ї –љ–µ –љ–∞—И—С–ї
–љ–Є –Њ–і–љ–Њ–є! –І—В–Њ –≤—Л–≥–ї—П–і–Є—В –њ–Њ–і–Њ–Ј—А–Є—В–µ–ї—М–љ–Њ –Є –љ–∞–≤–Њ–і–Є—В –љ–∞ –Љ—Л—Б–ї—М, —З—В–Њ –і–ї—П –і–Њ—Б—В—Г–њ–∞ –Ї —Н—В–Є–Љ –і–∞–љ–љ—Л–Љ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –љ–µ–њ—А—П–Љ–Њ–є –і–Њ—Б—В—Г–њ —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ –∞–і—А–µ—Б–љ–Њ–є –∞—А–Є—Д–Љ–µ—В–Є–Ї–Є, –Ї–Њ—В–Њ—А—Г—О –Њ—В–ї–∞–і—З–Є–Ї, —П—Б–љ–Њ–µ –і–µ–ї–Њ, —Б–≤–Њ–Є–Љ –і–Њ–≤–Њ–ї—М–љ–Њ-—В–∞–Ї–Є –њ—А–Њ—Б—В—Л–Љ –∞–љ–∞–ї–Є–Ј–Њ–Љ –Њ–±–љ–∞—А—Г–ґ–Є—В—М –љ–µ –Љ–Њ–ґ–µ—В.
–Т–њ–Њ–ї–љ–µ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ, —З—В–Њ —Н—В–Њ –≤ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ –љ–µ–Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ–Њ–µ –Љ—Г—Б–Њ—А–љ–Њ–µ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–Њ, –Є –Љ–Њ–ґ–љ–Њ –±—Л–ї–Њ –±—Л —А–Є—Б–Ї–љ—Г—В—М –Є –Ј–∞—Е–≤–∞—В–Є—В—М 8 –±–∞–є—В –Є–Ј —Н—В–Њ–є –Њ–±–ї–∞—Б—В–Є –њ–Њ–і —Б–≤–Њ–Є –љ—Г–ґ–і—Л. –Э–Њ –Љ—Л –љ–µ –±—Г–і–µ–Љ —А–Є—Б–Ї–Њ–≤–∞—В—М –Є –њ–Њ–є–і—С–Љ –і—А—Г–≥–Є–Љ –њ—Г—В—С–Љ.
–Т PE-–Ј–∞–≥–Њ–ї–Њ–≤–Ї–µ –љ–∞—Е–Њ–і–Є—В—Б—П RVA-—Г–Ї–∞–Ј–∞—В–µ–ї—М –љ–∞ –љ–∞—З–∞–ї–Њ —В–∞–±–ї–Є—Ж—Л –і–µ—Б–Ї—В—А–Є–њ—В–Њ—А–Њ–≤ –Є–Љ–њ–Њ—А—В–∞. –Ъ–∞–ґ–і–Њ–є –Є–Љ–њ–Њ—А—В–Є—А—Г–µ–Љ–Њ–є DLL-–±–Є–±–ї–Є–Њ—В–µ–Ї–µ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –Њ—В–і–µ–ї—М–љ—Л–є –і–µ—Б–Ї—А–Є–њ—В–Њ—А (—Н–ї–µ–Љ–µ–љ—В) –≤ —В–∞–±–ї–Є—Ж–µ –і–µ—Б–Ї—А–Є–њ—В–Њ—А–Њ–≤ –Є–Љ–њ–Њ—А—В–∞. –Э–Њ, —Е–Њ—В—М —Н—В–Њ –Њ–±—Л—З–љ–Њ –љ–µ –њ—А–Є–љ—П—В–Њ, –љ–Є—З–µ–≥–Њ –љ–µ –Љ–µ—И–∞–µ—В –і–ї—П –Њ–і–љ–Њ–є –Є —В–Њ–є –ґ–µ –±–Є–±–ї–Є–Њ—В–µ–Ї–Є –Є–Љ–µ—В—М –±–Њ–ї–µ–µ –Њ–і–љ–Њ–≥–Њ –і–µ—Б–Ї—А–Є–њ—В–Њ—А–∞ –Є–Љ–њ–Њ—А—В–∞. –Ю–±—Л—З–љ–Њ —Н—В–Є–Љ –≥—А–µ—И–Є—В –ї–Є–љ–Ї–µ—А Borland'–Њ–≤—Б–Ї–Є—Е –њ—А–Њ–і—Г–Ї—В–Њ–≤ (Delphi –Є C++ Builder).

–†–∞–Ј –Љ—Л –љ–µ –Љ–Њ–ґ–µ–Љ —Г–≤–µ–ї–Є—З–Є—В—М —А–∞–Ј–Љ–µ—А IAT, –Љ—Л —Б–і–µ–ї–∞–µ–Љ –≤—В–Њ—А—Г—О IAT –Є –≤—В–Њ—А—Г—О —В–∞–±–ї–Є—Ж—Г –ї—Г–Ї–∞–њ–Њ–≤ –Є —А–∞–Ј–Љ–µ—Б—В–Є–Љ –Є—Е —В–∞–Љ, –≥–і–µ –љ–∞–Љ —Г–і–Њ–±–љ–Њ –Є –љ–Є—З–µ–≥–Њ –љ–µ –Љ–µ—И–∞–µ—В (–∞ –Є–Љ–µ–љ–љ–Њ вАФ –≤ –Ї–Њ–љ—Ж–µ —Б–µ–Ї—Ж–Є–Є). –Э–Њ —А–∞—Б—И–Є—А–Є—В—М —Б–∞–Љ—Г —В–∞–±–ї–Є—Ж—Г –і–µ—Б–Ї—А–Є–њ—В–Њ—А–Њ–≤ –Љ–µ—И–∞–µ—В —Б–ї–µ–і—Г—О—Й–∞—П –њ—А—П–Љ–Њ –Ј–∞ —В–∞–±–ї–Є—Ж–µ–є –і–µ—Б–Ї—А–Є–њ—В–Њ—А–Њ–≤ –Є–Љ–њ–Њ—А—В–∞ —В–∞–±–ї–Є—Ж–∞ –ї—Г–Ї–∞–њ–Њ–≤ –і–ї—П –њ–µ—А–≤–Њ–≥–Њ –і–µ—Б–Ї—А–Є–њ—В–Њ—А–∞.
–Я—Г—Б—В–Њ–є (—В–µ—А–Љ–Є–љ–Є—А—Г—О—Й–Є–є) –і–µ—Б–Ї—А–Є–њ—В–Њ—А –њ—А–Є–і—С—В—Б—П —Б–і–≤–Є–љ—Г—В—М –≤–љ–Є–Ј вАФ –Њ–љ –Ј–∞–є–Љ—С—В –Љ–µ—Б—В–Њ, –Ї–Њ—В–Њ—А–Њ–µ —Б–µ–є—З–∞—Б –Ј–∞–љ–Є–Љ–∞–µ—В ILT –і–ї—П –њ–µ—А–≤–Њ–≥–Њ –і–µ—Б–Ї—А–Є–њ—В–Њ—А–∞. –Ю–љ–∞ (ILT вАФ —В–∞–±–ї–Є—Ж–∞ –ї—Г–Ї–∞–њ–Њ–≤) –Є–Љ–µ–µ—В —А–∞–Ј–Љ–µ—А 6 DWORD-–Њ–≤, —З—В–Њ –і–Њ—Б—В–∞—В–Њ—З–љ–Њ –і–ї—П –њ–Њ–Љ–µ—Й–µ–љ–Є—П –љ–∞ –µ—С –Љ–µ—Б—В–Њ —Б–і–≤–Є–≥–∞–µ–Љ–Њ–≥–Њ –і–µ—Б–Ї—А–Є–њ—В–Њ—А–∞, —А–∞–Ј–Љ–µ—А –Ї–Њ—В–Њ—А–Њ–≥–Њ вАФ 5 DWORD-–Њ–≤. ILT –Љ—Л –њ–µ—А–µ–љ–µ—Б—С–Љ –≤–љ–Є–Ј, –∞ —Ж–µ–њ–Њ—З–Ї—Г –Є–Ј —Б—В—А—Г–Ї—В—Г—А
IMAGE_IMPORT_BY_NAME –і–ї—П –њ–µ—А–≤–Њ–≥–Њ –і–µ—Б–Ї—А–Є–њ—В–Њ—А–∞ –Љ–Њ–ґ–љ–Њ –Њ—Б—В–∞–≤–Є—В—М —В–∞–Љ, –≥–і–µ –Њ–љ–∞ —Б–µ–є—З–∞—Б.
–°–∞–Љ –і–µ—Б–Ї—А–Є–њ—В–Њ—А –Є–Љ–њ–Њ—А—В–∞ –Є–Љ–µ–µ—В —В–∞–Ї—Г—О —Б—В—А—Г–Ї—В—Г—А—Г:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
DWORD OriginalFirstThunk; // RVA —В–∞–±–ї–Є—Ж—Л –ї—Г–Ї–∞–њ–Њ–≤ (ILT)
DWORD TimeDateStamp; // Timestamp –і–ї—П bound-–Є–Љ–њ–Њ—А—В–∞
DWORD ForwarderChain;
DWORD Name; // RVA —Б—В—А–Њ–Ї–Є —Б –Є–Љ–µ–љ–µ–Љ –Љ–Њ–і—Г–ї—П
DWORD FirstThunk; // RVA —В–∞–±–ї–Є—Ж—Л –∞–і—А–µ—Б–Њ–≤ (IAT)
} IMAGE_IMPORT_DESCRIPTOR;
–Ъ–Њ–њ–Є—А—Г–µ–Љ –Њ—А–Є–≥–Є–љ–∞–ї—М–љ—Г—О Import Lookup Table –≤–љ–Є–Ј (–љ–∞—З–∞–ї–Њ –±—Г–і–µ—В –њ–Њ –∞–і—А–µ—Б—Г
50909E70). –Я–µ—А–≤–Њ–µ –њ–Њ–ї–µ –њ–µ—А–≤–Њ–≥–Њ –і–µ—Б–Ї—А–Є–њ—В–Њ—А–∞ (RVA –љ–∞ ILT) –Љ–µ–љ—П–µ–Љ —Б
9E00 –љ–∞
9E70):
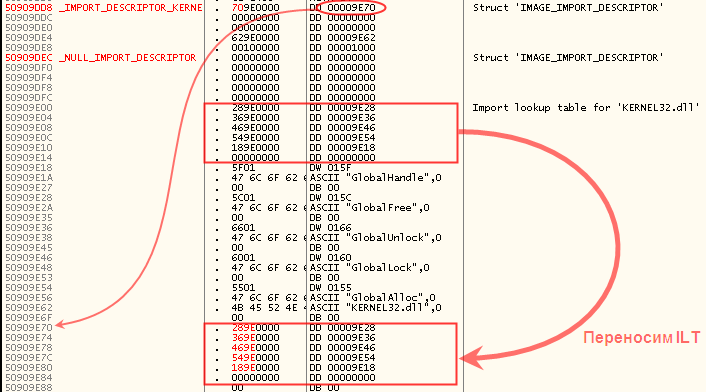
–°–ї–µ–і–Њ–Љ –Ј–∞ –њ–µ—А–µ–љ–µ—Б—С–љ–љ–Њ–є –≤–љ–Є–Ј –Њ—А–Є–≥–Є–љ–∞–ї—М–љ–Њ–є ILT —Д–Њ—А–Љ–Є—А—Г–µ–Љ –≤—В–Њ—А—Г—О ILT, –≤—В–Њ—А—Г—О IAT –Є –њ–∞—А—Г —Б—В—А—Г–Ї—В—Г—А
IMAGE_IMPORT_BY_NAME –і–ї—П —Д—Г–љ–Ї—Ж–Є–є
VirtualFree –Є
VirtualAlloc:

–Т —Н—В–Є—Е —Б—В—А—Г–Ї—В—Г—А–∞—Е –њ–Њ–Љ–Є–Љ–Њ –Є–Љ—С–љ —Д—Г–љ–Ї—Ж–Є–є —Б–Њ–і–µ—А–ґ–Є—В—Б—П 16-–±–Є—В–љ—Л–є —Е–Є–љ—В вАФ —Н—В–Њ –њ—А–Њ—Б—В–Њ –њ–Њ—А—П–і–Ї–Њ–≤—Л–є –љ–Њ–Љ–µ—А —Д—Г–љ–Ї—Ж–Є–Є –≤ —В–∞–±–ї–Є—Ж–µ —Н–Ї—Б–њ–Њ—А—В–∞ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й–µ–є –±–Є–±–ї–Є–Њ—В–µ–Ї–Є. –≠—В–Њ—В –љ–Њ–Љ–µ—А –њ–Њ–Ј–≤–Њ–ї—П–µ—В –Ј–∞–≥—А—Г–Ј—З–Є–Ї—Г –±—Л—Б—В—А–µ–µ –њ—А–Є –Є–Љ–њ–Њ—А—В–µ –љ–∞–є—В–Є —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й—Г—О –Ј–∞–њ–Є—Б—М –≤ —В–∞–±–ї–Є—Ж–µ —Н–Ї—Б–њ–Њ—А—В–∞.
–•–Є–љ—В—Л –Љ–Њ–ґ–љ–Њ –њ–Њ—Б–Љ–Њ—В—А–µ—В—М –ї—О–±–Њ–є —Г—В–Є–ї–Є—В–Њ–є вАФ —П, –љ–∞–њ—А–Є–Љ–µ—А, –њ–Њ—Б–Љ–Њ—В—А–µ–ї –≤
Dependency Walker:
–Ф–∞–ї—М—И–µ –љ–∞ —В–Њ–Љ –Љ–µ—Б—В–µ, –≥–і–µ —А–∞–љ—М—И–µ –±—Л–ї –љ—Г–ї–µ–≤–Њ–є (—В–µ–Љ–Є–љ–Є—А—Г—О—Й–Є–є) –і–µ—Б–Ї—А–Є–њ—В–Њ—А –Є–Љ–њ–Њ—А—В–∞ —Д–Њ—А–Љ–Є—А—Г–µ–Љ –≤—В–Њ—А–Њ–є –і–µ—Б–Ї—А–Є–њ—В–Њ—А –Є–Љ–њ–Њ—А—В–∞ –і–ї—П
kernel32.dll. –Р –љ–∞ —В–Њ–Љ –Љ–µ—Б—В–µ, –≥–і–µ —А–∞–љ—М—И–µ –±—Л–ї–∞ –Њ—А–Є–≥–Є–љ–∞–ї—М–љ–∞—П ILT, —Д–Њ—А–Љ–Є—А—Г–µ–Љ –љ–Њ–≤—Л–є –њ—Г—Б—В–Њ–є (—В–µ—А–Љ–Є–љ–Є—А—Г—О—Й–Є–є) –і–µ—Б–Ї—А–Є–њ—В–Њ—А –Є–Љ–њ–Њ—А—В–∞. –Т –љ–Њ–≤–Њ–Љ (–≤—В–Њ—А–Њ–Љ) –і–µ—Б–Ї—А–Є–њ—В–Њ—А–µ –Є–Љ–њ–Њ—А—В–∞ –њ—А–Њ—Б—В–∞–≤–ї—П–µ—В RVA –љ–∞ –љ–Њ–≤—Г—О ILT, –љ–Њ–≤—Г—О IAT –Є —Б—В–∞—А—Г—О —Б—В—А–Њ—З–Ї—Г
KERNEL32.dll:

–Я–Њ—Б–ї–µ —Н—В–Њ–≥–Њ –Ї–Њ–њ–Є—А—Г–µ–Љ –≤–љ–µ—Б—С–љ–љ—Л–µ –Є–Ј–Љ–µ–љ–µ–љ–Є—П –≤ –њ—А–µ–і—Б—В–∞–≤–ї–µ–љ–Є–µ —Д–∞–є–ї–∞-–Њ–±—А–∞–Ј–∞ (–Ї–Њ–Љ–∞–љ–і–∞
Copy to executable вЖТ All modifications –Ї–Њ–љ—В–µ–Ї—Б—В–љ–Њ–≥–Њ –Љ–µ–љ—О), –∞ –Ј–∞—В–µ–Љ –њ—А–µ–і—Б—В–∞–≤–ї–µ–љ–Є–µ —Д–∞–є–ї–∞-–Њ–±—А–∞–Ј–∞ –≤ —Д–∞–є–ї (–Ї–Њ–Љ–∞–љ–і–∞
Save file –Ї–Њ–љ—В–µ–Ї—Б—В–љ–Њ–≥–Њ –Љ–µ–љ—О).
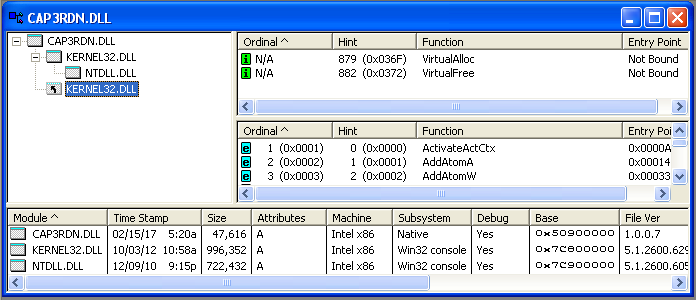
–Ґ–µ–њ–µ—А—М –Љ–Њ–ґ–љ–Њ —Г–≤–Є–і–µ—В—М, —З—В–Њ —Г –њ–Њ–ї—Г—З–µ–љ–љ–Њ–≥–Њ —Д–∞–є–ї–∞ –њ–Њ—П–≤–Є–ї—Б—П –≤—В–Њ—А–Њ–є –Є–Љ–њ–Њ—А—В –Є–Ј –±–Є–±–ї–Є–Њ—В–µ–Ї–Є
kernel32.dll, –Њ—В–≤–µ—З–∞—О—Й–Є–є –Ј–∞ –њ–∞—А—Г
VirtualAlloc+VirtualFree:
–Я–Њ—Б–ї–µ –њ–Њ–≤—В–Њ—А–љ–Њ–є –Ј–∞–≥—А—Г–Ј–Ї–Є –і—А–∞–є–≤–µ—А–∞ –њ–Њ–і –Њ—В–ї–∞–і—З–Є–Ї–Њ–Љ –љ–∞ –Љ–µ—Б—В–µ –љ–Њ–≤–Њ–є IAT –і–Њ–ї–ґ–љ—Л –±—Л—В—М —Г–ґ–µ –љ–µ RVA, –∞ —Б–∞–Љ—Л–µ –љ–∞—Б—В–Њ—П—Й–Є–µ –∞–і—А–µ—Б–∞ —Д—Г–љ–Ї—Ж–Є–є, –њ—А–Њ—Б—В–∞–≤–ї–µ–љ–љ—Л–µ —Б—О–і–∞ –Ј–∞–≥—А—Г–Ј—З–Є–Ї–Њ–Љ Windows.
–Ъ–∞–Ї –±—Л –љ–µ —В–∞–Ї! –Я—А–Є –њ–Њ–њ—Л—В–Ї–µ –њ–Њ–≤—В–Њ—А–љ–Њ–є –Њ—В–ї–∞–і–Ї–Є –љ–∞—И –Љ–Њ–і–Є—Д–Є—Ж–Є—А–Њ–≤–∞–љ–љ—Л–є –і—А–∞–є–≤–µ—А –≤–Њ–Њ–±—Й–µ –љ–µ –Љ–Њ–ґ–µ—В –Ј–∞–≥—А—Г–Ј–Є—В—М—Б—П вАФ –≥–і–µ-—В–Њ –≤ –љ–µ–і—А–∞—Е NTDLL –≤–Њ–Ј–љ–Є–Ї–∞–µ—В –Є—Б–Ї–ї—О—З–µ–љ–Є–µ (access violation) –њ—А–Є –њ–Њ–њ—Л—В–Ї–µ –Ј–∞–њ–Є—Б–Є! –≠—В–Њ –Є—Б–Ї–ї—О—З–µ–љ–Є–µ –≤–Њ–Ј–љ–Є–Ї–∞–µ—В –Ї–∞–Ї —А–∞–Ј –≤ –Љ–Њ–Љ–µ–љ—В –њ—А–Њ—Б—В–∞–≤–ї–µ–љ–Є—П —А–µ–∞–ї—М–љ–Њ–≥–Њ –∞–і—А–µ—Б–∞ —Д—Г–љ–Ї—Ж–Є–Є –≤ —П—З–µ–є–Ї—Г IAT –Ј–∞–≥—А—Г–Ј—З–Є–Ї–Њ–Љ: –і–µ–ї–Њ –≤ —В–Њ–Љ, —З—В–Њ —Б—В—А–∞–љ–Є—Ж–∞ —Б–µ–Ї—Ж–Є–Є –Ї–Њ–і–∞, –љ–∞ –Ї–Њ—В–Њ—А—Г—О –њ—А–Є—Е–Њ–і–Є—В—Б—П IAT, –Є–Љ–µ–µ—В –∞—В—А–Є–±—Г—В—Л –Ј–∞—Й–Є—В—Л, –Ј–∞–њ—А–µ—Й–∞—О—Й–Є–µ –Ј–∞–њ–Є—Б—М (–Є–±–Њ –≤—Б—П —Б–µ–Ї—Ж–Є—П –Є–Љ–µ–µ—В –∞—В—А–Є–±—Г—В—Л –Ј–∞—Й–Є—В—Л READ+EXECUTE, –∞ –љ–µ READ+WRITE+EXECUTE). –Я—А–Є –њ–Њ–њ—Л—В–Ї–µ –Ј–∞–њ–Є—Б–Є –∞–і—А–µ—Б–∞ –≤ —Б—В—А–∞–љ–Є—Ж—Г —В–Њ–ї—М–Ї–Њ-–і–ї—П-—З—В–µ–љ–Є—П –Є –≤–Њ–Ј–љ–Є–Ї–∞–µ—В –Є—Б–Ї–ї—О—З–µ–љ–Є–µ.
–Э–Њ –Ї–∞–Ї –ґ–µ —В–Њ–≥–і–∞ –Ј–∞–≥—А—Г–Ј—З–Є–Ї –њ—А–Њ—Б—В–∞–≤–ї—П–ї –∞–і—А–µ—Б–∞ –≤ –Њ—А–Є–≥–Є–љ–∞–ї—М–љ—Г—О (—А–Њ–і–љ—Г—О) IAT, –Ї–Њ—В–Њ—А–∞—П –±—Л–ї–∞ –≤ –і—А–∞–є–≤–µ—А–µ –≤—Б–µ–≥–і–∞, –≤–µ–і—М —Н—В–∞ IAT —В–Њ–ґ–µ –ї–µ–ґ–Є—В –≤ –љ–∞—З–∞–ї–µ —В–Њ–є –ґ–µ —Б–µ–Ї—Ж–Є–Є –Ї–Њ–і–∞, –љ–µ–і–Њ—Б—В—Г–њ–љ–Њ–є –і–ї—П –Ј–∞–њ–Є—Б–Є? –†–∞–Ј–≥–∞–і–Ї–∞ –њ—А–Њ—Б—В–∞: –љ–∞ –≤—А–µ–Љ—П –Ј–∞–њ–Њ–ї–љ–µ–љ–Є—П —В–∞–±–ї–Є—Ж—Л IAT –Ј–∞–≥—А—Г–Ј—З–Є–Ї –Є–Ј–Љ–µ–љ—П–µ—В –∞—В—А–Є–±—Г—В—Л –Ј–∞—Й–Є—В—Л —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й–Є—Е —Б—В—А–∞–љ–Є—Ж –љ–∞
PAGE_READWRITE. –Ъ–Њ–≥–і–∞ –ґ–µ IAT –Ј–∞–њ–Њ–ї–љ–µ–љ–∞ –∞–Ї—В—Г–∞–ї—М–љ—Л–Љ–Є –∞–і—А–µ—Б–∞–Љ–Є, —Б—В—А–∞–љ–Є—Ж–∞–Љ, –љ–∞ –Ї–Њ—В–Њ—А—Л–µ –њ—А–Є—Е–Њ–і–Є–ї–∞—Б—М IAT, –≤–Њ–Ј–≤—А–∞—Й–∞—О—В—Б—П –њ—А–µ–ґ–љ–Є–µ (–Њ—А–Є–≥–Є–љ–∞–ї—М–љ—Л–µ) –∞—В—А–Є–±—Г—В—Л –Ј–∞—Й–Є—В—Л.
–Э–∞ –Њ–±—А–∞–±–Њ—В–Ї—Г –Ї–∞–ґ–і–Њ–≥–Њ –і–µ—Б–Ї—А–Є–њ—В–Њ—А–∞ –Є–Љ–њ–Њ—А—В–∞ –≤—Л–Ј—Л–≤–∞–µ—В—Б—П —Д—Г–љ–Ї—Ж–Є—П
LdrpSnapIAT –Є–Ј NTDLL. –Ю–љ–∞ –Љ–µ–љ—П–µ—В –∞—В—А–Є–±—Г—В—Л –Ј–∞—Й–Є—В—Л —Б—В—А–∞–љ–Є—Ж –љ–∞
PAGE_READWRITE (–і–ї—П –Њ–±–Њ–Ј–љ–∞—З–µ–љ–Є—П —Б–µ–≥–Њ –і–µ–є—Б—В–≤–Є—П —А–∞–Ј—А–∞–±–Њ—В–Ї–Є Windows –њ—А–Є–Љ–µ–љ—П—О—В —В–µ—А–Љ–Є–љ ¬Ђunprotect¬ї), –Ј–∞—В–µ–Љ –≤ —Ж–Є–Ї–ї–µ –≤—Л–Ј—Л–≤–∞–µ—В
LdrpSnapThunk –і–ї—П –Ї–∞–ґ–і–Њ–є —П—З–µ–є–Ї–Є IAT (—В.–µ. –і–ї—П –Ї–∞–ґ–і–Њ–є –Є–Љ–њ–Њ—А—В–Є—А—Г–µ–Љ–Њ–є —Д—Г–љ–Ї—Ж–Є–Є/—Б—Г—Й–љ–Њ—Б—В–Є), –њ–Њ—Б–ї–µ —З–µ–≥–Њ –≤–Њ—Б—Б—В–∞–љ–∞–≤–ї–Є–≤–∞–µ—В —Б—В—А–∞–љ–Є—Ж–∞–Љ –њ—А–µ–ґ–љ–Є–µ –∞—В—А–Є–±—Г—В—Л –Ј–∞—Й–Є—В—Л.
–Х—Б–ї–Є –Ј–∞–≥—А—Г–Ј—З–Є–Ї —В–∞–Ї –њ–Њ—Б—В—Г–њ–∞–µ—В, –њ–Њ—З–µ–Љ—Г –ґ–µ –≤
LdrpSnapThunk –њ—А–Є –њ—А–Њ—Б—В–∞–≤–ї–µ–љ–Є–Є –Ј–љ–∞—З–µ–љ–Є—П (–∞–і—А–µ—Б–∞) –≤ —П—З–µ–є–Ї—Г IAT –≤–Њ–Ј–љ–Є–Ї–∞–µ—В –Є—Б–Ї–ї—О—З–µ–љ–Є–µ? –Т—Б—С –і–µ–ї–Њ –≤ —В–Њ–Љ, –Ї–∞–Ї
LdrpSnapIAT –Њ–њ—А–µ–і–µ–ї—П–µ—В –і–Є–∞–њ–∞–Ј–Њ–љ —Б—В—А–∞–љ–Є—Ж, –Ї–Њ—В–Њ—А—Л–Љ –љ—Г–ґ–љ–Њ –њ–Њ–Љ–µ–љ—П—В—М –∞—В—А–Є–±—Г—В—Л –Ј–∞—Й–Є—В—Л. –Ф–ї—П —Н—В–Њ–≥–Њ –Њ–љ–∞ —Б–Љ–Њ—В—А–Є—В –Њ—В–і–µ–ї—М–љ—Г—О –і–Є—А–µ–Ї—В–Њ—А–Є—О –≤ —В–∞–±–ї–Є—Ж–µ –і–Є—А–µ–Ї—В–Њ—А–Є–є PE-—Д–∞–є–ї–∞, –Ї–Њ—В–Њ—А–∞—П –љ–∞–Ј—Л–≤–∞–µ—В—Б—П ¬ЂIAT Directory¬ї (–љ–µ –њ—Г—В–∞—В—М —Б Import Directory!). –Х—Б–ї–Є –≤ IAT-–і–Є—А–µ–Ї—В–Њ—А–Є–Є –µ—Б—В—М –±–∞–Ј–∞ –Є —А–∞–Ј–Љ–µ—А IAT-–Ј–Њ–љ—Л, —В–Њ –Є–Љ–µ–љ–љ–Њ —Н—В–Њ—В –і–Є–∞–њ–∞–Ј–Њ–љ —Б—В—А–∞–љ–Є—Ж –њ–Њ–і–≤–µ—А–≥–∞–µ—В—Б—П unprotect'–Є–љ–≥—Г. –Ю–±—Л—З–љ–Њ –Љ–Њ–і—Г–ї—М –Є–Љ–њ–Њ—А—В–Є—А—Г–µ—В –Є–Ј –Љ–љ–Њ–ґ–µ—Б—В–≤–∞ –і—А—Г–≥–Є—Е –Љ–Њ–і—Г–ї–µ–є, –Є IAT-—Л —А–∞–Ј–љ—Л—Е –Љ–Њ–і—Г–ї–µ–є –ї–µ–ґ–∞—В –Ї–Њ–Љ–њ–∞–Ї—В–љ–Њ вАФ –≤–њ–ї–Њ—В–љ—Г—О –і—А—Г–≥ –Ї –і—А—Г–≥—Г. –Э–∞ —В–∞–Ї–Њ–µ –њ–ї–Њ—В–љ–Њ–µ –Ї–Њ–Љ–њ–∞–Ї—В–љ–Њ–µ —Б–Ї–Њ–њ–ї–µ–љ–Є–µ IAT-—В–∞–±–ї–Є—Ж –Є —Г–Ї–∞–Ј—Л–≤–∞–µ—В IAT-–і–Є—А–µ–Ї—В–Њ—А–Є—П. –Т —Б–ї—Г—З–∞–µ –ґ–µ, –µ—Б–ї–Є IAT-–і–Є—А–µ–Ї—В–Њ—А–Є—П –љ–µ –Ј–∞–њ–Њ–ї–љ–µ–љ–∞, –Ј–∞–≥—А—Г–Ј—З–Є–Ї –њ—Л—В–∞–µ—В—Б—П —Б–∞–Љ–Њ—Б—В–Њ—П—В–µ–ї—М–љ–Њ –≤—Л—З–Є—Б–ї–Є—В—М –і–Є–∞–њ–∞–Ј–Њ–љ —Б—В—А–∞–љ–Є—Ж, –Ї–Њ—В–Њ—А—Л–µ –љ—Г–ґ–љ–Њ unprotect'–Є—В—М. –Я—А–Є —Н—В–Њ–Љ –Њ–љ –і–µ–є—Б—В–≤—Г–µ—В –і–Њ–≤–Њ–ї—М–љ–Њ –њ—А–Є–Љ–Є—В–Є–≤–љ–Њ: –Є—Й–µ—В —Б–µ–Ї—Ж–Є—О, –≤ –Ї–Њ—В–Њ—А–Њ–є –ї–µ–ґ–Є—В —В–∞–±–ї–Є—Ж–∞ –і–µ—Б–Ї—А–Є–њ—В–Њ—А–Њ–≤ –Є–Љ–њ–Њ—А—В–∞ –Є unprotect-–Є—В
–≤—Б—О —Б–µ–Ї—Ж–Є—О —Ж–µ–ї–Є–Ї–Њ–Љ! –Ф–∞, —А–∞–Ј–Љ–µ—А IAT –љ–Є–≥–і–µ –љ–µ —Е—А–∞–љ–Є—В—Б—П, –љ–Њ –Љ–Њ–ґ–љ–Њ –±—Л–ї–Њ –±—Л –њ—А–Њ–є—В–Є—Б—М IAT –Є –≤—Л—З–Є—Б–ї–Є—В—М –µ—С –і–ї–Є–љ—Г, –∞ –і–∞–ї—М—И–µ –Љ–µ–љ—П—В—М –∞—В—А–Є–±—Г—В—Л –Ј–∞—Й–Є—В—Л —В–Њ–ї—М–Ї–Њ –љ–µ–Њ–±—Е–Њ–і–Є–Љ—Л–Љ —Б—В—А–∞–љ–Є—Ж–∞–Љ, –∞ –љ–µ –≤–Њ–Њ–±—Й–µ –≤—Б–µ–Љ, –љ–Њ —В–∞–Ї –љ–µ —Б–і–µ–ї–∞–ї–Є вАФ –Њ—Б—В–∞–≤–Є–Љ —Н—В–Њ –љ–∞ —Б–Њ–≤–µ—Б—В–Є —А–∞–Ј—А–∞–±–Њ—В—З–Є–Ї–Њ–≤ Windows (–Ї—Б—В–∞—В–Є, –Љ–Њ–ґ–µ—В –±—Л—В—М –≤ –њ–Њ—Б–ї–µ–і–љ–Є—Е –≤–µ—А—Б–Є—П—Е —Н—В–Њ –њ–Њ–≤–µ–і–µ–љ–Є–µ –њ–Њ–Љ–µ–љ—П–ї–Є).
–Я–Њ—Б–Љ–Њ—В—А–Є–Љ –љ–∞ IAT Directory –≤ PE-–Ј–∞–≥–Њ–ї–Њ–≤–Ї–µ –љ–∞—И–µ–≥–Њ –і—А–∞–є–≤–µ—А–∞:
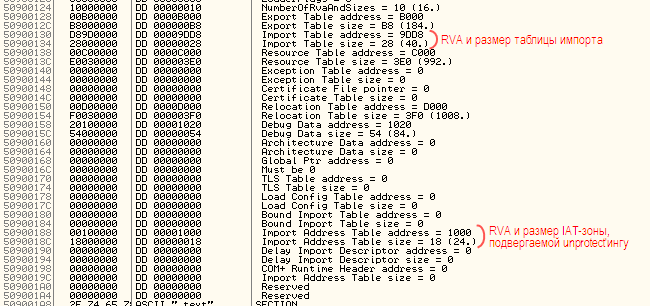
–Ъ–∞–Ї –Љ–Њ–ґ–љ–Њ –Ј–∞–Љ–µ—В–Є—В—М, –њ–Њ–ї—П ¬ЂRVA¬ї –Є ¬ЂSize¬ї IAT-–і–Є—А–µ–Ї—В–Њ—А–Є–Є –Ј–∞–њ–Њ–ї–љ–µ–љ—Л, –Є –Ј–љ–∞—З–Є—В –Ј–∞–≥—А—Г–Ј—З–Є–Ї (
LdrpSnapIAT) –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В –Є–Љ–µ–љ–љ–Њ —Н—В–Њ—В –і–Є–∞–њ–∞–Ј–Њ–љ –і–ї—П –Њ–њ—А–µ–і–µ–ї–µ–љ–Є—П –љ–∞–±–Њ—А–∞ —Б—В—А–∞–љ–Є—Ж, –∞—В—А–Є–±—Г—В—Л –Ј–∞—Й–Є—В—Л –Ї–Њ—В–Њ—А—Л—Е –љ—Г–ґ–љ–Њ –њ–Њ–Љ–µ–љ—П—В—М. –Т –Њ—А–Є–≥–Є–љ–∞–ї–µ IAT –Є–Ј 5 —П—З–µ–µ–Ї –њ–Њ–њ–∞–і–∞–ї–∞ –≤ —Н—В–Њ—В –і–Є–∞–њ–∞–Ј–Њ–љ, –љ–Њ —Б–µ–є—З–∞—Б —Г –љ–∞—Б –і–≤–µ IAT: –Њ–і–љ–∞ –≤ –љ–∞—З–∞–ї–µ —Б–µ–Ї—Ж–Є–Є –Ї–Њ–і–∞, –і—А—Г–≥–∞—П –≤ —Б–∞–Љ–Њ–Љ –Ї–Њ–љ—Ж–µ.
–Т—Л—Е–Њ–і–∞ —Г –љ–∞—Б –і–≤–∞: –ї–Є–±–Њ –Ј–∞–љ—Г–ї–Є—В—М –њ–Њ–ї—П IAT-–і–Є—А–µ–Ї—В–Њ—А–Є–Є –≤ PE-–Ј–∞–≥–Њ–ї–Њ–≤–Ї–µ, –ї–Є–±–Њ –і–Њ—В—П–љ—Г—В—М –њ–Њ–ї–µ Size (–Ї–Њ—В–Њ—А–Њ–µ —Б–µ–є—З–∞—Б —А–∞–≤–љ–Њ 0x18) —В–∞–Ї, —З—В–Њ–±—Л –Њ–љ–Њ –Ј–∞—Е–≤–∞—В—Л–≤–∞–ї–Њ –Є –љ–∞—И—Г –љ–Њ–≤—Г—О (–≤—В–Њ—А—Г—О) IAT.
–Я–Њ—Б–ї–µ –Є—Б–њ—А–∞–≤–ї–µ–љ–Є—П —Н—В–Њ–є –њ—А–Њ–±–ї–µ–Љ—Л, –Ї–∞–Ї —П –Є –≥–Њ–≤–Њ—А–Є–ї, –њ—А–Є –Ј–∞–≥—А—Г–Ј–Ї–µ –і—А–∞–є–≤–µ—А–∞ –≤ –Њ—В–ї–∞–і—З–Є–Ї–µ –љ–∞ –Љ–µ—Б—В–µ –љ–Њ–≤–Њ–є IAT —Г–ґ–µ –љ–µ RVA, –∞ —А–µ–∞–ї—М–љ—Л–µ –∞–і—А–µ—Б–∞ –Є–Љ–њ–Њ—А—В–Є—А—Г–µ–Љ—Л—Е —Д—Г–љ–Ї—Ж–Є–є:
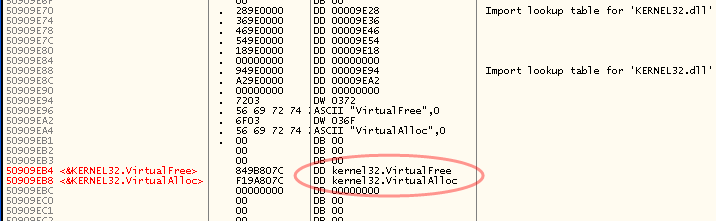
–Ю—Б—В–∞—С—В—Б—П —В–Њ–ї—М–Ї–Њ –Ј–∞–љ–Њ–≤–Њ —Б–і–µ–ї–∞—В—М –і—А—Г–≥–Є–µ –≤–∞—А–Є–∞–љ—В—Л
hacked_alloc400 –Є
hacked_free400 вАФ –≤—Л–Ј—Л–≤–∞—О—Й–Є–µ
VirtualAlloc –Є
VirtualFree —Г–ґ–µ —З–µ—А–µ–Ј IAT, –∞ –љ–µ —З–µ—А–µ–Ј –ґ–µ—Б—В–Ї–Њ –≤—И–Є—В—Л–µ –∞–і—А–µ—Б–∞:
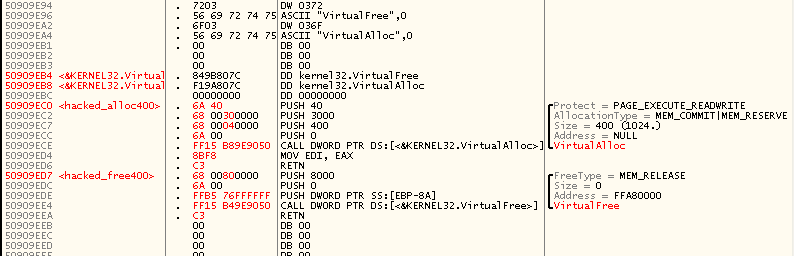
–Я–Њ—Б–ї–µ –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П —В–∞–Ї–Њ–є –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є–Є –Є —Б–±—А–Њ—Б–∞ –Љ–Њ–і–Є—Д–Є—Ж–Є—А–Њ–≤–∞–љ–љ–Њ–≥–Њ –Њ–±—А–∞–Ј–∞ –≤ —Д–∞–є–ї –і—А–∞–є–≤–µ—А —Г—Б–њ–µ—И–љ–Њ –Ј–∞–≥—А—Г–ґ–∞–µ—В—Б—П –≤ –Р–Я, –њ–µ—З–∞—В—М —А–∞–±–Њ—В–∞–µ—В –љ–∞ —Г—А–∞, –Є –Ї–∞–Ј–∞–ї–Њ—Б—М –±—Л –≤—Б—С —Б–і–µ–ї–∞–љ–Њ, –љ–Њ –љ–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ –љ–µ—В!
–Э–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ –Њ—Б—В–∞–ї–Њ—Б—М –µ—Й—С –і–≤–µ –≤–µ—Й–Є, –Њ –Ї–Њ—В–Њ—А—Л—Е –Љ—Л –Ј–∞–±—Л–ї–Є, –Ї–Њ—В–Њ—А—Л–µ, –њ–Њ–Ї–∞ –љ–µ —Б–і–µ–ї–∞–љ—Л, –Њ—Б—В–∞–≤–ї—П—О—В –љ–∞—И –њ—А–Њ–њ–∞—В—З–µ–љ–љ—Л–є –і—А–∞–є–≤–µ—А –љ–µ–њ–Њ–ї–љ–Њ—Ж–µ–љ–љ—Л–Љ —Г—А–Њ–і—Ж–µ–Љ.
–Т–Њ-–њ–µ—А–≤—Л—Е, –љ–∞—И –њ—А–Њ–±–ї–µ–Љ–љ—Л–є –і—А–∞–є–≤–µ—А –њ–µ—З–∞—В–Є вАФ —Н—В–Њ DLL, –∞ DLL, –≤–њ—А–Њ—З–µ–Љ –Ї–∞–Ї –Є –ї—О–±–Њ–є PE-–Љ–Њ–і—Г–ї—М, –Љ–Њ–ґ–µ—В –±—Л—В—М –Ј–∞–≥—А—Г–ґ–µ–љ–∞ –љ–µ –њ–Њ—В–Њ–Љ—Г –∞–і—А–µ—Б—Г, –њ–Њ –Ї–∞–Ї–Њ–Љ—Г –њ–ї–∞–љ–Є—А–Њ–≤–∞–ї –µ—С —Б–Њ–Ј–і–∞—В–µ–ї—М, –∞ –њ–Њ —Б–Њ–≤–µ—А—И–µ–љ–љ–Њ –і—А—Г–≥–Њ–Љ—Г, –µ—Б–ї–Є –Є–Ј–љ–∞—З–∞–ї—М–љ–Њ –ґ–µ–ї–∞–µ–Љ—Л–є –і–Є–∞–њ–∞–Ј–Њ–љ –∞–і—А–µ—Б–љ–Њ–≥–Њ –њ—А–Њ—Б—В—А–∞–љ—Б—В–≤–∞ –Ј–∞–љ—П—В —З–µ–Љ-—В–Њ –і—А—Г–≥–Є–Љ, –ї–Є–±–Њ –µ—Б–ї–Є –Ј–∞–і–µ–є—Б—В–≤–Њ–≤–∞–љ–∞ —В–µ—Е–љ–Њ–ї–Њ–≥–Є—П
ASLR.
–Я—А–Є –Ј–∞–≥—А—Г–Ј–Ї–µ –њ–Њ –љ–µ—А–Њ–і–љ–Њ–Љ—Г –±–∞–Ј–Њ–≤–Њ–Љ—Г –∞–і—А–µ—Б—Г –≤—Б–µ –∞–±—Б–Њ–ї—О—В–љ—Л–µ –∞–і—А–µ—Б–∞, –≤—И–Є—В—Л–µ –≤ –Ї–Њ–і –Є –і–∞–љ–љ—Л–µ –Њ–±—А–∞–Ј–∞, —Б—В–∞–љ–Њ–≤—П—В—Б—П –љ–µ–Ї–Њ—А—А–µ–Ї—В–љ—Л–Љ–Є –Є –љ–µ–і–µ–є—Б—В–≤–Є—В–µ–ї—М–љ—Л–Љ–Є. –Ф–ї—П –Є—Б–њ—А–∞–≤–ї–µ–љ–Є—П —Н—В–Њ–є —Б–Є—В—Г–∞—Ж–Є–Є –≤—Б–µ –Њ–љ–Є –і–Њ–ї–ґ–љ—Л –±—Л—В—М —Б–Ї–Њ—А—А–µ–Ї—В–Є—А–Њ–≤–∞–љ—Л –љ–∞ –≤–µ–ї–Є—З–Є–љ—Г, —А–∞–≤–љ—Г—О —А–∞–Ј–љ–Є—Ж–µ –Љ–µ–ґ–і—Г —Д–∞–Ї—В–Є—З–µ—Б–Ї–Є–Љ –±–∞–Ј–Њ–≤—Л–Љ –∞–і—А–µ—Б–Њ–Љ –Ј–∞–≥—А—Г–Ј–Ї–Є –Є –ґ–µ–ї–∞–µ–Љ—Л–Љ –±–∞–Ј–Њ–≤—Л–Љ –∞–і—А–µ—Б–Њ–Љ –Ј–∞–≥—А—Г–Ј–Ї–Є. –Я—А–Є —Н—В–Њ–Љ —Б–њ–Є—Б–Њ–Ї –Љ–µ—Б—В, –Ї–Њ—В–Њ—А—Л–µ –і–Њ–ї–ґ–љ—Л –њ–Њ–і–≤–µ—А–≥–љ—Г—В—М—Б—П –Ї–Њ—А—А–µ–Ї—Ж–Є–Є, —Б–Њ–і–µ—А–ґ–Є—В—Б—П –≤ —Б–∞–Љ–Њ–Љ PE-—Д–∞–є–ї–µ: —Н—В–Њ —В–∞–Ї –љ–∞–Ј—Л–≤–∞–µ–Љ—Л–µ —А–µ–ї–Њ–Ї–Є (–Є–ї–Є —А–µ–ї–Њ–Ї–∞—Ж–Є–Є), –Ї–Њ—В–Њ—А—Л–µ –Њ–±—Л—З–љ–Њ –љ–∞—Е–Њ–і—П—В—Б—П –≤ –Њ—В–і–µ–ї—М–љ–Њ–є —Б–µ–Ї—Ж–Є–Є (–Ї–∞–Ї –њ—А–∞–≤–Є–ї–Њ —Б –Є–Љ–µ–љ–µ–Љ
.reloc –Є —Д–ї–∞–≥–Њ–Љ
IMAGE_SCN_MEM_DISCARDABLE, –њ–Њ–Ј–≤–Њ–ї—П—О—Й–Є–Љ –љ–µ –њ—А–Њ–µ—Ж–Є—А–Њ–≤–∞—В—М —Б–µ–Ї—Ж–Є—О –љ–∞ –Р–Я –њ—А–Њ—Ж–µ—Б—Б–∞ –њ–Њ—Б–ї–µ –Ј–∞–≤–µ—А—И–µ–љ–Є—П –Ј–∞–≥—А—Г–Ј–Ї–Є PE-–Љ–Њ–і—Г–ї—П).
–†–µ–ї–Њ–Ї–Є –Љ–Њ–≥—Г—В –Њ—В—Б—Г—В—Б—В–≤–Њ–≤–∞—В—М –≤ –Њ–±—А–∞–Ј–µ PE-–Љ–Њ–і—Г–ї—П (–Є –Њ–±—Л—З–љ–Њ –≤—Б–µ–≥–і–∞ –Њ—В—Б—Г—В—Б—В–≤—Г—О—В —Г EXE, –Є –≤—Б–µ–≥–і–∞ –њ—А–Є—Б—Г—В—Б—В–≤—Г—О—В —Г DLL, OCX, SYS –Є —В.–њ.) вАФ –≤ —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ —Б–∞–Љ PE-–Љ–Њ–і—Г–ї—М –±—Г–і–µ—В –Є–Љ–µ—В—М —Г—Б—В–∞–љ–Њ–≤–ї–µ–љ–љ—Л–Љ —Д–ї–∞–≥
IMAGE_FILE_RELOCS_STRIPPED –≤ –њ–Њ–ї–µ —Е–∞—А–∞–Ї—В–µ—А–Є—Б—В–Є–Ї PE-–Ј–∞–≥–Њ–ї–Њ–≤–Ї–∞, –∞ –њ—А–Є –њ–Њ–њ—Л—В–Ї–µ –Ј–∞–≥—А—Г–Ј–Є—В—М —В–∞–Ї–Њ–є –Љ–Њ–і—Г–ї—М –≤ –Р–Я, –µ—Б–ї–Є —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й–Є–є –і–Є–∞–њ–∞–Ј–Њ–љ —Б—В—А–∞–љ–Є—Ж –Р–Я –Њ–Ї–∞–ґ–µ—В—Б—П –Ј–∞–љ—П—В—Л–Љ —Е–Њ—В—П –±—Л —З–∞—Б—В–Є—З–љ–Њ, –Ј–∞–≥—А—Г–Ј–Ї–∞
–≤–Њ–Њ–±—Й–µ –љ–µ —Б–Њ—Б—В–Њ–Є—В—Б—П.
–Э–∞—И –њ—А–Њ–±–ї–µ–Љ–љ—Л–є –і—А–∞–є–≤–µ—А –Є–Љ–µ–µ—В —Б–µ–Ї—Ж–Є—О —А–µ–ї–Њ–Ї–Њ–≤ (–Є –љ–µ –Є–Љ–µ–µ—В —Д–ї–∞–≥–∞
IMAGE_FILE_RELOCS_STRIPPED, —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–µ–љ–љ–Њ), –∞ –Ј–љ–∞—З–Є—В —П–≤–ї—П–µ—В—Б—П –њ–µ—А–µ–Љ–µ—Й–∞–µ–Љ—Л–Љ, —В–Њ –µ—Б—В—М –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В—Б—П –Ј–∞–≥—А—Г–Ј–Ї—Г –њ–Њ –љ–µ—А–Њ–і–љ–Њ–Љ—Г –±–∞–Ј–Њ–≤–Њ–Љ—Г –∞–і—А–µ—Б—Г. –Я—А–Њ–±–ї–µ–Љ–∞, –Њ–і–љ–∞–Ї–Њ –ґ–µ, —Б–Њ—Б—В–Њ–Є—В –≤ —В–Њ–Љ, —З—В–Њ –≤–љ–µ–і—А—С–љ–љ—Л–µ –љ–∞–Љ–Є –≤ –Ї–Њ–љ–µ—Ж —Б–µ–Ї—Ж–Є–Є –Ї–Њ–і–∞ —Д—А–∞–≥–Љ–µ–љ—В—Л
hacked_alloc400 –Є
hacked_free400 –Њ–±—А–∞—Й–∞—О—В—Б—П –Ї —П—З–µ–є–Ї–∞–Љ IAT, –Є—Б–њ–Њ–ї—М–Ј—Г—П
–∞–±—Б–Њ–ї—О—В–љ—Л–µ –∞–і—А–µ—Б–∞. –≠—В–Є –∞–±—Б–Њ–ї—О—В–љ—Л–µ –∞–і—А–µ—Б–∞, –≤—И–Є—В—Л–µ –≤ –Ї–Њ–і, –љ–µ –њ–Њ–і–≤–µ—А–≥–љ—Г—В—Б—П –Ї–Њ—А—А–µ–Ї—Ж–Є–Є –њ—А–Є –Ј–∞–≥—А—Г–Ј–Ї–µ –њ–Њ –љ–µ—А–Њ–і–љ–Њ–Љ—Г –±–∞–Ј–Њ–≤–Њ–Љ—Г –∞–і—А–µ—Б—Г, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –Љ—Л –Є—Е —Б–∞–Љ–Є –і–Њ–±–∞–≤–Є–ї–Є –≤ –Њ–±—А–∞–Ј, –љ–µ –і–Њ–±–∞–≤–Є–≤ –љ–Є—З–µ–≥–Њ –≤ —А–µ–ї–Њ–Ї–Є, –Є –≤ –Є—В–Њ–≥–µ –Њ–Ї–∞–ґ—Г—В—Б—П –љ–µ–і–µ–є—Б—В–≤–Є—В–µ–ї—М–љ—Л–Љ–Є вАФ –њ—А–Є –њ–Њ–њ—Л—В–Ї–µ —З—В–Њ-—В–Њ –њ–µ—З–∞—В–∞—В—М, –Ї–∞–Ї —В–Њ–ї—М–Ї–Њ –і–µ–ї–Њ –і–Њ–є–і—С—В –і–Њ –≤—Л–і–µ–ї–µ–љ–Є—П –±—Г—Д–µ—А–∞ –њ–Њ–і –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Є –≥–µ–љ–µ—А–Є—А—Г–µ–Љ—Л–є –Ї–Њ–і, –і—А–∞–є–≤–µ—А –Њ–±—А—Г—И–Є—В –≤—Б—О –њ—А–Њ–≥—А–∞–Љ–Љ—Г, –њ—Л—В–∞—О—Й—Г—О—Б—П —З—В–Њ-—В–Њ –љ–∞–њ–µ—З–∞—В–∞—В—М.
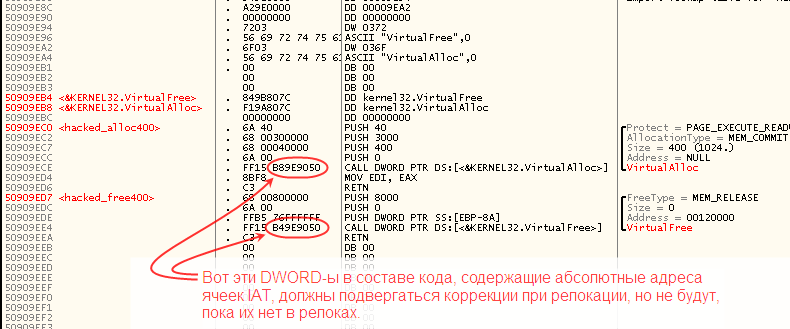
–Ш–Ј —Н—В–Њ–є —Б–Є—В—Г–∞—Ж–Є–Є –µ—Б—В—М –і–≤–∞ –≤—Л—Е–Њ–і–∞:
- –°–≤–Њ–Є–Љ–Є —А—Г–Ї–∞–Љ–Є —А–∞—Б—И–Є—А–Є—В—М —Б–µ–Ї—Ж–Є—О —А–µ–ї–Њ–Ї–Њ–≤, –і–Њ–±–∞–≤–Є–≤ —В—Г–і–∞ —Г–њ–Њ–Љ–Є–љ–∞–љ–Є–µ –µ—Й—С –і–≤—Г—Е –љ–Њ–≤—Л—Е –Љ–µ—Б—В, –Ї–Њ—В–Њ—А—Л–µ –і–Њ–ї–ґ–љ—Л –њ–Њ–і–≤–µ—А–≥–∞—В—М—Б—П –Ї–Њ—А—А–µ–Ї—Ж–Є–Є.
- –Т—Л—Б—В–∞–≤–Є—В—М —Д–ї–∞–≥ IMAGE_FILE_RELOCS_STRIPPED, –Ј–∞–њ—А–µ—В–Є–≤ —В–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ –Ј–∞–≥—А—Г–ґ–∞—В—М DLL –њ–Њ –љ–µ—А–Њ–і–љ–Њ–є –±–∞–Ј–µ –Є —Г—Б—В—А–∞–љ–Є–≤ –њ—А–Њ–±–ї–µ–Љ—Г –љ–∞ –Ї–Њ—А–љ—О.
–Т—В–Њ—А–Њ–є —Б–њ–Њ—Б–Њ–±, –њ—А–Є —Б–≤–Њ–µ–є –љ–µ–±—Л–≤–∞–ї–Њ–є –њ—А–Њ—Б—В–Њ—В–µ, —П–≤–ї—П–µ—В—Б—П –љ–µ–≤–Њ–Њ–±—А–∞–Ј–Є–Љ–Њ –≥–ї—Г–њ—Л–Љ —А–µ—И–µ–љ–Є–µ–Љ: –±—Г–і—Г—З–Є –і—А–∞–є–≤–µ—А–Њ–Љ –њ–µ—З–∞—В–Є, —Н—В–∞ DLL –і–Њ–ї–ґ–љ–∞ –њ–Њ–і–≥—А—Г–ґ–∞—В—М—Б—П –≤ —Б–∞–Љ—Л–µ –љ–µ–≤–Њ–Њ–±—А–∞–Ј–Є–Љ—Л–µ –Є —Д–∞–љ—В–∞—Б—В–Є—З–µ—Б–Ї–Є–µ –Њ–Ї—А—Г–ґ–µ–љ–Є—П (–Є–Љ–µ—О—В—Б—П –≤ –≤–Є–і—Г –Р–Я –њ—А–Њ—Ж–µ—Б—Б–Њ–≤) –Є –±—Л—В—М —Б–њ–Њ—Б–Њ–±–љ–Њ–є –≤—В–Є—Б–Ї–Є–≤–∞—В—М—Б—П –≤ —Б–∞–Љ—Л–µ —Д—А–∞–≥–Љ–µ–љ—В–Є—А–Њ–≤–∞–љ–љ—Л–µ –Р–Я, –ї–Є—И—М –±—Л —В–Њ–ї—М–Ї–Њ –≤ –љ—С–Љ –љ–∞—И—С–ї—Б—П —Б–≤–Њ–±–Њ–і–љ—Л–є –Ї—Г—Б–Њ—З–µ–Ї –њ–∞–Љ—П—В–Є (–Р–Я), –і–Њ—Б—В–∞—В–Њ—З–љ—Л–є –і–ї—П –Ј–∞–≥—А—Г–Ј–Ї–Є –µ—С —В—Г–і–∞. –Ш –Ј–∞–≥—А—Г–ґ–∞–µ—В—Б—П –Њ–љ–∞ –≤ –Р–Я –њ—А–Њ—Ж–µ—Б—Б–∞ –љ–µ –≤ –љ–∞—З–∞–ї–µ –µ–≥–Њ —А–∞–±–Њ—В—Л, –Ї–Њ–≥–і–∞ –Р–Я –µ—Й—С –±–Њ–ї–µ–µ –њ—Г—Б—В–Њ–µ –Є –Љ–µ–љ–µ–µ —Д—А–∞–≥–Љ–µ–љ—В–Є—А–Њ–≤–∞–љ–љ–Њ–µ, –∞ –Ї–∞–Ї –њ—А–∞–≤–Є–ї–Њ –≤ –Ї–Њ–љ—Ж–µ (–і–Њ–ї–≥–Њ –љ–∞–±–Є—А–∞–ї–Є/—А–Є—Б–Њ–≤–∞–ї–Є –і–Њ–Ї—Г–Љ–µ–љ—В, —В–µ–њ–µ—А—М –њ—А–Є—И–ї–∞ –њ–Њ—А–∞ –љ–∞–њ–µ—З–∞—В–∞—В—М), –њ—А–Є—З—С–Љ –њ–Њ–і–≥—А—Г–ґ–∞—В—М—Б—П –µ–є –њ—А–Є—Е–Њ–і–Є—В—Б—П –≤ —Б–∞–Љ—Л–µ —А–∞–Ј–љ–Њ–Њ–±—А–∞–Ј–љ—Л–µ –њ—А–Њ—Ж–µ—Б—Б—Л (–ї—О–±—Л–µ, –Ї–Њ—В–Њ—А—Л–µ –њ–Њ—В–µ–љ—Ж–Є–∞–ї—М–љ–Њ —З—В–Њ-—В–Њ –Љ–Њ–≥—Г—В –≤—Л–≤–Њ–і–Є—В—М –љ–∞ –њ—А–Є–љ—В–µ—А). –°–Њ–≤–µ—А—И–µ–љ–љ–Њ –љ–µ–≤–Њ–Ј–Љ–Њ–ґ–љ–Њ –њ—А–µ–і—Б–Ї–∞–Ј–∞—В—М –Є–ї–Є –±—Л—В—М —Г–≤–µ—А–µ–љ–љ—Л–Љ, —З—В–Њ –і–Є–∞–њ–∞–Ј–Њ–љ –∞–і—А–µ—Б–Њ–≤
0x50900000вАФ
0x5090E000 –≤ —Ж–µ–ї–µ–≤–Њ–Љ –њ—А–Њ—Ж–µ—Б—Б–µ –Њ–Ї–∞–ґ–µ—В—Б—П —Б–≤–Њ–±–Њ–і–љ—Л–Љ вАФ¬†–Ј–∞–њ—А–Њ—Б—В–Њ –Њ–љ –Љ–Њ–ґ–µ—В –Њ–Ї–∞–Ј–∞—В—М—Б—П —З–µ–Љ-—В–Њ –Ј–∞–љ—П—В—Л–Љ –Ї –Љ–Њ–Љ–µ–љ—В—Г –њ–Њ–і–≥—А—Г–Ј–Ї–Є –і—А–∞–є–≤–µ—А–∞ –њ–µ—З–∞—В–Є, –Є –±—Л–ї–Њ –±—Л —Б–Њ–≤–µ—А—И–µ–љ–љ–Њ–є –≥–ї—Г–њ–Њ—Б—В—М—О –і–µ–ї–∞—В—М –і—А–∞–є–≤–µ—А, –Є—Б—Е–Њ–і —Г—Б–њ–µ—И–љ–Њ–є –Ј–∞–≥—А—Г–Ј–Ї–Є –Ї–Њ—В–Њ—А–Њ–≥–Њ –±—Г–і–µ—В –Ј–∞–≤–Є—Б–µ—В—М –Њ—В —В–∞–Ї–Њ–≥–Њ —Б–ї—Г—З–∞–є–љ–Њ–≥–Њ —Д–∞–Ї—В–Њ—А–∞.
–Ю—Б—В–∞—С—В—Б—П —В–Њ–ї—М–Ї–Њ –њ–µ—А–≤—Л–є –≤–∞—А–Є–∞–љ—В.
–Х—Б—В—М –љ–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ –µ—Й—С –Є —В—А–µ—В–Є–є –≤–∞—А–Є–∞–љ—В: –њ—А–Є —Д–Њ—А–Љ–Є—А–Њ–≤–∞–љ–Є–Є –≤–љ–µ–і—А—П–µ–Љ—Л—Е –Ї—Г—Б–Њ—З–Ї–Њ–≤ –Љ–Њ–ґ–љ–Њ –≤–Њ—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М—Б—П –Ї–ї–∞—Б—Б–Є—З–µ—Б–Ї–Є–Љ ¬Ђ—Е–∞–Ї–µ—А—Б–Ї–Є–Љ¬ї —В—А—О–Ї–Њ–Љ –њ–Њ –Њ–њ—А–µ–і–µ–ї–µ–љ–Є—О EIP —Б –њ–Њ–Љ–Њ—Й—М—О —Д–Є–Ї—В–Є–≤–љ–Њ–є call-–Є–љ—Б—В—А—Г–Ї—Ж–Є–Є:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
call label
label: pop eax ; EIP —В–µ–њ–µ—А—М —Б–Њ–і–µ—А–ґ–Є—В—Б—П –≤ EAX
–Р –і–∞–ї—М—И–µ –≤—Л—З–Є—Б–ї–Є—В—М –∞–і—А–µ—Б –љ—Г–ґ–љ–Њ–є IAT-—П—З–µ–є–Ї–Є –Њ—В–љ–Њ—Б–Є—В–µ–ї—М–љ–Њ –њ–Њ–ї—Г—З–µ–љ–љ–Њ–≥–Њ EIP. –Р–±—Б–Њ–ї—О—В–љ—Л–µ –∞–і—А–µ—Б–∞ –≤ —В–∞–Ї–Њ–Љ —Б–ї—Г—З–∞–µ –≤–Њ–Њ–±—Й–µ –±—Л –љ–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–ї–Є—Б—М –Є –њ—А–Њ–±–ї–µ–Љ—Л —Б –Ј–∞–≥—А—Г–Ј–Ї–Њ–є –њ–Њ –љ–µ—А–Њ–і–љ–Њ–Љ—Г –±–∞–Ј–Њ–≤–Њ–Љ—Г –∞–і—А–µ—Б—Г (–љ–µ—А–Њ–і–љ–Њ–є –±–∞–Ј–µ) –љ–µ –±—Л–ї–Њ –±—Л –Є–Ј–љ–∞—З–∞–ї—М–љ–Њ. –Э–Њ! –≠—В–Њ—В —В—А—О–Ї –љ–µ –Њ—З–µ–љ—М ¬Ђ—З–Є—Б—В—Л–є¬ї –Є –Љ–Њ–ґ–µ—В –і–µ–є—Б—В–≤–Њ–≤–∞—В—М –љ–∞ –∞–љ—В–Є–≤–Є—А—Г—Б—Л –Ї–∞–Ї –Ї—А–∞—Б–љ–∞—П —В—А—П–њ–Ї–∞ –љ–∞ –±—Л–Ї–∞: –њ—А–Њ–±–ї–µ–Љ–∞ –±–∞–Ј–Њ–љ–µ–Ј–∞–≤–Є—Б–Є–Љ–Њ—Б—В–Є (—В–Њ—З–љ–µ–µ –±–∞–Ј–Њ–Ј–∞–≤–Є—Б–Є–Љ–Њ—Б—В–Є) вАФ —Н—В–Њ –Ї–ї–∞—Б—Б–Є—З–µ—Б–Ї–∞—П –њ—А–Њ–±–ї–µ–Љ–∞, –≤–Њ–Ј–љ–Є–Ї–∞—О—Й–∞—П –њ—А–Є –≤–љ–µ–і—А–µ–љ–Є–Є –љ–Њ–≤–Њ–≥–Њ –Ї–Њ–і–∞ –≤ —Г–ґ–µ —Б—Д–Њ—А–Љ–Є—А–Њ–≤–∞–љ–љ—Л–є PE-–Љ–Њ–і—Г–ї—М, –∞ –≤–љ–µ–і—А–µ–љ–Є—П–Љ–Є –Ј–∞–љ–Є–Љ–∞—О—В—Б—П –≤ 99% —Б–ї—Г—З–∞–µ–≤ –Є–Љ–µ–љ–љ–Њ –≤–Є—А—Г—Б—Л.
–Я–Њ—Н—В–Њ–Љ—Г –Љ—Л –Ј–∞–є–Љ—С–Љ—Б—П –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є–µ–є —В–∞–±–ї–Є—Ж—Л —А–µ–ї–Њ–Ї–Њ–≤. –Ъ—Б—В–∞—В–Є, –≤ OllyDbg –Љ–Њ–ґ–љ–Њ –Њ—З–µ–љ—М –ї–µ–≥–Ї–Њ —Г–≤–Є–і–µ—В—М –Љ–µ—Б—В–∞, –њ–Њ–і–≤–µ—А–≥–∞–µ–Љ—Л–µ –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є–Є –њ—А–Є —А–µ–ї–Њ–Ї–∞—Ж–Є–Є (–њ—А–Є –Ј–∞–≥—А—Г–Ј–Ї–µ –њ–Њ –љ–µ—А–Њ–і–љ–Њ–є –±–∞–Ј–µ) вАФ –њ—А–Є –Њ—В–Њ–±—А–∞–ґ–µ–љ–Є–Є –і–∞–Љ–њ–∞ —Б–µ–Ї—Ж–Є–Є —В–∞–Ї–Є–µ –Љ–µ—Б—В–∞ –њ–Њ–і—З—С—А–Ї–Є–≤–∞—О—В—Б—П —Б–µ—А–Њ–є –ї–Є–љ–Є–µ–є.
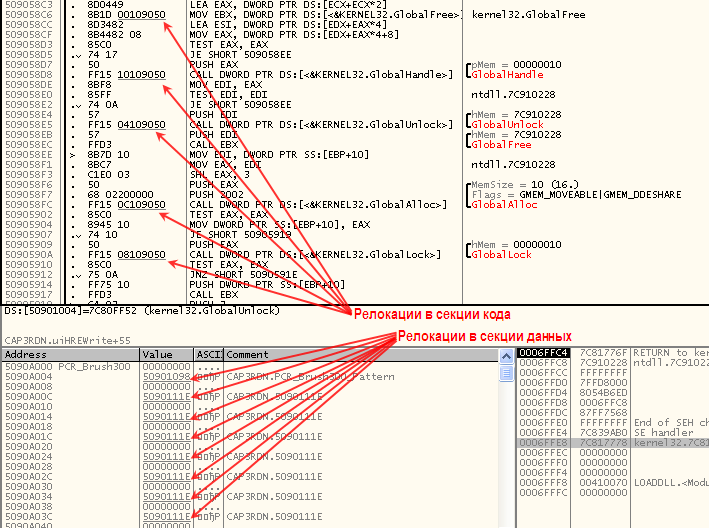
–Э–∞ —В–∞–Ї–Є–µ –њ–Њ–і—З—С—А–Ї–Є–≤–∞–љ–Є—П –љ—Г–ґ–љ–Њ –≤–љ–Є–Љ–∞—В–µ–ї—М–љ–Њ —Б–Љ–Њ—В—А–µ—В—М, –µ—Б–ї–Є –≤—Л –Љ–Њ–і–Є—Д–Є—Ж–Є—А—Г–µ—В–µ –Њ—А–Є–≥–Є–љ–∞–ї—М–љ—Л–є –Ї–Њ–і –≤ –њ—А—П–Љ–Њ –њ–Њ –Љ–µ—Б—В—Г: —В–∞–Љ, –≥–і–µ –і–Њ –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є–Є –Ї–Њ–і–∞ –±—Л–ї–Є –∞–±—Б–Њ–ї—О—В–љ—Л–µ –∞–і—А–µ—Б–∞, –љ—Г–ґ–і–∞—О—Й–Є–µ—Б—П –≤ –Ї–Њ—А—А–µ–Ї—Ж–Є–Є –њ—А–Є –њ–µ—А–µ–Љ–µ—Й–µ–љ–Є–Є, –њ–Њ—Б–ї–µ –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є–Є –Љ–Њ–≥—Г—В –Њ–Ї–∞–Ј–∞—В—М—Б—П –Њ–њ–Ї–Њ–і—Л –Є–ї–Є –∞—А–≥—Г–Љ–µ–љ—В—Л —Б–Њ–≤–µ—А—И–µ–љ–љ–Њ –і—А—Г–≥–Є—Е –Є–љ—Б—В—А—Г–Ї—Ж–Є–є, –Ї–Њ—В–Њ—А—Л–µ –±—Г–і—Г—В –љ–µ–Є–Ј–±–µ–ґ–љ–Њ –Є—Б–њ–Њ—А—З–µ–љ—Л —Б –љ–µ–њ—А–µ–і—Б–Ї–∞–Ј—Г–µ–Љ—Л–Љ–Є –њ–Њ—Б–ї–µ–і—Б—В–≤–Є—П–Љ–Є, –µ—Б–ї–Є –≤–і—А—Г–≥ –Њ–±—А–∞–Ј –њ—А–Є –Ј–∞–≥—А—Г–Ј–Ї–µ –±—Г–і–µ—В –Ј–∞–≥—А—Г–ґ–µ–љ –њ–Њ –љ–µ—А–Њ–і–љ–Њ–Љ—Г –±–∞–Ј–Њ–≤–Њ–Љ—Г –∞–і—А–µ—Б—Г.
–•–Њ—В—П —В–∞–±–ї–Є—Ж–∞ —А–µ–ї–Њ–Ї–∞—Ж–Є–є –Њ–±—Л—З–љ–Њ –ї–µ–ґ–Є—В –≤ –Њ—В–і–µ–ї—М–љ–Њ–є —Б–µ–Ї—Ж–Є–Є —Б –Є–Љ–µ–љ–µ–Љ
.reloc, –љ–Є –Є–Љ—П —Б–µ–Ї—Ж–Є–Є, –љ–Є —Б–∞–Љ —Д–∞–Ї—В –µ—С –љ–∞–ї–Є—З–Є—П вАФ –љ–µ –Є–≥—А–∞—О—В –љ–Є–Ї–∞–Ї–Њ–є —А–Њ–ї–Є. –Ч–∞–≥—А—Г–Ј—З–Є–Ї PE-–Љ–Њ–і—Г–ї–µ–є –≤ Windows-–љ–∞—Е–Њ–і–Є—В —В–∞–±–ї–Є—Ж—Г —А–µ–ї–Њ–Ї–∞—Ж–Є–є –≥–ї—П–і—П –≤ —В–∞–±–ї–Є—Ж—Г –і–Є—А–µ–Ї—В–Њ—А–Є–є –і–∞–љ–љ—Л—Е (–≤ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й–µ–є —П—З–µ–є–Ї–µ —В–∞–Љ —Е—А–∞–љ–Є—В—Б—П RVA –Є —А–∞–Ј–Љ–µ—А —В–∞–±–ї–Є—Ж—Л —А–µ–ї–Њ–Ї–∞—Ж–Є–є), —Б—Г—Й–µ—Б—В–≤–Њ–≤–∞–љ–Є–µ –њ—А–Є —Н—В–Њ–Љ –Њ—В–і–µ–ї—М–љ–Њ–є —Б–µ–Ї—Ж–Є–Є —Б –Ї–∞–Ї–Є–Љ-—В–Њ –Њ–њ—А–µ–і–µ–ї—С–љ–љ—Л–Љ –Є–Љ–µ–љ–µ–Љ —Б–Њ–≤–µ—А—И–µ–љ–љ–Њ –љ–µ –Њ–±—П–Ј–∞—В–µ–ї—М–љ–Њ вАФ —В–∞–±–ї–Є—Ж–∞ —А–µ–ї–Њ–Ї–∞—Ж–Є–є –Љ–Њ–ґ–µ—В –Ј–∞–њ—А–Њ—Б—В–Њ –ї–µ–ґ–∞—В—М –Є –≤ —Б–µ–Ї—Ж–Є–Є –Ї–Њ–і–∞ –Є–ї–Є –ї—О–±–Њ–є –і—А—Г–≥–Њ–є.
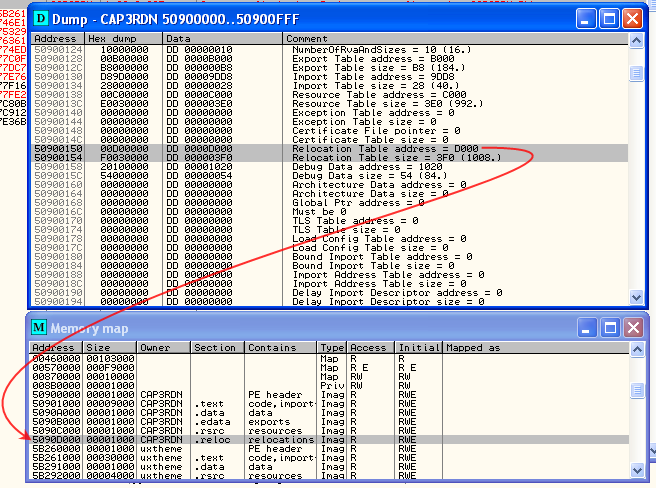
–Я–Њ—Б–Љ–Њ—В—А–Є–Љ –љ–∞ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й—Г—О —П—З–µ–є–Ї—Г —В–∞–±–ї–Є—Ж—Л –і–Є—А–µ–Ї—В–Њ—А–Є–є –і–∞–љ–љ—Л—Е –≤ —Б–Њ—Б—В–∞–≤–µ PE-–Ј–∞–≥–Њ–ї–Њ–≤–Ї–∞ –љ–∞—И–µ–≥–Њ –і—А–∞–є–≤–µ—А–∞. –Т –љ–∞—И–µ–Љ —Б–ї—Г—З–∞–µ –љ–∞—З–∞–ї–Њ —В–∞–±–ї–Є—Ж—Л —А–µ–ї–Њ–Ї–∞—Ж–Є–є —Б–Њ–≤–њ–∞–і–∞–µ—В —Б –љ–∞—З–∞–ї–Њ–Љ —Б–µ–Ї—Ж–Є–Є
.reloc:
–Х—Б–ї–Є –і–≤–∞–ґ–і—Л —Й—С–ї–Ї–љ—Г—В—М –њ–Њ —Б–µ–Ї—Ж–Є–Є
.reloc –≤ –Њ–Ї–љ–µ
Memory Map, –Њ—В–ї–∞–і—З–Є–Ї –њ–Њ–Ї–∞–ґ–µ—В –љ–∞–Љ —Б–Њ–і–µ—А–ґ–Є–Љ–Њ–µ —Н—В–Њ–є —Б–µ–Ї—Ж–Є–Є, –Є –Ї –љ–µ—А–∞–і–Њ—Б—В–Є –љ–µ–Є—Б–Ї—Г—И—С–љ–љ—Л—Е —В–Њ–≤–∞—А–Є—Й–µ–є —Б–Њ–і–µ—А–ґ–Є–Љ–Њ–µ –±—Г–і–µ—В –Њ—В–Њ–±—А–∞–ґ–µ–љ–Њ –≤–Њ—В —В–∞–Ї:
–Ш–љ—Л–Љ–Є —Б–ї–Њ–≤–∞–Љ–Є, –Њ—В–ї–∞–і—З–Є–Ї OllyDbg
–љ–µ —Г–Љ–µ–µ—В –љ–Њ—А–Љ–∞–ї—М–љ–Њ –Њ—В–Њ–±—А–∞–ґ–∞—В—М —В–∞–±–ї–Є—Ж—Г —А–µ–ї–Њ–Ї–∞—Ж–Є–є, –њ–Њ–Ї–∞–Ј—Л–≤–∞—П –µ—С —Н–ї–µ–Љ–µ–љ—В—Л, —Б—В—А—Г–Ї—В—Г—А—Л, –њ–Њ–ї—П, –Є—Е —Б–Љ—Л—Б–ї –Є –љ–∞–Ј–љ–∞—З–µ–љ–Є–µ. –Ґ–Њ—З–љ–Њ —В–∞–Ї –ґ–µ –Њ–љ –љ–µ –њ–Њ–Ј–≤–Њ–ї—П–µ—В –ї–µ–≥–Ї–Њ –≤–љ–Њ—Б–Є—В—М –≤ –љ–µ—С –њ—А–∞–≤–Ї–Є –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—О. –Ь–∞–Ї—Б–Є–Љ—Г–Љ вАФ¬†—Н—В–Њ –Њ—В–Њ–±—А–∞–ґ–µ–љ–Є–µ hex-–і–∞–Љ–њ–∞ —Б–µ–Ї—Ж–Є–Є –Є –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –њ—А–∞–≤–Є—В—М –њ—А–Њ–Є–Ј–≤–Њ–ї—М–љ—Л–µ –±–∞–є—В—Л –њ—А–Њ–Є–Ј–≤–Њ–ї—М–љ—Л–Љ –Њ–±—А–∞–Ј–Њ–Љ. OllyDbg –≤–µ—А—Б–Є–Є 2, –Ї–Њ—В–Њ—А—Л–є —Г –Љ–µ–љ—П —В–Њ–ґ–µ –µ—Б—В—М, –љ–Њ –Ї–Њ—В–Њ—А—Л–Љ —П —А–µ–ґ–µ –њ–Њ–ї—М–Ј—Г—О—Б—М (–Є–Ј-–Ј–∞ –Љ–µ–љ—М—И–µ–є —Б—В–∞–±–Є–ї—М–љ–Њ—Б—В–Є –Є –Њ—В—Б—Г—В—Б—В–≤–Є—П –њ–Њ–і–і–µ—А–ґ–Ї–Є –њ–ї–∞–≥–Є–љ–Њ–≤), –њ–Њ –њ—А–µ–ґ–љ–µ–Љ—Г –љ–µ —Г–Љ–µ–µ—В –Ї—А–∞—Б–Є–≤–Њ –Њ—В–Њ–±—А–∞–ґ–∞—В—М —В–∞–±–ї–Є—Ж—Г —А–µ–ї–Њ–Ї–Њ–≤.
–Э–Њ –љ–µ —Б—В–Њ–Є—В –Њ–њ—Г—Б–Ї–∞—В—М —А—Г–Ї–Є —А–∞–љ—М—И–µ –≤—А–µ–Љ–µ–љ–Є: —В–∞–±–ї–Є—Ж–∞ —А–µ–ї–Њ–Ї–∞—Ж–Є–є –Є–Љ–µ–µ—В —Б—А–∞–≤–љ–Є—В–µ–ї—М–љ–Њ –љ–µ—Б–ї–Њ–ґ–љ—Л–є —Д–Њ—А–Љ–∞—В, –Є –њ–Њ–љ—П–≤ –µ—С —Г—Б—В—А–Њ–є—Б—В–≤–Њ, –±—Г–і–µ—В –љ–µ —В–∞–Ї —Г–ґ —Б–ї–Њ–ґ–љ–Њ –і–Њ–њ–Њ–ї–љ–Є—В—М –µ—С –≥–Њ–ї—Л–Љ–Є —А—Г–Ї–∞–Љ–Є.
–Т—Б—П —В–∞–±–ї–Є—Ж–∞ —А–µ–ї–Њ–Ї–∞—Ж–Є–є (—В–∞–±–ї–Є—Ж–µ–є –Њ–љ–∞ –љ–∞–Ј—Л–≤–∞–µ—В—Б—П –≤–µ—Б—М–Љ–∞ —Г—Б–ї–Њ–≤–љ–Њ) –њ—А–µ–і—Б—В–∞–≤–ї—П–µ—В —Б–Њ–±–Њ–є –њ–Њ—Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ–Њ—Б—В—М
–±–ї–Њ–Ї–Њ–≤. –†–∞–Ј–Љ–µ—А –±–ї–Њ–Ї–Њ–≤ –љ–µ —Д–Є–Ї—Б–Є—А–Њ–≤–∞–љ–љ—Л–є. –Ъ–∞–ґ–і—Л–є –±–ї–Њ–Ї —Б–Њ—Б—В–Њ–Є—В –Є–Ј 8-–±–∞–є—В–љ–Њ–≥–Њ –Ј–∞–≥–Њ–ї–Њ–≤–Ї–∞ (–і–≤–∞ DWORD-–∞), —Б –Ї–Њ—В–Њ—А–Њ–≥–Њ –љ–∞—З–Є–љ–∞–µ—В—Б—П –±–ї–Њ–Ї, –Є –љ–µ–Ї–Њ—В–Њ—А–Њ–≥–Њ —З–Є—Б–ї–∞ 2-–±–∞–є—В–љ—Л—Е —Н–ї–µ–Љ–µ–љ—В–Њ–≤, –Ї–Њ—В–Њ—А—Л–µ –Є–і—Г—В —Б–ї–µ–і–Њ–Љ –Ј–∞ –Ј–∞–≥–Њ–ї–Њ–≤–Ї–Њ–Љ.
–Ч–∞–≥–Њ–ї–Њ–≤–Њ–Ї —Б–Њ—Б—В–Њ–Є—В –Є–Ј –і–≤—Г—Е DWORD-–њ–Њ–ї–µ–є вАФ –≤ –Њ–і–љ–Њ–Љ –Є–Ј –љ–Є—Е —Е—А–∞–љ–Є—В—Б—П —А–∞–Ј–Љ–µ—А –±–ї–Њ–Ї–∞ –≤ –±–∞–є—В–∞—Е (–≤–Ї–ї—О—З–∞—П —Б–∞–Љ –Ј–∞–≥–Њ–ї–Њ–≤–Њ–Ї, –≤—Б–µ 2-–±–∞–є—В–љ—Л–µ —Н–ї–µ–Љ–µ–љ—В—Л –≤ —Б–Њ—Б—В–∞–≤–µ —Н—В–Њ–≥–Њ –±–ї–Њ–Ї–∞ –Є –≤—Л—А–∞–≤–љ–Є–≤–∞—О—Й–Є–µ –љ—Г–ї–Є –≤ –Ї–Њ–љ—Ж–µ –±–ї–Њ–Ї–∞ (–µ—Б–ї–Є –Њ–љ–Є –µ—Б—В—М)). –°–ї–µ–і–Њ–Љ –Ј–∞ –Ј–∞–≥–Њ–ї–Њ–≤–Ї–Њ–Љ –Є–і—Г—В —Н–ї–µ–Љ–µ–љ—В—Л: –Ї–∞–ґ–і—Л–є —Н–ї–µ–Љ–µ–љ—В (16 –±–Є—В) –Њ–њ–Є—Б—Л–≤–∞–µ—В –Њ—В–µ–ї—М–љ–Њ–µ –Љ–µ—Б—В–Њ –≤ –Њ–±—А–∞–Ј–µ, –Ї–Њ—В–Њ—А–Њ–µ –њ–Њ–і–ї–µ–ґ–Є—В –Ї–Њ—А—А–µ–Ї—Ж–Є–Є –≤ —Б–ї—Г—З–∞–µ –Ј–∞–≥—А—Г–Ј–Ї–Є –њ–Њ –љ–µ—А–Њ–і–љ–Њ–є –±–∞–Ј–µ. –Я–Њ—Б–Ї–Њ–ї—М–Ї—Г —З–Є—Б–ї–Њ —Н–ї–µ–Љ–µ–љ—В–Њ–≤ –≤ –±–ї–Њ–Ї–µ –Љ–Њ–ґ–µ—В –±—Л—В—М –љ–µ—З—С—В–љ—Л–Љ, –Є—В–Њ–≥–Њ–≤—Л–є —А–∞–Ј–Љ–µ—А –±–ї–Њ–Ї–∞ –Љ–Њ–ґ–µ—В –Њ–Ї–∞–Ј–∞—В—М—Б—П –љ–µ –Ї—А–∞—В–љ—Л–Љ 4 –±–∞–є—В–∞–Љ. –Я–Њ —Н—В–Њ–є –њ—А–Є—З–Є–љ–µ –љ–∞—З–∞–ї–∞ –±–ї–Њ–Ї–Њ–≤ –≤—Л—А–∞–≤–љ–Є–≤–∞—О—В—Б—П –њ–Њ 4-–±–∞–є—В–љ–Њ–є –≥—А–∞–љ–Є—Ж–µ, –∞ –Ї–Њ–љ—Ж—Л –њ—А–µ–і—И–µ—Б—В–≤—Г—О—Й–Є—Е –±–ї–Њ–Ї–Њ–≤ –і–Њ–±–Є–≤–∞—О—В—Б—П –і–Њ —Н—В–Њ–є –≥—А–∞–љ–Є—Ж—Л –љ—Г–ї—П–Љ–Є.
–°—В—А—Г–Ї—В—Г—А–∞ 16-–±–Є—В–љ–Њ–≥–Њ —Н–ї–µ–Љ–µ–љ—В–∞ –≤ —Б–Њ—Б—В–∞–≤–µ –±–ї–Њ–Ї–∞ —Б–ї–µ–і—Г—О—Й–∞—П: –Љ–ї–∞–і—И–Є–µ 12 –±–Є—В —Е—А–∞–љ—П—В —Б–Љ–µ—Й–µ–љ–Є–µ –Ї–Њ—А—А–µ–Ї—В–Є—А—Г–µ–Љ–Њ–≥–Њ –Љ–µ—Б—В–∞, –∞ —Б—В–∞—А—И–Є–µ 4 –±–Є—В–∞ вАФ —В–Є–њ —А–µ–ї–Њ–Ї–∞ (–∞ –Є—Е —Б—Г—Й–µ—Б—В–≤—Г–µ—В –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ —А–∞–Ј–љ—Л—Е –≤–Є–і–Њ–≤ вАФ –Њ–± —Н—В–Њ–Љ –љ–Є–ґ–µ). –Я–Њ—Б–Ї–Њ–ї—М–Ї—Г —Б–Љ–µ—Й–µ–љ–Є–µ –Њ—В–љ–Њ—Б–Є—В–µ–ї—М–љ–Њ –±–∞–Ј—Л (–Є–љ—Л–Љ–Є —Б–ї–Њ–≤–∞–Љ–Є вАФ RVA) –љ–µ —Б–њ–Њ—Б–Њ–±–љ–Њ —Г–Љ–µ—Б—В–Є—В—М—Б—П –≤ 12-–±–Є—В–љ–Њ–µ –њ–Њ–ї–µ, –Њ–±—Й–Є–є (–і–ї—П –≤—Б–µ—Е —Н–ї–µ–Љ–µ–љ—В–Њ–≤ –Њ–і–љ–Њ–≥–Њ –±–ї–Њ–Ї–∞) RVA —Е—А–∞–љ–Є—В—Б—П –≤ –Ј–∞–≥–Њ–ї–Њ–≤–Ї–µ –±–ї–Њ–Ї–∞ (—Н—В–Њ –≤—В–Њ—А–Њ–µ –Є–Ј –њ–Њ–ї–µ–є –Ј–∞–≥–Њ–ї–Њ–≤–Ї–∞, –Ї—А–Њ–Љ–µ –њ–Њ–ї—П —Б —А–∞–Ј–Љ–µ—А–Њ–Љ –±–ї–Њ–Ї–∞), –∞ –≤ –Ї–∞–ґ–і–Њ–Љ —Н–ї–µ–Љ–µ–љ—В–µ —Е—А–∞–љ–Є—В—Б—П —Б–Љ–µ—Й–µ–љ–Є–µ –Ї–Њ—А—А–µ–Ї—В–Є—А—Г–µ–Љ–Њ–≥–Њ –Љ–µ—Б—В–∞ –Њ—В–љ–Њ—Б–Є—В–µ–ї—М–љ–Њ –Њ–±—Й–µ–≥–Њ –і–ї—П –≤—Б–µ–≥–Њ –±–ї–Њ–Ї–∞ RVA.
–Ш–љ—Л–Љ–Є —Б–ї–Њ–≤–∞–Љ–Є, –Ї–∞–ґ–і—Л–є —В–∞–Ї–Њ–є –±–ї–Њ–Ї —В–∞–±–ї–Є—Ж—Л —А–µ–ї–Њ–Ї–∞—Ж–Є–є —Б–Њ–њ–Њ—Б—В–∞–≤–ї—П–µ—В—Б—П —Б —Г—З–∞—Б—В–Ї–Њ–Љ –Њ–±—А–∞–Ј–∞ —А–∞–Ј–Љ–µ—А–Њ–Љ 4 –Ъ–± (–њ–Њ —З–Є—Б—В–Њ–Љ—Г —Б–Њ–≤–њ–∞–і–µ–љ–Є—О —А–∞–Ј–Љ–µ—А —А–µ–≥–Є–Њ–љ–∞, –Њ–њ–Є—Б—Л–≤–∞–µ–Љ–Њ–≥–Њ –Њ–і–љ–Є–Љ –±–ї–Њ–Ї–Њ–Љ —В–∞–±–ї–Є—Ж—Л —А–µ–ї–Њ–Ї–∞—Ж–Є–є, —Б–Њ–≤–њ–∞–і–∞–µ—В —Б —А–∞–Ј–Љ–µ—А–Њ–Љ —Б—В—А–∞–љ–Є—Ж—Л x86). –Т –Ј–∞–≥–Њ–ї–Њ–≤–Ї–µ –±–ї–Њ–Ї–∞ –ї–µ–ґ–Є—В RVA —З–µ—В—Л—А—С—Е–Ї–Є–ї–Њ–±–∞–є—В–љ–Њ–≥–Њ –Њ–Ї–љ–∞, –љ–∞ –Ї–Њ—В–Њ—А–Њ–µ –њ—А–Є—Е–Њ–і–Є—В—Б—П –љ–µ–Ї–Њ—В–Њ—А–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —А–µ–ї–Њ–Ї–∞—Ж–Є–є, –∞ –Ї–∞–ґ–і—Л–є —Н–ї–µ–Љ–µ–љ—В –≤ —Б–Њ—Б—В–∞–≤–µ –±–ї–Њ–Ї–∞ –Њ–њ–Є—Б—Л–≤–∞–µ—В –Њ–њ–Є—Б—Л–≤–∞–µ—В –Њ–і–љ—Г –Њ—В–і–µ–ї—М–љ–Њ –≤–Ј—П—В—Г—О —А–µ–ї–Њ–Ї–∞—Ж–Є—О –Є–Ј —Н—В–Њ–≥–Њ –Њ–Ї–љ–∞ –Є —Е—А–∞–љ–Є—В –≤ —Б–µ–±–µ —Б–Љ–µ—Й–µ–љ–Є–µ —Н—В–Њ–є —А–µ–ї–Њ–Ї–∞—Ж–Є–Є –Њ—В–љ–Њ—Б–Є—В–µ–ї—М–љ–Њ –љ–∞—З–∞–ї–∞ —З–µ—В—Л—А—С—Е–Ї–Є–ї–Њ–±–∞–є—В–љ–Њ–≥–Њ –Њ–Ї–љ–∞ –Є —В–Є–њ —А–µ–ї–Њ–Ї–∞—Ж–Є–Є. –Я—А–Є—З—С–Љ 4 –Ї–± —А–µ–≥–Є–Њ–љ, –Њ–њ–Є—Б—Л–≤–∞–µ–Љ—Л–є –Њ—В–і–µ–ї—М–љ—Л–Љ –±–ї–Њ–Ї–Њ–Љ, –љ–µ –Њ–±—П–Ј–∞–љ –±—Л—В—М –≤—Л—А–Њ–≤–љ–µ–љ –њ–Њ –≥—А–∞–љ–Є—Ж–µ —Б—В—А–∞–љ–Є—Ж—Л, –±–ї–Њ–Ї–Є –≤ –њ—А–Є–љ—Ж–Є–њ–µ –Љ–Њ–≥—Г—В –Є–Љ–µ—В—М –љ–∞—З–∞–ї–∞ –≤ –њ—А–Њ–Є–Ј–≤–Њ–ї—М–љ—Л—Е –Љ–µ—Б—В–∞—Е –Њ–±—А–∞–Ј–∞ –Є –≤–Њ–Њ–±—Й–µ –њ–µ—А–µ—Б–µ–Ї–∞—В—М—Б—П –Љ–µ–ґ–і—Г —Б–Њ–±–Њ–є.
–Я—А–Є–Љ–µ—З–∞—В–µ–ї—М–љ–Њ, —З—В–Њ –≤ —Б–Њ—Б—В–∞–≤–µ 16-–±–Є—В–љ–Њ–≥–Њ —Н–ї–µ–Љ–µ–љ—В–∞ –њ–Њ–ї—П —А–∞–Ј–і–µ–ї–µ–љ—Л –њ–Њ —И–Є—А–Є–љ–µ –Є–Љ–µ–љ–љ–Њ –Ї–∞–Ї 4 –Є 12 –±–Є—В: –њ—А–Є —В–∞–Ї–Њ–Љ —А–∞–Ј–і–µ–ї–µ–љ–Є–Є –≤ hex-–Ј–∞–њ–Є—Б–Є 12-–±–Є—В–љ–Њ–Љ—Г –њ–Њ–ї—О (—Е—А–∞–љ—П—Й–µ–Љ—Г —Б–Љ–µ—Й–µ–љ–Є–µ) —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В 3 –Љ–ї–∞–і—И–Є—Е hex-—Ж–Є—Д—А—Л, –∞ 4-–±–Є—В–љ–Њ–Љ—Г –њ–Њ–ї—О (—Е—А–∞–љ—П—Й–µ–Љ—Г —В–Є–њ) —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В —Б—В–∞—А—И–∞—П hex-—Ж–Є—Д—А–∞.
–Ґ–µ–њ–µ—А—М —З—В–Њ –Ї–∞—Б–∞–µ—В—Б—П —В–Є–њ–Њ–≤ —А–µ–ї–Њ–Ї–∞—Ж–Є–є: –Є—Е –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ. –Ъ–∞–Ї –Љ–Є–љ–Є–Љ—Г–Љ, –Є—Б—Е–Њ–і—П –Є–Ј —В–Њ–≥–Њ —Д–∞–Ї—В–∞, —З—В–Њ –њ–Њ–і —Е—А–∞–љ–µ–љ–Є–µ —В–Є–њ–∞ —А–µ–ї–Њ–Ї–∞—Ж–Є–Є –≤—Л–і–µ–ї–µ–љ–Њ 4 –±–Є—В–∞, –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –≤–Њ–Ј–Љ–Њ–ґ–љ—Л—Е –Ј–љ–∞—З–µ–љ–Є–є —Н—В–Њ–≥–Њ –њ–Њ–ї—П —А–∞–≤–љ–Њ 16. –Э–∞ —Б–∞–Љ–Њ–Љ –ґ–µ –і–µ–ї–µ, –Ј–∞–≥—А—Г–Ј—З–Є–Ї Windows —А–∞–Ј–ї–Є—З–∞–µ—В 12 —В–Є–њ–Њ–≤ —А–µ–ї–Њ–Ї–∞—Ж–Є–є:
- –Ъ–Њ–і: –Т—Л–і–µ–ї–Є—В—М –≤—Б—С
0 ABSOLUTE
1 HIGH
2 LOW
3 HIGHLOW
4 HIGHADJ
5 MIPS_JMPADDR
6 SECTION
7 REL32
9 IA64_IMM64
10 DIR64
11 HIGH3ADJ
–Ґ–Є–њ —А–µ–ї–Њ–Ї–∞—Ж–Є–Є –Њ–њ—А–µ–і–µ–ї—П–µ—В, —Б–Ї–Њ–ї—М–Ї–Њ –±–∞–є—В–Њ–≤ –Є –њ–Њ –Ї–∞–Ї–Њ–Љ—Г –њ—А–Є–љ—Ж–Є–њ—Г –Ї–Њ—А—А–µ–Ї—В–Є—А—Г–µ—В—Б—П. –Я–Њ—Б–Ї–Њ–ї—М–Ї—Г —А–µ–ї–Њ–Ї–∞—Ж–Є–Є –Ї–∞–Ї –њ—А–∞–≤–Є–ї–Њ –Ї–Њ—А—А–µ–Ї—В–Є—А—Г—О—В –∞–±—Б–Њ–ї—О—В–љ—Л–µ –∞–і—А–µ—Б–∞, –Ї–Њ—А—А–µ–Ї—Ж–Є–Є –Љ–Њ–ґ–µ—В –њ–Њ–і–≤–µ—А–≥–∞—В—М—Б—П —Б—В–∞—А—И–∞—П —З–∞—Б—В—М –∞–і—А–µ—Б–∞, –Љ–ї–∞–і—И–∞—П —З–∞—Б—В—М, —Б—В–∞—А—И–∞—П –Є –Љ–ї–∞–і—И–∞—П —З–∞—Б—В–Є –Є —В.–њ.
–Ґ–Є–њ—Л
MIPS_JMPADDR –Є
IA64_IMM64 –љ–µ –Њ—В–љ–Њ—Б—П—В—Б—П –Ї –∞—А—Е–Є—В–µ–Ї—В—Г—А–µ x86. –Ґ–Є–њ
ABSOLUTE –Њ–Ј–љ–∞—З–∞–µ—В, —З—В–Њ –Ї–Њ—А—А–µ–Ї—Ж–Є—П –∞–і—А–µ—Б–∞ –љ–µ —В—А–µ–±—Г–µ—В—Б—П (–≤–Њ–њ—А–µ–Ї–Є –љ–∞–Ј–≤–∞–љ–Є—О, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –∞–±—Б–Њ–ї—О—В–љ—Л–Љ –∞–і—А–µ—Б–∞–Љ –Ї–∞–Ї —А–∞–Ј —В–∞–Ї–Є –Ї–Њ—А—А–µ–Ї—Ж–Є—П –Є –љ—Г–ґ–љ–∞ вАФ –≤–Є–і–Є–Љ–Њ –Є–Љ–µ–µ—В—Б—П –≤ –≤–Є–і—Г –∞–±—Б–Њ–ї—О—В–љ—Л–є –∞–і—А–µ—Б, –∞–і—А–µ—Б—Г—О—Й–Є–є —З—В–Њ-—В–Њ, –љ–∞—Е–Њ–і—П—Й–µ–µ—Б—П –≤–љ–µ –њ—А–µ–і–µ–ї–Њ–≤ –њ–µ—А–µ–Љ–µ—Й–∞–µ–Љ–Њ–≥–Њ –Њ–±—А–∞–Ј–∞. –Ґ–Є–њ–∞–Љ
SECTION –Є
REL32 –≤ –Ј–∞–≥—А—Г–Ј—З–Є–Ї–µ Windows –њ–Њ–Ї–∞ –љ–µ –њ—А–Є–і—Г–Љ–∞–љ–Њ –љ–Є–Ї–∞–Ї–Њ–є –Њ–±—А–∞–±–Њ—В–Ї–Є вАФ –Њ–љ–Є –њ–Њ–њ—А–Њ—Б—В—Г –Є–≥–љ–Њ—А–Є—А—Г—О—В—Б—П. –°–∞–Љ—Л–Љ —И–Є—А–Њ–Ї–Њ–Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ—Л–Љ —П–≤–ї—П–µ—В—Б—П —В–Є–њ
HIGHLOW —Б –Ї–Њ–і–Њ–Љ 3, –Њ–Ј–љ–∞—З–∞—О—Й–Є–є, —З—В–Њ –њ—А–Њ—Б—В–Њ –±–µ—А—С—В—Б—П DWORD –Є –Ї–Њ—А—А–µ–Ї—В–Є—А—Г–µ—В—Б—П –љ–∞ –љ—Г–ґ–љ—Г—О –≤–µ–ї–Є—З–Є–љ—Г.
–Ф–∞–ґ–µ –µ—Б–ї–Є —Б–µ–є—З–∞—Б –њ–Њ—Б–Љ–Њ—В—А–µ—В—М –љ–∞ —Б–Ї—А–Є–љ—И–Њ—В –і–∞–Љ–њ–∞ —Б–µ–Ї—Ж–Є–Є —А–µ–ї–Њ–Ї–∞—Ж–Є–є (–≤—Л—И–µ), —В–Њ –≤–Є–і–љ–Њ, —З—В–Њ –±–Њ–ї—М—И–Є–љ—Б—В–≤–Њ DWORD-–Њ–≤ –Є–Љ–µ–µ—О—В —В—А–Њ–є–Ї—Г –≤ –њ–Њ–Ј–Є—Ж–Є–Є 8-–Њ–є –Є 4-–Њ–є —Ж–Є—Д—А. –Я–Њ—Б–Ї–Њ–ї—М–Ї—Г —В–Є–њ
ABSOLUTE –љ–∞ –њ—А–∞–Ї—В–Є–Ї–µ –љ–Є–Ї–Њ–≥–і–∞ –љ–µ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П, –Љ–Њ–ґ–љ–Њ –≤–Є–Ј—Г–∞–ї—М–љ–Њ –ї–µ–≥–Ї–Њ –љ–∞—Е–Њ–і–Є—В—М –≥—А–∞–љ–Є—Ж—Л –±–ї–Њ–Ї–Њ–≤: –≤–µ–і—М –±–ї–Њ–Ї–Є –љ–∞—З–Є–љ–∞—О—В—Б—П —Б –Ј–∞–≥–Њ–ї–Њ–≤–Ї–Њ–≤, –∞ –Ј–∞–≥–Њ–ї–Њ–≤–Њ–Ї —Е—А–∞–љ–Є—В –і–≤–∞ –Ј–љ–∞—З–µ–љ–Є—П (RVA –Њ–Ї–љ–∞ –Є —А–∞–Ј–Љ–µ—А –±–ї–Њ–Ї–∞), –Ї–Њ—В–Њ—А—Л–µ –љ–∞ –њ—А–∞–Ї—В–Є–Ї–µ –љ–Є–Ї–Њ–≥–і–∞ –љ–µ –±—Л–≤–∞—О—В –љ–∞—Б—В–Њ–ї—М–Ї–Њ –±–Њ–ї—М—И–Є–Љ–Є, —З—В–Њ–±—Л –Є–Љ–µ—В—М —Б—В–∞—А—И–Є–µ 4 –±–Є—В–∞ –Њ—В–ї–Є—З–љ—Л–µ –Њ—В –љ—Г–ї—П.
–Х—Б–ї–Є –≤–љ–Њ–≤—М –≤–Ј–≥–ї—П–љ—Г—В—М –љ–∞ —Б–Њ–і–µ—А–ґ–Є–Љ–Њ–µ —Б–µ–Ї—Ж–Є–Є —А–µ–ї–Њ–Ї–Њ–≤, –Є–Љ–µ—П –≤—Б–µ –≤—Л—И–µ–Є–Ј–ї–Њ–ґ–µ–љ–љ—Л–µ –Ј–љ–∞–љ–Є—П, –Љ–Њ–ґ–љ–Њ –ї–µ–≥–Ї–Њ —Г–≤–Є–і–µ—В—М –≥—А–∞–љ–Є—Ж—Л –±–ї–Њ–Ї–Њ–≤ (–Є—Е —В—Г—В 6), –Ј–∞–≥–Њ–ї–Њ–≤–Ї–Є –±–ї–Њ–Ї–Њ–≤ –Є —Н–ї–µ–Љ–µ–љ—В—Л (–Њ–љ–Є –≤—Б–µ —Б–њ–ї–Њ—И—М —Б–Њ–і–µ—А–ґ–∞—В —В—А–Њ–є–Ї–Є –Ї–Њ–ї–Њ–љ–Ї–∞–Љ–Є):
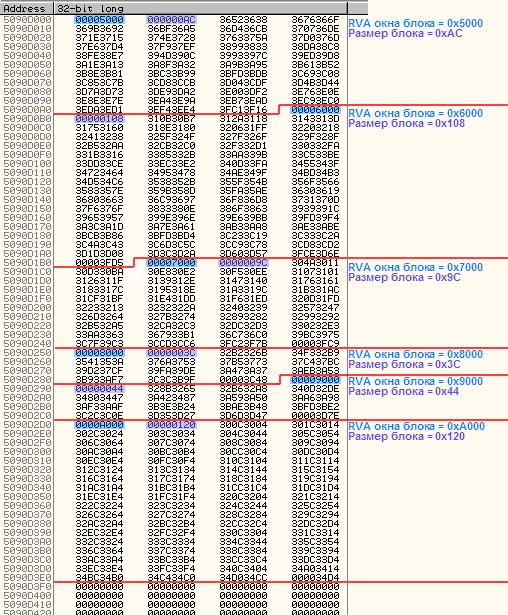
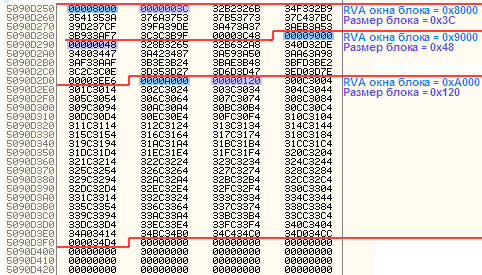
–Ь–Њ–ґ–љ–Њ –љ–∞ –њ—А–Є–Љ–µ—А–µ –њ–µ—А–≤–Њ–≥–Њ –±–ї–Њ–Ї–∞ —А–∞—Б—Б–Љ–Њ—В—А–µ—В—М —Б—В—А—Г–Ї—В—Г—А—Г —Н–ї–µ–Љ–µ–љ—В–Њ–≤: –µ—Б–ї–Є –≤ —Б–Њ—Б—В–∞–≤–µ –Ї–∞–ґ–і–Њ–≥–Њ —Н–ї–µ–Љ–µ–љ—В–∞ —А–∞—Б–Ї—А–∞—Б–Є—В—М 12-–±–Є—В–љ–Њ–µ –њ–Њ–ї–µ, —Е—А–∞–љ—П—Й–µ–µ —Б–Љ–µ—Й–µ–љ–Є–µ –Ї–Њ—А—А–µ–Ї—В–Є—А—Г–µ–Љ–Њ–≥–Њ –Љ–µ—Б—В–∞ –Њ—В–љ–Њ—Б–Є—В–µ–ї—М–љ–Њ –љ–∞—З–∞–ї–∞ –Њ–Ї–љ–∞ –±–ї–Њ–Ї–∞, —В–Њ –≤—Л–≥–ї—П–і–µ—В—М —Н—В–Њ –±—Г–і–µ—В –≤–Њ—В —В–∞–Ї:
–Ґ—А–Њ–є–Ї–Є, –Ї–Њ—В–Њ—А—Л–µ –Њ—Б—В–∞–ї–Є—Б—М –љ–µ–Ј–∞–Ї—А–∞—И–µ–љ–љ—Л–Љ–Є вАФ —Н—В–Њ 4-–±–Є—В–љ–Њ–µ (—Б—В–∞—А—И–Є–µ 4 –±–Є—В–∞) –њ–Њ–ї–µ, —Е—А–∞–љ—П—Й–µ–µ —В–Є–њ —Н–ї–µ–Љ–µ–љ—В–∞.
–Ъ–∞–Ї –≤–Є–і–љ–Њ, –≤—Б–µ —Н–ї–µ–Љ–µ–љ—В—Л –Ј–і–µ—Б—М –Є–Љ–µ—О—В —В–Є–њ
HIGHLOW.
–Ґ–µ–њ–µ—А—М, –≥–ї—П–і—П –љ–∞ —Ж–Є—Д—А—Л, –Ї–Њ—В–Њ—А—Л–µ –љ–∞ –њ–µ—А–≤—Л–є –≤–Ј–≥–ї—П–і –Ї–∞–Ј–∞–ї–Є—Б—М —Е–∞–Њ—В–Є—З–љ—Л–Љ–Є, –Є –≤–Є–і—П –Ј–∞ –љ–Є–Љ–Є —З—С—В–Ї—Г—О –њ–Њ–љ—П—В–љ—Г—О —Б—В—А—Г–Ї—В—Г—А—Г, –Ј–∞–і–∞—З–∞ –≤–љ–µ—Б–µ–љ–Є—П –≤ —В–∞–±–ї–Є—Ж—Г —А–µ–ї–Њ–Ї–∞—Ж–Є–є –њ–∞—А—Л –љ–Њ–≤—Л—Е —Н–ї–µ–Љ–µ–љ—В–Њ–≤ –Ї–∞–ґ–µ—В—Б—П —Б–Њ–≤—Б–µ–Љ —Г–ґ –њ—А–Њ—Б—В–Њ–є.
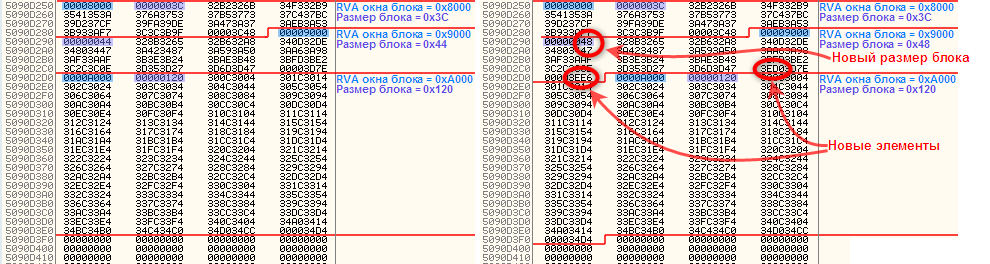
–£ –љ–∞—Б –µ—Б—В—М –і–≤–∞ –Љ–µ—Б—В–∞, –Ї–Њ—В–Њ—А—Л–µ –і–Њ–ї–ґ–љ—Л –Ї–Њ—А—А–µ–Ї—В–Є—А–Њ–≤–∞—В—М—Б—П –њ—А–Є –Ј–∞–≥—А—Г–Ј–Ї–µ –њ–Њ –љ–µ—И—В–∞—В–љ–Њ–Љ—Г –±–∞–Ј–Њ–≤–Њ–Љ—Г –∞–і—А–µ—Б—Г:
–Ш—Е –∞–і—А–µ—Б–∞:
- VA –њ—А–Є –Ј–∞–≥—А—Г–Ј–Ї–µ –њ–Њ —И—В–∞—В–љ–Њ–є –±–∞–Ј–µ: 0x50909ECE+2=0x50909ED0 / RVA: 0x9ED0
- VA –њ—А–Є –Ј–∞–≥—А—Г–Ј–Ї–µ –њ–Њ —И—В–∞—В–љ–Њ–є –±–∞–Ј–µ: 0x50909EE4+2=0x50909EE6 / RVA: 0x9EE6
–Ю–±–∞ –Љ–µ—Б—В–∞ –њ–Њ–њ–∞–і–∞—О—В –≤ –Њ–Ї–љ–Њ –њ—А–µ–і–њ–Њ—Б–ї–µ–і–љ–µ–≥–Њ –±–ї–Њ–Ї–∞ (RVA –љ–∞—З–∞–ї–∞ –Њ–Ї–љ–∞ =
0x9000), –љ–Њ –Ї –±–ї–Њ–Ї–µ –љ–µ—В —Б–≤–Њ–±–Њ–і–љ–Њ–≥–Њ –Љ–µ—Б—В–∞, –Ї–Њ—В–Њ—А–Њ–µ –Љ–Њ–ґ–љ–Њ –±—Л–ї–Њ –±—Л –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М.
–Т—Л—Е–Њ–і–∞ –і–≤–∞:
- –Ф–Њ–±–∞–≤–Є—В—М –≤ –Ї–Њ–љ–µ—Ж –µ—Й—С –Њ–і–Є–љ –љ–Њ–≤—Л–є –±–ї–Њ–Ї: —Б RVA –Њ–Ї–љ–∞ = 0x9000, —А–∞–Ј–Љ–µ—А–Њ–Љ –±–ї–Њ–Ї–∞ = 12 –±–∞–є—В –Є –і–≤—Г–Љ—П 16-–±–Є—В–љ—Л–Љ–Є —Н–ї–µ–Љ–µ–љ—В–∞–Љ–Є.
- –†–∞—Б—И–Є—А–Є—В—М –њ—А–µ–і–њ–Њ—Б–ї–µ–і–љ–Є–є –±–ї–Њ–Ї, –њ–Њ–і–≤–Є–љ—Г–≤ –њ–Њ—Б–ї–µ–і–љ–Є–є –±–ї–Њ–Ї –љ–∞ 4 –±–∞–є—В–∞ –≤–њ–µ—А—С–і, –≤ –Ї–Њ–љ–µ—Ж –њ—А–µ–і–њ–Њ—Б–ї–µ–і–љ–µ–≥–Њ –±–ї–Њ–Ї–∞ –≤—Б—В–∞–≤–Є—В—М 2 –љ–Њ–≤—Л—Е —Н–ї–µ–Љ–µ–љ—В–∞
–Я–Њ—Б–Ї–Њ–ї—М–Ї—Г OllyDbg –Є–Љ–µ–µ—В –Ї–Њ–Љ–∞–љ–і—Л
Binary Copy –Є
Binary Paste, –љ–µ—В –љ–Є–Ї–∞–Ї–Њ–є –њ—А–Њ–±–ї–µ–Љ—Л –њ–Њ–і–≤–Є–љ—Г—В—М –њ–Њ—Б–ї–µ–і–љ–Є–є –±–ї–Њ–Ї –љ–∞ 4 –±–∞–є—В–∞ –≤–њ–µ—А—С–і, –Є —П –≤—Л–±–Є—А–∞—О –Є–Љ–µ–љ–љ–Њ —Н—В–Њ—В –њ—Г—В—М.
- –°–і–≤–Є–≥–∞–µ–Љ –њ–Њ—Б–ї–µ–і–љ–Є–є –±–ї–Њ–Ї –љ–∞ 4 –±–∞–є—В–∞ –≤–њ–µ—А—С–і, –≤ –њ—А–µ–і–њ–Њ—Б–ї–µ–і–љ–µ–Љ –±–ї–Њ–Ї–µ –Љ–µ–љ—П–µ–Љ —А–∞–Ј–Љ–µ—А 0x44 –љ–∞ 0x48.
- –Ю–Ї–љ–Њ —Н—В–Њ–≥–Њ –±–ї–Њ–Ї–∞ –љ–∞—З–Є–љ–∞–µ—В—Б—П –њ–Њ RVA=0x9000, —В–Њ–≥–і–∞ 12-–±–Є—В–љ–Њ–µ —Б–Љ–µ—Й–µ–љ–Є–µ –Ї–Њ—А—А–µ–Ї—В–Є—А—Г–µ–Љ—Л—Е –Љ–µ—Б—В –Њ—В–љ–Њ—Б–Є—В–µ–ї—М–љ–Њ –љ–∞—З–∞–ї–∞ –Њ–Ї–љ–∞ –±—Г–і–µ—В 0x0ED0 –Є 0x0EE6.
- –°—В–∞—А—И–Є–µ 4 –±–Є—В–∞ —Г —Н–ї–µ–Љ–µ–љ—В–Њ–≤ –і–Њ–ї–ґ–љ—Л –±—Л—В—М —А–∞–≤–љ—Л –Ј–љ–∞—З–µ–љ–Є—О 3 (—В–Є–њ HIGHLOW), –њ–Њ—Н—В–Њ–Љ—Г –≤ –Ї–∞—З–µ—Б—В–≤–µ —Н–ї–µ–Љ–µ–љ—В–Њ–≤ –і–Њ–њ–Є—Б—Л–≤–∞–µ–Љ –≤ –Ї–Њ–љ–µ—Ж –њ—А–µ–і–њ–Њ—Б–ї–µ–і–љ–µ–≥–Њ –±–ї–Њ–Ї–∞ —Б–ї–Њ–≤–∞ 3ED0 –Є 3EE6
–Я–Њ—Б–ї–µ —Н—В–Є—Е –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є–є –Ї–Њ–љ—Ж–Њ–≤–Ї–∞ —Б–µ–Ї—Ж–Є–Є —А–µ–ї–Њ–Ї–Њ–≤ –≤—Л–≥–ї—П–і–Є—В —В–∞–Ї:
–Т–Њ—В –Є–ї–ї—О—Б—В—А–∞—Ж–Є—П, –њ–Њ–Ї–∞–Ј—Л–≤–∞—О—Й–∞—П, –Ї–∞–Ї –Є–Ј–Љ–µ–љ–Є–ї–∞—Б—М –Ї–Њ–љ—Ж–Њ–≤–Ї–∞ —Б–µ–Ї—Ж–Є–Є –њ—А–Є –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є–Є (—Б–ї–µ–≤–∞ вАФ –±—Л–ї–Њ, —Б–њ—А–∞–≤–∞ вАФ —Б—В–∞–ї–Њ):
–Я–Њ—Б–Ї–Њ–ї—М–Ї—Г –Љ—Л —А–∞—Б—И–Є—А–Є–ї–Є —В–∞–±–ї–Є—Ж—Г —А–µ–ї–Њ–Ї–∞—Ж–Є–є (–Њ–љ–∞ —Г–≤–µ–ї–Є—З–Є–ї–∞—Б—М –≤ —А–∞–Ј–Љ–µ—А–µ –љ–∞ 4 –±–∞–є—В–∞), –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ –Њ—В—А–∞–Ј–Є—В—М —Н—В–Њ –≤ –і–≤—Г—Е –Љ–µ—Б—В–∞—Е:
- –Т —Н–ї–µ–Љ–µ–љ—В–µ —В–∞–±–ї–Є—Ж—Л –і–Є—А–µ–Ї—В–Њ—А–Є–є –і–∞–љ–љ—Л—Е —Г–Ї–∞–Ј–∞—В—М –љ–Њ–≤—Л–є —А–∞–Ј–Љ–µ—А —В–∞–±–ї–Є—Ж—Л —А–µ–ї–Њ–Ї–∞—Ж–Є–є:
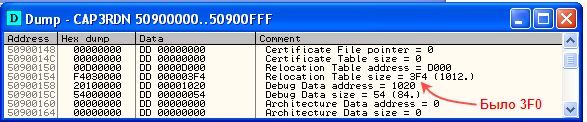
- –Т —В–∞–±–ї–Є—Ж–µ —Б–µ–Ї—Ж–Є–є —Г–≤–µ–ї–Є—З–Є—В—М –≤–Є—А—В—Г–∞–ї—М–љ—Л–є —А–∞–Ј–Љ–µ—А —Б–µ–Ї—Ж–Є–Є –Є —А–∞–Ј–Љ–µ—А –Є–љ–Є—Ж–Є–∞–ї–Є–Ј–Є—А–Њ–≤–∞–љ–љ–Њ–є —З–∞—Б—В–Є —Б–µ–Ї—Ж–Є–Є (–њ–Њ–і–≥—А—Г–ґ–∞–µ–Љ–Њ–є –Є–Ј —Д–∞–є–ї–∞). –Ю–і–љ–∞–Ї–Њ –Њ–Ї–∞–Ј–∞–ї–Њ—Б—М, —З—В–Њ –і–ї—П —Б–µ–Ї—Ж–Є–Є .reloc —Н—В–Є –≤–µ–ї–Є—З–Є–љ—Л –Є–Ј–љ–∞—З–∞–ї—М–љ–Њ —Б—В–Њ—П—В —Б –Ј–∞–њ–∞—Б–Њ–Љ, –Є –љ–∞—И–µ –Є–Ј–Љ–µ–љ–µ–љ–Є–µ —А–∞–Ј–Љ–µ—А–∞ —Б 0x3F0 –і–Њ 0x3F4 –љ–µ —В—А–µ–±—Г–µ—В –Ї–∞–Ї–Њ–є-–ї–Є–±–Њ –њ—А–∞–≤–Ї–Є –≤ —В–∞–±–ї–Є—Ж–µ —Б–µ–Ї—Ж–Є–є:

–Ґ–µ–њ–µ—А—М —Н–Ї—Б–њ–Њ—А—В–Є—А—Г–µ–Љ –Љ–Њ–і–Є—Д–Є—Ж–Є—А–Њ–≤–∞–љ–љ—Л–є –Њ–±—А–∞–Ј –Є–Ј OllyDbg –≤ —Д–∞–є–ї, –њ–µ—А–µ–Ј–∞–≥—А—Г–ґ–∞–µ–Љ DLL-—Д–∞–є–ї –њ–Њ–і –Њ—В–ї–∞–і–Ї–Њ–є –Є –≤–Є–і–Є–Љ —Б—В–Њ–ї—М –ґ–µ–ї–∞–љ–љ—Л–µ –њ–Њ–і—З—С—А–Ї–Є–≤–∞–љ–Є—П –њ–Њ–і –≤—И–Є—В—Л–Љ–Є –≤ –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є –∞–±—Б–Њ–ї—О—В–љ—Л–Љ–Є –∞–і—А–µ—Б–∞–Љ–Є IAT-—П—З–µ–µ–Ї, —Б–≤–Є–і–µ—В–µ–ї—М—Б—В–≤—Г—О—Й–Є–µ –Њ —В–Њ–Љ, —З—В–Њ —А–µ–ї–Њ–Ї–∞—Ж–Є–Є —А–∞–±–Њ—В–∞—О—В –Є –∞–±—Б–Њ–ї—О—В–љ—Л–µ –∞–і—А–µ—Б–∞ –±—Г–і—Г—В –њ–Њ–і–Ї–Њ—А—А–µ–Ї—В–Є—А–Њ–≤–∞–љ—Л –≤ —Б–ї—Г—З–∞–µ –Ј–∞–≥—А—Г–Ј–Ї–Є –њ–Њ –љ–µ—А–Њ–і–љ–Њ–є –±–∞–Ј–µ:
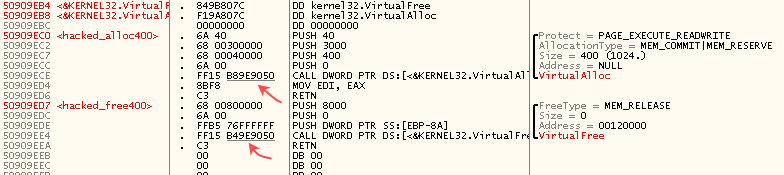
–ѓ –≤—Л—И–µ –њ–Є—Б–∞–ї(–∞):–Э–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ –Њ—Б—В–∞–ї–Њ—Б—М –µ—Й—С –і–≤–µ –≤–µ—Й–Є, –Њ –Ї–Њ—В–Њ—А—Л—Е –Љ—Л –Ј–∞–±—Л–ї–Є, –Ї–Њ—В–Њ—А—Л–µ, –њ–Њ–Ї–∞ –љ–µ —Б–і–µ–ї–∞–љ—Л, –Њ—Б—В–∞–≤–ї—П—О—В –љ–∞—И –њ—А–Њ–њ–∞—В—З–µ–љ–љ—Л–є –і—А–∞–є–≤–µ—А –љ–µ–њ–Њ–ї–љ–Њ—Ж–µ–љ–љ—Л–Љ —Г—А–Њ–і—Ж–µ–Љ.
–≠—В–Њ –±—Л–ї–∞ –њ–µ—А–≤–∞—П –Є –≥–ї–∞–≤–љ–∞—П –≤–µ—Й—М. –Т—В–Њ—А–∞—П –≤–µ—Й—М –љ–µ –љ–∞—Б—В–Њ–ї—М–Ї–Њ –Ї—А–Є—В–Є—З–љ–∞ –Є –±–µ–Ј –≤—Б—С —А–∞–±–Њ—В–∞–µ—В, –љ–Њ –ї—Г—З—И–µ –Ї–Њ–љ–µ—З–љ–Њ –љ–µ –Ј–∞–±—Л–≤–∞—В—М –Њ–± —Н—В–Њ–Љ.
–Ь—Л –≤–љ–µ–і—А–Є–ї–Є –Ї–Њ–µ-—З—В–Њ (–Ї—Г—Б–Њ—З–Ї–Є
hacked_alloc400,
hacked_free400, –љ–Њ–≤—Г—О IAT –Є –љ–Њ–≤—Л–є –і–µ—Б–Ї—А–Є–њ—В–Њ—А –Є–Љ–њ–Њ—А—В–∞) –≤ –Ї–Њ–љ–µ—Ж —Б–µ–Ї—Ж–Є–Є –Ї–Њ–і–∞, –∞ –Ј–љ–∞—З–Є—В, –љ–∞–Љ –љ—Г–ґ–љ–Њ –Є—Б–њ—А–∞–≤–Є—В—М –≤–Є—А—В—Г–∞–ї—М–љ—Л–є —А–∞–Ј–Љ–µ—А —Б–µ–Ї—Ж–Є–Є
.text –≤ —В–∞–±–ї–Є—Ж–µ —Б–µ–Ї—Ж–Є–є. –Э–Њ–≤–∞—П –≥—А–∞–љ–Є—Ж–∞ —Б–µ–Ї—Ж–Є–Є –Ї–Њ–і–∞ –ї–µ–ґ–Є—В –њ–Њ –∞–і—А–µ—Б—Г
0x50909EEB, —З—В–Њ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В RVA
0x9EEB, —З—В–Њ —Б —Г—З—С—В–Њ–Љ RVA –љ–∞—З–∞–ї–∞ —Б–µ–Ї—Ж–Є–Є
0x1000 –і–∞—С—В –љ–Њ–≤—Л–є –≤–Є—А—В—Г–∞–ї—М–љ—Л–є —А–∞–Ј–Љ–µ—А —Б–µ–Ї—Ж–Є–Є, —А–∞–≤–љ—Л–є
0x8EEB.
–Ш—Б–њ—А–∞–≤–ї—П–µ–Љ:
–Ъ—А–Њ–Љ–µ —В–Њ–≥–Њ, –Љ—Л –≤ –Њ–±—Й–µ–Љ –Є —Ж–µ–ї–Њ–Љ –≤–љ–µ—Б–ї–Є –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ –Є–Ј–Љ–µ–љ–µ–љ–Є–є –≤ PE-—Д–∞–є–ї, —З—В–Њ –љ–µ–Є–Ј–±–µ–ґ–љ–Њ –њ—А–Є–≤–µ–ї–Њ –Ї –њ–Њ—В–µ—А–µ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Є—П –Ї–Њ–љ—В—А–Њ–ї—М–љ–Њ–є —Б—Г–Љ–Љ—Л, —Е—А–∞–љ—П—Й–µ–є—Б—П –≤ PE-–Ј–∞–≥–Њ–ї–Њ–≤–Ї–µ, –Є —А–µ–∞–ї—М–љ–Њ–є –Ї–Њ–љ—В—А–Њ–ї—М–љ–Њ–є —Б—Г–Љ–Љ—Л –Њ–±—А–∞–Ј–∞. –Э—Г–ґ–љ–Њ –≤—Л—З–Є—Б–ї–Є—В—М –љ–Њ–≤—Г—О –Ї–Њ–љ—В—А–Њ–ї—М–љ—Г—О —Б—Г–Љ–Љ—Г –Є –Ј–∞–њ–Є—Б–∞—В—М –µ—С –≤ PE-–Ј–∞–≥–Њ–ї–Њ–≤–Њ–Ї. OllyDbg –љ–µ —Г–Љ–µ–µ—В –≤—Л—З–Є—Б–ї—П—В—М —З–µ–Ї—Б—Г–Љ (–њ–Њ –Ї—А–∞–є–љ–µ–є –Љ–µ—А–µ –±–µ–Ј —Б—В–Њ—А–Њ–љ–љ–Є—Е –њ–ї–∞–≥–Є–љ–Њ–≤) вАФ —Н—В–Њ –Љ–Њ–ґ–љ–Њ —Б–і–µ–ї–∞—В—М –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ–Љ –і—А—Г–≥–Є—Е —Г—В–Є–ї–Є—В. –ѓ –ґ–µ –њ–Њ–њ—А–Њ—Б—В—Г –љ–∞–њ–Є—Б–∞–ї —В–∞–Ї—Г—О —Г—В–Є–ї–Є—В—Г –Є–Ј –њ–∞—А—Л —Б—В—А–Њ–Ї: –≤—Б–µ–≥–Њ-—В–Њ –≤—Л–Ј–≤–∞—В—М
MapFileAndCheckSum.
–Ю–±–љ–Њ–≤–ї—П–µ–Љ —З–µ–Ї—Б—Г–Љ –Є —Б–Њ—Е—А–∞–љ—П–µ–Љ –Є–Ј–Љ–µ–љ–µ–љ–Є—П –≤ —Д–∞–є–ї —Г–ґ–µ –≤ –њ–Њ—Б–ї–µ–і–љ–Є–є —А–∞–Ј:
–Т—Б—С! –Ґ–µ–њ–µ—А—М –љ–∞ —А—Г–Ї–∞—Е –Є–Љ–µ–µ—В—Б—П –Є—Б–њ—А–∞–≤–ї–µ–љ–љ—Л–є –і—А–∞–є–≤–µ—А, –Ї–Њ—В–Њ—А—Л–є –і—А—Г–ґ–Є—В —Б DEP, –Ї–Њ—В–Њ—А—Л–є –љ–µ –Ј–∞–≤–Є—Б–Є—В –Њ—В –≤–µ—А—Б–Є–Є kernel32.dll, –Ї–Њ—В–Њ—А—Л–є –Є–Љ–њ–Њ—А—В–Є—А—Г–µ—В —Д—Г–љ–Ї—Ж–Є–Є –Ї–∞–Ї –њ–Њ–ї–Њ–ґ–µ–љ–Њ –Є –њ—А–Є —Н—В–Њ–Љ –Љ–Њ–ґ–µ—В –Ј–∞–≥—А—Г–ґ–∞—В—М—Б—П –њ–Њ –ї—О–±–Њ–Љ—Г –±–∞–Ј–Њ–≤–Њ–Љ—Г –∞–і—А–µ—Б—Г. –Я–µ—З–∞—В—М –Є–Ј –ї—О–±—Л—Е –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є —А–∞–±–Њ—В–∞–µ—В –Є –љ–Є—З–µ–≥–Њ –љ–µ –њ–∞–і–∞–µ—В!
–ѓ –њ—А–Є–љ—П–ї—Б—П –Є—Б–Ї–∞—В—М —В–µ–Љ—Л –љ–∞ —А–∞–Ј–љ—Л—Е —Д–Њ—А—Г–Љ–∞—Е, –≥–і–µ –њ–Њ–і–љ–Є–Љ–∞–ї–∞—Б—М –±—Л –њ—А–Њ–±–ї–µ–Љ–∞ –Ї—А–Є–≤–Њ–≥–Њ –Њ—А–Є–≥–Є–љ–∞–ї—М–љ–Њ–≥–Њ –і—А–∞–є–≤–µ—А–∞, –Є —Г–ґ–µ –њ—А–µ–і—Б—В–∞–≤–ї—П–ї —Б–µ–±–µ,
—З—В–Њ —П –њ—А–Є–і—Г –≤ —Н—В–Є —В–Њ–њ–Є–Ї–Є –Є –Ї–∞–Ї –Љ–µ—Б—Б–Є—П –≤—Л–ї–Њ–ґ—Г –≤—Л–ї–µ—З–µ–љ–љ—Л–є –і—А–∞–є–≤–µ—А –Є –њ—А–Є–љ–µ—Б—Г –ї—О–і—П–Љ –Є–Ј–±–∞–≤–ї–µ–љ–Є–µ –Њ—В —Н—В–Њ–є –њ—А–Њ–±–ї–µ–Љ—Л.
–Ю–і–љ–∞–Ї–Њ –ґ–µ –≤ —Н—В–Њ—В —А–∞–Ј –њ—А–∞–Ї—В–Є—З–µ—Б–Ї–Є —Б—А–∞–Ј—Г —П –љ–∞—В–Ї–љ—Г–ї—Б—П –љ–∞ –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—О –Њ —В–Њ–Љ, —З—В–Њ Canon –≤—Б—С-—В–∞–Ї–Є –≤—Л–њ—Г—Б—В–Є–ї –љ–Њ–≤—Г—О –≤–µ—А—Б–Є—О –і—А–∞–є–≤–µ—А–∞, –≥–і–µ –Є—Б–њ—А–∞–≤–Є–ї —Н—В—Г –њ—А–Њ–±–ї–µ–Љ—Г! –Ґ–Њ –µ—Б—В—М –љ–∞ —Б–∞–є—В–µ –Ъ—Н–љ–Њ–љ–∞ –љ–∞ —Б—В—А–∞–љ–Є—Ж–µ, –њ–Њ—Б–≤—П—Й—С–љ–љ–Њ–є –њ—А–Є–љ—В–µ—А—Г, –њ–Њ –њ—А–µ–ґ–љ–µ–Љ—Г –њ–Њ–і –≤–Є–і–Њ–Љ ¬Ђ—Б–∞–Љ—Л—Е –њ–Њ—Б–ї–µ–і–љ–Є—Е, —Б–∞–Љ—Л—Е —Б–≤–µ–ґ–Є—Е¬ї –і—А–∞–є–≤–µ—А–Њ–≤ —Б–Ї–∞—З–Є–≤–∞—О—В—Б—П —Д–∞–є–ї—Л –≤–µ—А—Б–Є–Є
1.0.0.7 —Б –њ—А–Њ–±–ї–µ–Љ–Њ–є DEP-–љ–µ—Б–Њ–≤–Љ–µ—Б—В–Є–Љ–Њ—Б—В–Є. –Э–Њ —Б—Г—Й–µ—Б—В–≤—Г–µ—В –Њ—В–і–µ–ї—М–љ—Л–є ¬Ђ–∞—А—Е–Є–≤¬ї, –≥–і–µ –ї–µ–ґ–Є—В –Є–Љ–µ–љ–љ–Њ —Д–∞–є–ї
CAP3RDN.DLL –≤–µ—А—Б–Є–Є
1.0.0.8, –≤ –Ї–Њ—В–Њ—А–Њ–Љ —Н—В–Њ—В –±–∞–≥ –Є—Б–њ—А–∞–≤–ї–µ–љ —Б–Є–ї–∞–Љ–Є —Б–∞–Љ–Њ–є —Д–Є—А–Љ—Л
Canon!
–Ш –µ—Б–ї–Є 5 –ї–µ—В –љ–∞–Ј–∞–і, –Ї–Њ–≥–і–∞ —П —Г—Б–Є–ї–µ–љ–љ–Њ –Є—Б–Ї–∞–ї –≥–Њ—В–Њ–≤–Њ–µ —А–µ—И–µ–љ–Є–µ –њ—А–Њ–±–ї–µ–Љ—Л, –љ–Є –Њ–і–љ–Њ–≥–Њ —Г–њ–Њ–Љ–Є–љ–∞–љ–Є—П –Є—Б–њ—А–∞–≤–ї–µ–љ–љ–Њ–є –≤–µ—А—Б–Є–Є –љ–µ –љ–∞—Е–Њ–і–Є–ї–Њ—Б—М, —В–Њ —Б–µ–є—З–∞—Б –Њ –љ–µ–є –Ј–љ–∞–µ—В, –Ї–∞–ґ–µ—В—Б—П, –њ–Њ–ї–Њ–≤–Є–љ–∞ –Є–љ—В–µ—А–љ–µ—В–∞. –Ш –≤—Б–µ —Б—В–∞—А–∞–љ–Є—П –њ–Њ –≤—Л–ї–µ—З–Є–≤–∞–љ–Є—О –≤–µ—А—Б–Є–Є
1.0.0.7 –±—Л–ї–Є –љ–∞–њ—А–∞—Б–љ—Л–Љ–Є, –≤–µ–і—М –µ—Б—В—М —Г–ґ–µ –≥–Њ—В–Њ–≤–∞—П —Е–Њ—А–Њ—И–∞—П –≤–µ—А—Б–Є—П
1.0.0.8.

–Э–∞–і–Њ —Б–Ї–∞–Ј–∞—В—М, —З—В–Њ —П –љ–µ —Б–Є–ї—М–љ–Њ —А–∞—Б—Б—В—А–Њ–Є–ї—Б—П: –љ–∞ –≤—Б–µ –Њ–њ–Є—Б–∞–љ–љ—Л–µ –Љ–∞–љ–Є–њ—Г–ї—П—Ж–Є–Є –њ–Њ –≤—Л–ї–µ—З–Є–≤–∞–љ–Є—О –і—А–∞–є–≤–µ—А–∞ —Г –Љ–µ–љ—П —Г—И–ї–Њ –љ–µ –±–Њ–ї—М—И–µ 40вАФ60 –Љ–Є–љ—Г—В. –Ч–∞—В–Њ –љ–∞ —В–Њ, —З—В–Њ–±—Л –љ–∞–њ–Є—Б–∞—В—М –≤–µ—Б—М —Н—В–Њ—В —В–µ–Ї—Б—В, –Њ–њ–Є—Б–∞—В—М –њ—А–Њ—Ж–µ—Б—Б –ї–µ—З–µ–љ–Є—П, —Б–і–µ–ї–∞—В—М –≤—Б–µ —Н—В–Є —Б–Ї—А–Є–љ—И–Њ—В—Л, –љ–∞—А–Є—Б–Њ–≤–∞—В—М –љ–∞ –љ–Є—Е —Б—В—А–µ–ї–Њ—З–Ї–Є, –њ–Њ–і–њ–Є—Б–Є –Є –≤—Л–і–µ–ї–µ–љ–Є—П —Ж–≤–µ—В–Њ–Љ —Г—И–ї–∞ –њ—А–Њ—Б—В–Њ
—Г–є–Љ–∞ –≤—А–µ–Љ–µ–љ–Є. –С–µ–Ј –њ—А–µ—Г–≤–µ–ї–Є—З–µ–љ–Є–є.
–Э—Г, –Ј–∞—В–Њ –њ–Њ –Љ–Њ—В–Є–≤–∞–Љ –њ—А–Њ–і–µ–ї–∞–љ–љ–Њ–є —А–∞–±–Њ—В—Л –њ–Њ–ї—Г—З–Є–ї–∞—Б—М –љ–µ–њ–ї–Њ—Е–∞—П —Б—В–∞—В—М—П –Њ —В–Њ–Љ, –Ї–∞–Ї –ї–µ—З–Є—В—М –њ–Њ–і–Њ–±–љ—Л–µ –њ—А–Њ–±–ї–µ–Љ—Л, –Ї–Њ—В–Њ—А–∞—П —А–∞—Б–Ї—А—Л–≤–∞–µ—В –љ–µ–Ї–Њ—В–Њ—А—Л–µ —Е–Є—В—А–Њ—Б—В–Є –Є —В–Њ–љ–Ї–Њ—Б—В–Є –њ—А–Њ—Ж–µ—Б—Б–∞ –Љ–Њ–і–Є—Д–Є–Ї–∞—Ж–Є–Є –Є—Б–њ–Њ–ї–љ—П–µ–Љ—Л—Е —Д–∞–є–ї–Њ–≤, –Є –Љ–Њ–ґ–µ—В –±—Л—В—М –Ї–Њ–Љ—Г-—В–Њ –Њ–Ї–∞–ґ–µ—В—Б—П –њ–Њ–ї–µ–Ј–љ–Њ–є –і–ї—П –ї–µ—З–µ–љ–Є—П –њ—Г—Б—В—М –љ–µ —Н—В–Њ–≥–Њ –і—А–∞–є–≤–µ—А–∞ –њ—А–Є–љ—В–µ—А–∞, –љ–Њ –Ї–∞–Ї–Њ–≥–Њ-—В–Њ –і—А—Г–≥–Њ–≥–Њ. –Ш–ї–Є —Е–Њ—В—П –±—Л –њ—А–Є–і–∞—Б—В —Г–≤–µ—А–µ–љ–љ–Њ—Б—В–Є, —З—В–Њ–±—Л –љ–µ –±–Њ—П—В—М—Б—П –Є–і—В–Є –љ–∞ –њ—А–Њ–ї–Њ–Љ –Є —А–µ—И–∞—В—М –њ—А–Њ–±–ї–µ–Љ—Г.
–Э—Г –Є –ґ–Є—В–µ–є—Б–Ї–∞—П –Љ—Г–і—А–Њ—Б—В—М: —Б–µ–Љ—М —А–∞–Ј –њ–Њ–≥—Г–≥–ї–Є вАФ –Њ–і–Є–љ —А–∞–Ј —Е–∞–Ї–љ–Є.–Х—Б–ї–Є –Ї–Њ–Љ—Г-—В–Њ –Є–љ—В–µ—А–µ—Б–љ–Њ –њ–Њ –Є—В–Њ–≥–∞–Љ –њ—А–Њ—З–Є—В–∞–љ–љ–Њ–≥–Њ –њ–Њ—Б–Љ–Њ—В—А–µ—В—М –Є –њ–Њ–Ї–Њ–≤—Л—А—П—В—М –і—А–∞–є–≤–µ—А –≤ –Њ—В–ї–∞–і—З–Є–Ї–µ –Є–ї–Є –і–Є–Ј–∞—Б—Б–µ–Љ–±–ї–µ—А–µ, –≤—Л–Ї–ї–∞–і—Л–≤–∞—О:












