abonent_2000@inbox.ru
Как победить "Out of memory"?
Правила форума
Темы, в которых будет сначала написано «что нужно сделать», а затем просьба «помогите», будут закрыты.
Читайте требования к создаваемым темам.
Темы, в которых будет сначала написано «что нужно сделать», а затем просьба «помогите», будут закрыты.
Читайте требования к создаваемым темам.
Сообщений: 11
• Страница 1 из 1
- Readers
- Начинающий

- Сообщения: 2
- Зарегистрирован: 03.05.2003 (Сб) 15:17
Как победить "Out of memory"?
![]() Readers » 03.05.2003 (Сб) 15:30
Readers » 03.05.2003 (Сб) 15:30
Программой создаются 8 массивов Single по 10 млн. элементов. В процессе выскакивает окно "Out of memory". Можно ли использовать например какую-нить виртуальную память ?А то видел программы, показывающие ее количество, а как ее использовать нигде не написано  .
.
abonent_2000@inbox.ru
abonent_2000@inbox.ru
- RayShade
- Scarmarked

-

- Сообщения: 5511
- Зарегистрирован: 02.12.2002 (Пн) 17:11
- Откуда: Russia, Saint-Petersburg
![]() RayShade » 03.05.2003 (Сб) 15:39
RayShade » 03.05.2003 (Сб) 15:39
Что я могу ответить. Для хранения такого количества данных потребуется около 320М памяти.
Не думаю, что тут чем то можно помочь. Совет один - переделай программу. Обычно такие огромные массивы данных в виде массивов это признак того что прога написана кривовато.
Не думаю, что тут чем то можно помочь. Совет один - переделай программу. Обычно такие огромные массивы данных в виде массивов это признак того что прога написана кривовато.
- areh
- Постоялец

- Сообщения: 530
- Зарегистрирован: 02.12.2002 (Пн) 12:28
- Откуда: РОССИЯ, Салехард
![]() areh » 03.05.2003 (Сб) 16:35
areh » 03.05.2003 (Сб) 16:35
Теоритически, для любого процесса (в 32 разрядно операционной системе) должно выделяться 4 ГБ памяти, т.е. 2^32 -1, а следовательно теоритичеси, всю эту хрень в память запихнуть можно, но к сожалению в ВБ теоритичесеи можно использовать только 2 ГБ памяти (т.к. у нас нет 32 разрядного беззнакого числа).
Итак совет:
1. Попробовать всё засунуть в память через прямое обращение к АПИ
(работа с кучами памяти, т.е. с HEAP)
Итак совет:
1. Попробовать всё засунуть в память через прямое обращение к АПИ
(работа с кучами памяти, т.е. с HEAP)
- RayShade
- Scarmarked
-
- Сообщения: 5511
- Зарегистрирован: 02.12.2002 (Пн) 17:11
- Откуда: Russia, Saint-Petersburg
![]() RayShade » 03.05.2003 (Сб) 16:38
RayShade » 03.05.2003 (Сб) 16:38
Дело не в памяти и выделени ее для процесса. И не надо пытаться насиловать систему кривым софтом. VB располагает достаточными средствами для решения практически любой задачи. Так что если это не удается сделать - то увы, это признак кривизны алгоритма.
- Readers
- Начинающий
- Сообщения: 2
- Зарегистрирован: 03.05.2003 (Сб) 15:17
![]() Readers » 03.05.2003 (Сб) 17:14
Readers » 03.05.2003 (Сб) 17:14
Осредняется объем продаж в семимерном пространстве. Каждая ось пространства разбита на 10 координат. Соответственно, каждое значение объема продаж имеет семь координат, возможных сочетаний этих координат получается 10^7 , итого 7*10^7(значений координат)+10^7(значений объемов продаж)=80 млн. значений. Где хранить эту прорву с возможностью быстрой статистической обработки? И причем тут алгоритм?


- kugeod
- Начинающий
- Сообщения: 1
- Зарегистрирован: 29.02.2016 (Пн) 16:07
- Откуда: Тверь
Re: Как победить "Out of memory"?
![]() kugeod » 29.02.2016 (Пн) 21:51
kugeod » 29.02.2016 (Пн) 21:51
Здравствуйте!
Меня полностью устраивает работа массивов в памяти, я их формирую сразу в память, обрабатываю и получаю результат. Без промежутков и выгрузок куда-либо. Но вот почему Vb не может дать мне даже объявить массив, размерностью которая меня интересует, мне не понятно. Объясните, если не тяжело. И есть ли способ работать с такими массивами, не уходя с ними в БД и разные там SQL'ли.
к примеру код:
выдаст ошибку "Out of memory".
Переменная типа byte, занимает в памяти 1 байт.
Даже если поверить что VB6 не выделяет больше 2Гб оперативки (где-то вычитал, сильно не бейте, если не так), то:
2гб это 2147483648 байт. Квадратный корень из 2147483648 округлим 46000. Выходит двумерный массив может быть в теории (хотя бы) 46000 на 46000. Но он же(код), скомпилированный, реально не превышает значения около 35000 на 35000. Почему?
А уж помечтав, я бы хотел всю свою оперативную память 8 гб использовать полностью под свою программу. Чтобы обрабатывать матрицы 80000 на 80000. Возможно ли это?
Если кому то вопрос покажется просто "воду помутить", то заверяю Вас, это не так. Заранее спасибо.
Меня полностью устраивает работа массивов в памяти, я их формирую сразу в память, обрабатываю и получаю результат. Без промежутков и выгрузок куда-либо. Но вот почему Vb не может дать мне даже объявить массив, размерностью которая меня интересует, мне не понятно. Объясните, если не тяжело. И есть ли способ работать с такими массивами, не уходя с ними в БД и разные там SQL'ли.
к примеру код:
- Код: Выделить всё
dim massive(40000,40000) as byte
выдаст ошибку "Out of memory".
Переменная типа byte, занимает в памяти 1 байт.
Даже если поверить что VB6 не выделяет больше 2Гб оперативки (где-то вычитал, сильно не бейте, если не так), то:
2гб это 2147483648 байт. Квадратный корень из 2147483648 округлим 46000. Выходит двумерный массив может быть в теории (хотя бы) 46000 на 46000. Но он же(код), скомпилированный, реально не превышает значения около 35000 на 35000. Почему?
А уж помечтав, я бы хотел всю свою оперативную память 8 гб использовать полностью под свою программу. Чтобы обрабатывать матрицы 80000 на 80000. Возможно ли это?
Если кому то вопрос покажется просто "воду помутить", то заверяю Вас, это не так. Заранее спасибо.
- Хакер
- Телепат
-

- Сообщения: 16497
- Зарегистрирован: 13.11.2005 (Вс) 2:43
- Откуда: Казахстан, Петропавловск
Re: Как победить "Out of memory"?
![]() Хакер » 01.03.2016 (Вт) 11:38
Хакер » 01.03.2016 (Вт) 11:38
kugeod писал(а):(где-то вычитал, сильно не бейте, если не так)
Нужно не «где-то вычитывать», а понимать.
Так вот, провожу ликбез.
В 32-битных Windows каждый запущенный EXE порождает свой собственный процесс. При этом каждый процесс получает собственное изолированное от других процессов и независимое от них пространство адресов памяти. Это пространство называется адресным пространством (АП).
Если какой-то процесс начнёт сканировать память начиная с нулевого адреса и до самого предела, он не найдёт там данных, принадлежащих другим процессам (из этого правила есть исключения, но сейчас они не важны). Тотальная изоляция. Примерно как в случае с файлами: если есть два файла на диске, то они хранят разные данные, которые не пересекаются между собой. Или как в случае с компьютерной игрой: если два человека будут играть в одну и ту же компьютерную игру, не в мультиплеер (по сети), а просто так, то даже если они будут ходить по одной и той же карте, друг друга они не встретят, потому что каждый существует в собственном (изолированном от другого) виртуальном мире. Так что тотальная изоляция.
Сама по себе технология, позволяющая сделать так, что каждый процесс (программа) видит своё собственное адресное пространство, называется виртуальная память, и это во многом аппаратная технология (предоставляемая архитектурой процессора Intel IA-32), которой операционная система умело пользуется.
Помимо возможности сделать так, чтобы каждый процесс имел своё собственное АП, архитектура позволяет сделать ещё три важные вещи:
- Страничная организация
- Подкачка
- Защита
Сейчас до всего дойдём.
Каждый процесс получает своё собственное адресное пространство и может использовать 32-битные адреса для адресации конкретных ячеек этого адресного пространства. Что даёт 2^32 = 4GB — размер адресного пространства каждого процесса с применением 32-битных адресов. Вообще-то, если быть честным, архитектура позволяет использовать 48-битные адреса, состоящие из двух частей: 16-битного селектора сегмента и 32-битного ближнего (near) адреса. Такой 48-битный адрес называется называется дальним (far). Но большинство операционных систем не пользуется этой возможностью, 16-битные селекторы загружаются в сегментные регистры единожды и дальше их никто не трогает, а используется только ближняя адресация, то есть 32-битная адресация.
Так вот, каждый процесс (в 32-битной Windows, работающей на 32-битном процессоре или на 64-битном процессоре, работающем в 32-битном режиме) может видеть адресное пространство размером 4 Гб и использовать 32-битные адреса.
Но не нужно думать, что раз у процесса есть АП размером 4 Гб, то сходу можно пользоваться любым местом в этом АП, писать и читать по любому адресу. Виртуальное АП — это абстракция, фикция и красивая иллюзия, создаваемая для того, чтобы сделать программирование более лёгким, удобным, а систему — более надёжной.
Данные, которые программа увидит в своей памяти, нужно где-то хранить. И этим «где-то» в первую очередь выступает физическая память.
Теперь поговорим о страничной организации и подкачке.
Вся физическая память (то есть память, в том её объёме, которая обеспечивается вставленными в материнскую плату планками памяти) условно делится на страницы — блоки размером 4 кб. Виртуальное АП каждого процесса тоже условно дробится на блоки размером 4 кб. Архитектура процессора позволяет позволяет операционной системе построить некую, упрощённо говоря, карту соответствия. Эта карта соответствия определяет, какая страница виртуального АП какого-то процесса какой странице физической памяти соответствует.
Так что, если бы всё было так просто, то даже несмотря на тот факт, что каждый процесс видит собственное АП размером 4 Гб, общее количество страниц, занятых какими-то данными, для всех процессов в сумме был бы ограничено размером физической памяти. А физической памяти в компьютере может быть установлено, например, 256 Мб. И это значило бы, что ограничение по использованию памяти для всех процессов вместе взятых — 256 Мб. Но всё не так просто.
На самом деле в этой карте соответствия для каждой страницы виртуального АП есть флаг, говорящий, а соответствует ли вообще данная страница виртуального АП какой-то странице физической памяти. И она может не соответствовать вообще никакой.
В норме, карта соответствия, о которой я говорю, строится (создаётся) силами операционной системой, но пользуется ей процессор на аппаратном уровне. Это значит, что когда код какой-то программы обращается к какой-то странице виртуального АП, то процессор сам смотрит в карту соответствия и преобразует виртуальный адрес в физический адрес и обращение идёт прямо к странице физической памяти. Операционная система при каждом обращении к памяти процесса не задействуется. Никакой код операционной системы при каждом обращении не выполняется. За преобразование адресов отвечают электронные схемы самого процессора. То есть преобразование чисто аппаратное, не программное. За счёт этого обеспечивается быстрота работы. Но это так до тех пор, пока в карте соответствия стоит флаг, что, мол, этой странице виртуального АП соответствует такая-то страница физ. памяти.
Если же флаг не установлен, и данной странице вирт. АП (к которой только что произошло обращение) не соответствует вообще никакой страницы физпамяти, то процессор дёргает операционную систему. Он вызывает обработчик, предоставленный операционной системой, чтобы она (ОС), как-то разрулила ситуацию.
Разруливание ситуации заключается в следующем:
ОС пользуется идеей о том, что в физической памяти хранится только часть данных. Остальная часть хранится на жестком диске. И что если у какого-то процесса в виртуальном АП есть страница, данные которой не хранятся в физпамяти, то значит эти данные хранятся на диске. Так что когда процессор натыкается на такую страницы и вызывает обработчик со стороны ОС, то ОС ищет в физпамяти страницу, доступ к которой происходил наиболее редко. Эта самая редкоиспользуемая страницы выкидывается из физической памяти (и сохраняется перед этим на диск, если она была изменена с тех пор, как попала в физпамять с диска), а на её место в физпамять загружается та страница с диска, к которой только что произошло обращение. Той странице, которая была загружена, флаг присутствия устанавливается. А у той, которая была выкинута, флаг сбрасывается.
Этот механизм, суть которого в том, что в физической памяти хранится только часть страниц (те страницы, с которыми идёт наиболее активная работа), а оставшаяся часть хранится на жестком диске, и что постоянно одни страницы выгружаются из физ.памяти на диск, а взамен подгружаются другие — называется подкачка.
Раньше я написал, что хоть у каждого процесса и есть 4 Гбайтное АП, но всё равно суммарное потребление памяти всеми процессам ограничено размерами физической памяти. Теперь это не так — поскольку часть данных хранится на диске, а не в физ. памяти, то суммарное потребление памяти всеми процессами уже не ограничено размерами физ. памяти (но размер физ. памяти влияет на производительность, потому что чем меньше физ. память, тем чаще приходится туда-сюда гонять страницы).
Теперь, если посмотреть на отдельный процесс и посмотреть на его адресное пространство, любая страница в нём может быть:
- Пустой (не размещённой) — попытка доступа к ней оборачивается исключением (сбоем).
- Занятой, и находиться в данный момент времени в физической памяти.
- Занятой, и находиться в данный момент времени на диске.
Теперь самое интересное.
Вообще-то, из этого всего нужно сделать вывод, что физическая память используется только как временный буфер для текущей работы со страницами. Данные, соответствующие странице виртуального АП, переносятся в физическую память только тогда, когда пойдёт обращение к данной странице (чтение или запись). Не будет обращений — страница будет выкинута из физической памяти обратно на диск, а на её место будет загружена более нужная страница.
Так что любая страница на самом деле как основное хранилище использует жесткий диск. Теперь важно понять, где именно на диске хранятся страницы. Существует два возможных хранилища. Это может быть:
- Произвольный файл на диске.
- Файл подкачки
Операционная система позволяет любому процессу спроецировать любой файл с любого диска в своё виртуальное адресное пространство. При этом программа (процесс) увидит в своём АП данные, которые размещаются в файле. Если программа будет прямо в памяти модифицировать эти данные, модификации отразятся и в файле. Несколько разных процессов могут один и тот же файл спроецировать в своё АП. При этом, если один процесс модифицирует спроецированные данные, то другой процесс увидит эти изменения сразу же (и в файле эти изменения тоже отразятся).
О таких страницах говорят, что они image-backed.
Операционная система, кроме того, позволяет любому процессу просто выделить для своих нужд сколько-то пустых страниц. Такие страницы не являются проекцией какого-то конкретного файла на диске на первый взгляд, но на самом деле в качестве хранилища для данных таких страниц выступает файл подкачки. Такие страницы называются swap-backed (потому что одно из названий файла подкачки — swap-file, и сам процесс, при котором из физпамяти страница сбрасывается на диск, а на её место подгружается с диска другая страница, называется swapping).
И теперь возникает вопрос? Так чем же ограничено потребление памяти отдельно взятым процессом?
Возвращаюсь к началу.
У каждого процесса есть своё АП размером 4 Гб. Можно считать, что изначально это АП пустое, попытка обращения к какой-либо странице приведёт к сбою. Отсюда следует, что теоретически невозможно в одном АП одновременно иметь более, чем 4 Гб данных.
Процесс может заполнять своё АП либо просто выделяя пустые страницы для себя (swap-backed), либо проецируя какие-то файлы в своё АП (image-backed/file-backed).
Общее количество image-backed страниц для всех процессов вместе взятых по идее не ограничено ничем. Для отдельно взятого процесса ограничено размерами АП.
Общее количество swap-backed страниц для всех процессов вместе взятых ограничено размерами файла подкачки (или всех файлов подкачки вместе взятых, потому что их может быть более одного). Для одного отдельно взятого процесса оно ограничено размерами АП.
На самом деле, конечно, для поддержания информации о процессах, о том, какие страницы их АП чему соответствуют, тоже расходуется память, так что нужно делать некую поправку, когда я говорю «не ограничено ничем».
Я приведу такую аналогию для лучшего понимания того, как коррелирует размер АП и размер файла подкачки:
- Нужно представить себе, что есть 10 гостиниц по 100 мест. У этих гостиниц один общий хозяин, у которого есть склад, на котором хранится 600 комплектов постельного белья.
Отдельно взятая гостиница — это процесс.
Диапазон гостиничных номеров от 1 до 100 — это адресное пространство процесса.
Владелец всех гостиниц — это операционная система.
Склад, где хранятся комплекты постельного белья — это файл подкачки.
Вы приезжаете в гостиницу и спрашиваете «сколько вообще у вас номеров?», и вам отвечают «100». Это теоретическое ограниение, определяющее, сколько вообще человек можно заселить в одну гостиницу. Больше этого — никак не получится.
Каждый отдельно взятый номер гостиницы может быть либо свободен, либо заселён. Подобно этому, каждая страница адресного пространства может быть либо не занята (свободна), либо размещена.
Вы можете приехать в гостиницу и спросить «сколько у вас незаселённых номеров?», и вам ответят «70». Но при попытке заселиться вам откажут, потому что хоть в гостинице и есть 70 свободных номеров, на складе не осталось ни одного комплекта постельного белья. И если вы поедете в другую гостиницу, где тоже есть свободные номера, вам тоже откажут в заселении — хозяин один и тот же, и на складе по прежнему нет ни одного комплекта постельного белья. Именно так и работает общесистемное ограничение на количество выделенных страниц — оно ограничено размерами файла подкачки. Все процессы в сумме не могут иметь количество выделенных страниц больше, чем позволяет размер файла подкачки, несмотря на то, что у каждого процесса весьма большое собственное адресное пространство. Подобно тому, как общее количество заселённых номеров для всех 10 гостиниц не может быть больше, чем 600 (чем количество спальных комплектов на общем складе).
С другой стороны, если приехать в такую гостиницу со своим своими собственными комплектами постельного белья, то вас заселят (при условии, что есть свободные номера), и оставшееся количество комплектов на общем складе на вас никак не повлияет. Заселению в номера с собственным постельным бельём (вместо использования белья с общего склада) соответствует проецированию в АП процесса страниц из какого-то произвольного файла на диске (вместо выделения новых пустых страниц, на что расходуется файл подкачки).
____________
Теперь о защите. Помимо того, что каждый процесс имеет изолированное от других процессов АП, и помимо того, что АП дробится на страницы (размером 4 кб), которые могут быть либо пустыми, либо быть проекцией какого-то файла, либо храниться в файле подкачки, каждая страница имеет атрибуты защиты.
Атрибуты защиты устанавливают, может ли сам процесс записывать что-то в эту страницу, может ли он читать что-то из этой странице и может ли выполняться код, хранящийся в этой странице.
Сокращённо атрибуты доступа страницы описываются буквами RWE (Read/Write/Execute). Атрибуты защиты устанавливаются по-странично — вся страница целиком имеет одни и те же атрибуты. Нельзя половине странице дать одни атрибуты, а второй половине — другие.
Атрибуты позволяют получать read-only страницы, защищённые от записи, или страницы, защищённые от чтения, или страницы, в которых не може размещать код.
Напоминаю, что Intel IA-32 и следовательно 32-битные Windows используют фон-неймановскую архитектуру (в противовес Гарвардской). Архитектура фон Неймана предполагает, что и данные, и код хранятся в одном общем адресном пространстве. Грубо говоря — вперемешку. По соседству с какими-то данными может храниться какой-то код.
Если код процесса попытается прочитать что-то из неразмещённой страницы — происходит исключение (сбой).
Если код попытается прочитать что-то из страницы, у которой нет R-атрибута — происходит исключение.
Если код попытается записать что-то в страницу, у которой нет W-атрибута — происходит исключение.
Если код попытается передать управление другому коду, которой хранится в странице, не имеющей E-атрибута — происходит исключение.
Шаг влево, шаг вправо — расстрел.
И здесь нужно сделать важное замечание. Помимо всего этого, архитектура процессора предлагает различные режимы работы процесса, отличающиеся по уровням привилегий. Уровни привилегий устанавливают, что именно может делать выполняющийся в данный момент код. Вообще-то архитектура IA-32 предлагает целых 4 уровня привилегий, с которыми может работать процессор (от наименее привилегированного до наиболее), но Windows использует только два из них — наименее привилегированный (Ring-3) и наиболее привилегированный (Ring-0).
Режим Ring-3 (он же User-mode — пользовательский режим) используется для выполнения прикладных программ. Режим Ring-0 (kernel mode — режим ядра) используется для выполнения кода ядра ОС и кода драйверов).
Важный факт на счёт режимов работы — код, работающий в user mode не может по своему желанию взять и поменять режим на kernel mode. Единственный способ поменять текущий режим — это через так называемые call gate. Операционная система предоставляет прикладным программам свои системные вызовы. Код прикладных программ делает эти системные вызовы и в момент вызова происходит переключение режима на kernel mode и выполняется код ядра (в режиме Ring-0). При возврате управления вызыающему коду происходит обратный переход на режим Ring-3.
Так что код прикладных приложений никогда не выполняется в Ring-0 и не имеет возможности осуществлять привелигированные операции.
И вот здесь очень важный факт.
Windows устроена так, что АП каждого процесса делится на две части. По умолчанию 4-х гигабайтное АП делится на две половины по 2 Гб. Старшая половина хранит код и данные, доступные только в kernel mode. В режиме user-mode (Ring-3) попытка процесса обратиться к любой странице из «старшей половины» (то есть начиная с адресов 0x80000000 и до 0xFFFFFFFF) приводит к исключению (сбою).
Лишь нижняя половина АП, а именно диапазон адресов от 0x00000000 до 0x7FFFFFFF, доступна коду прикладных приложений, который выполняется в режиме user-mode (ring-3). Лишь в этом диапазоне (размером 2 Гб) он может выделять себе страницы, лишь к ним он может делать обращения, при которых, разумеется, всё равно проверяются атрибуты защиты.
Интересный факт насчёт этого разделения состоит в том, что верхняя половина АП каждого процесса, невидимая прикладному коду, у всех процессов — одинаковая. То есть если бы разным процессам довелось переключиться в режим ядра (повысить уровень привилегий до ring-0), то заглянув в диапазон 0x80000000—0xFFFFFFFF все разные процессу увидели бы одни те же данные. Там был бы код ядра и данные ядерных структур.
Нижняя (младшая) половина, то есть нижние 2 Гб у каждого процесса — собственная, изолированная от других. А старшая половина, старшие 2 Гб у всех процессов — общие, но прикладной код, работающий в режиме user-mode не может иметь к этой половине никакого доступа абсолютно.
(В нашей гостиничной аналогии этому соответствует тот факт, что верхние этажи отданы персоналу — в них проживает персонал самой гостиницы и обычных клиентов туда никогда не селят)
Так что три важных тезиса:
Не всё адресное пространство, а только его часть (обычно половина — 2 Гб) доступа коду прикладных приложений.
Это касается абсолютно всех приложений для 32-битной Windows, на чём бы они ни были написаны, а не только VB-шных программ.
Существует возможность получить другую пропорцию деления.
Последнее касается NT-основанных систем. В файле boot.ini существует специальный ключик /3GB. Если без него по умолчанию под ядро отдаётся 2 Гб, а прикладным процессам доступны только нижние 2 Гб, то при включении этого ключика ядро будет стискиваться и под него будет отдавать только верхний 1 Гб адресного пространства. А прикладным программам будет доступны уже не оставшиеся 2 Гб, а оставшиеся 3 Гб!
То есть если обычно диапазон адресов, с которыми имеет дело прикладной код, составляет 0x00000000—0x7FFFFFFF, то теперь он расширяется до 0x00000000—0xBFFFFFFF). Часть адресов (0x80000000—0xBF000000) в знаковом представлении чисел получается отрицательной. Не все приложения написаны так, что могут корректно переваривать отрицательные адреса. Поэтоу даже при включении режима /3GB Windows будет выделять память только их первых 2 Гб адресного пространства, если только само приложение не имеет флаг, говорящий, что оно совместимо с режимом 3GB. Если флаг есть, тогда прикладному приложению становятся доступны все 3 Гб адресного пространства.
Печальный факт относительно режима /3GB состоит в том, что есть вероятность, что код ядра, код всех драйверов и все ядерные данные просто не смогут ужаться до размера 1 Гб. В этом случае система просто не загузится корректно. Это особенно актуально для новых драйверов, которые пишут кретины, не жалеющие памяти.
_______________
Третий момент заключается в том, что в рамках борьбы с нулевыми указателями, первые (младшие) 64 кб адресного пространства никогда ни подо что не используются. Страницы в этом регионе не выделяются, спроецировать туда какой-то файл тоже нельзя. Обращения к этому региону всегда вызывают исключение.
(То есть, продолжая аналогию, в комнату под номером 1 никогда никого не селят)
________________
Так что же у нас остаётся?
Процесс имеет АП размером 4 Гб.
При этом прикладному доступна только нижняя часть размером 2 Гб (если только не включен режим /3GB и у приложения нет спец. флага).
Из этого 2 Гб заведомо недоступным является младший фрагмент размером 64 Кб.
Оставшаяся часть АП является теоретически доступной.
Что же ограничивает использование дальнейшее использование потенциально-доступной части АП размером в 2 Гб минус 64 кб?
Что не даёт нам выделить квадратный массив с 46000×46000 ячеек (квадратный корень из 2147483648)?
Во-первых, 2 Гб минус 64 кб — это только размер самого пространства адресов. Количество страниц новых (пустых), которые могут быть выделены
всем процессам вместе взятым ограничено размером файла подкачки. Если у нас файл подкачки имеет размер 1 Гб, то даже один единственный процесс никогда не сможет выделить память под массив размером 1.5 Гб. Если у нас файл подкачки будет иметь размер 6 Гб, всё равно есть шанс, что мы не сможем выделить массив размером даже 500 Мб, если остальные 40 процессов в сумме потребляют 5,8 Гб файла подкачки.
Размер физической памяти здесь практически не играет никакой роли. Он влияет только на производительность.
Так что одна из причин, почему не получается выделить память под массив желаемого размера — нет свободных страниц в файле подкачки. Нужно либо уменьшить размер файла подкачки, либо завершить другие процессы.
_____________
Другая, гораздо более серьёзная, неразрешимая и драматичная причина — это фрагментация АП.
Пусть даже у нас файл подкачки имеет колоссальный неисчерпаемый размер. Пусть у нас физ.память огромного размера.
Всё равно АП процесса имеет размер 4 Гб.
Всё равно только младшие 2 Гб (или 3 Гб) доступны прикладному процессу.
Представим себе часть АП размером 2 Гб. Пусть она изначально ничем не занята.
И вот какой-то код выделил себе всего-лишь одну единственную страницу размером 4 кб из середины этого АП. Эта одна единственная крохотная страница разбивает (фрагментирует) большое двухгигабайтное АП на две части.
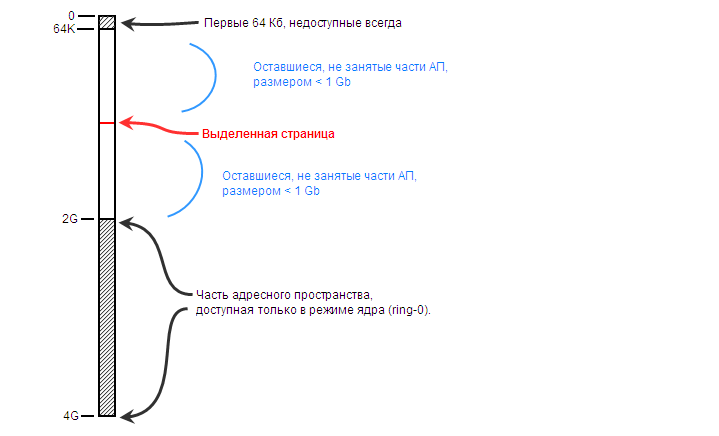
Теперь уже невозможно выделить ни 2 гигабайта, ни 1.5 гигабайта. Несмотря на то, что файл подкачки позволяет, и физ. память позволяет. АП фрагментировано, разбито пополам, и можно теперь выделить только два кусочка по 0.9 Гб (грубо говоря).
(Гостиничная аналогия: вы приехали большой гурьбой и намерены заселить все подряд номера с 21-го по 50-ый — всего 30 номеров. В гостинице сейчас есть 80 свободных номеров, на складе осталось 150 комплектов постельного белья, но вам откажут, потому что номер 37 уже заселён, а вы затребовали непрерывный диапазон номеров. Более того, может так оказаться, что в 100-местной гостинице есть 5 этажей по 20 комнат на каждом этаже. Вы приехали большим коллективом (как раз 20 человек) и требуете, чтобы вас всех заселил на один этаж — вам не принципиально на какой, главное, чтобы все жили на одном и том же. Но вам окажут: оказывается, что на каждом этаже заселён только один номер. В 100-местной гостинице живёт 5 человек (по одному человеку на этаж). 95% номеров простаивает. Но вам откажут, потому что нет ни одного полностью свободного этажа, а вы требуете именно этого. Хотя и постельного белья на складе навалом, и 95 номеров не заселены. Но диапазон фрагментирован теми случайными заселенцами, что есть на каждом этаже, и это не даёт вам воспользоваться почти пустой гостиницей).
Это надуманный пример.
В реальной жизни сразу же после запуска и загрузки процесса, фрагментированность его АП даёт куда худшую картину. То есть она гораздо более фрагментировано, нежели чем на два фрагмента одной единственной страничкой, как на картинке выше.
Чем фрагментируется АП процесса?
Во-первых, ещё при создании и загрузки процесса, в него проецируются все использующиеся исполняемые файлы. То есть прямо в АП процесса проецируется главный EXE-файл, все использумые им системные библиотеки (DLL), и не только системные, все компоненты. Адреса, по которым проецируются исполняемые файлы, зависят от вшитых в сами файла значений базовых адресов.
Иными словами, каждый исполняемый файл сам решает, куда он будет спроецирован. По крайней мере системные библиотеки оптимизированы в этом плане так, что при проецировании оказываются близко друг к другу в области ближе к концу двухгигабайтового куска АП. Это даёт меньшую фрагментацию. Сам по себе EXE обычно проецируется по адресу 0x00400000. Для собственного EXE и собственных библиотек эти адреса можно переопределить. Кроме того, если на момент загрузки библиотеки по нужному адресу уже что-то хранится, и при этом библиотека не решена секции релоков, то библиотека может быть загружена (спроецирована) по другому местоположению. Более того, на последних ОС (Vista, Win7 и так далее) есть технология ASLR (address-space layout randomization — рандомизация адресного пространства), при которой исполняемые файлы будут проецироваться в более-менее случайные места АП.
Во-вторых, в АП проецируется ряд системных данных (например NLS-блоки), но это происход по младшим адресами.
В-третьих, АП фрагментируется стеками потоков. Для каждого потока резервируется место под его стек. Размер резервируемой части можно переопределить.
В-четвёртых, АП фрагментируется TIB-блоками под каждый поток. Впрочем, и их система старается размещать ближе к концу двухгигабайтного куска, доступного прикладным приложениям.
Ну и самое главное: по ходу своей работы приложение активно выделяет для себя память (используя разные механизмы), может быть, что-то проецирует в своё АП, и тем самым вносит наибольшую фрагментацию в «раскрой» адресного пространство.
Отсюда и следует, что хотя изначально размер доступного АП любого процесса составлять чуть меньше 2 Гб (или чуть меньше 3 Гб в специальном режиме работы ОС), фрагментация ограничивает наибольший размер непрерывного блока, который может быть зарезервирован/выделен или спроецирован. Кроме фрагментации, которая затрагивает именно большие непрерывные куски, ещё и размер файла подкачки влияет на общесистемное максимальное суммарное количество страниц, которое может быть выделено всем работающим процессам вместе взятым.
Мораль:
- Если не удаётся выделить блок памяти, потому что его размер больше, чем доступная часть АП (то есть вы хотите заселить 500 человек в одну 100-местную гостиницу), нужно либо заставлять пользователей включать режим /3GB (в котором система с немалой вероятностью вообще не сможет загрузиться), либо пересаживать их на 64-битные системы. Но 32-битные исполняемые файлы даже на 64-битных системах живут по правилам 32-битных систем. А производить на свет 64-битные исполняемые файлы VB (пока что) увы, не умеет. На самом деле, это всё вредные советы — нужно просто пересматривать архитектуру своей программы и свои подходы. И совсем по-другому реализовывать работу с данными.
Если нужно работать с огромными объёмом данных, всегда можно держать их в огромном файле на диске и проецировать кусочки этого огромного файла в АП процесса и работать с этими кусочками. - Если не удаётся выделить блок памяти, потому что упираешься в ограничение на число swap-backed страниц, которые могут быть выделены всем процессам вместе взятым в сумме (то есть приехали в гостиницу, где в принципе есть свободные номера, но оказалось, что на складе больше нет комплектов постельного белья), то нужно либо увеличить размер файла подкачки (просить владельца сети гостиниц закупить ещё комплекты, хранимые на складе), либо выделять эти страницы не из файла подкачки — для этого придётся создать свой файл на диске (достаточного размера) и для выделения памяти проецировать его куски в АП (приезжать со своим набором комплектов постельного белья). Будет такой самодельный файл подкачки, но преимуществ у такого подхода мало. Разве что таким образом можно получить шанс запускать прожорливое до памяти приложение где-то там, где пользователь не имеет прав увеличить размер файла подкачки, а тот, кто имеет такое право, не желает этого делать.
- Если не удаётся выделить блок памяти, потому что мешает фрагментированность АП (хотите занять весь этаж гостиницы целиком, но нет ни одного полностью свободного этажа), то нужно пересматривать архитектуру приложения (отказываться от желания заселить весь свой коллектив на одном и том же этаже) и организацию данных — фрагментировать свои данные, чтобы умещались в фрагментированном АП. Вместо огромных непрерывных массивов использовать связные списки, деревья, блочные списки. Например, вместо твоего огромного двухмерного массива — использовать массив массивов.
Некоторые факты остались за кадром:
- Я написал, что любая страница адресного пространства в любой момент времени либо лежит на диске (в файле-подкачке либо файле-образе, использовавшемся при проецировании), либо в физической памяти, и когда идёт обращение к странице, которая в данный момент не находится в физической памяти, она туда загружается, а та страница, которая там была, выгружается. В основе своей этой так, но существует страницы, когда всегда присутствуют в физической памяти и никогда не выгружаются на диск (чтобы освободить место в физ. памяти подо что-то другое). Такие страницы называются неподкачиваемыми (non-paged), и используются они ядром ОС для особых нужд. Например сам код, который осуществляет подкачку (подгрузку/выгрузку страниц из физической памяти на диск и обратно), хранится именно в непокачиваемых невыгружаемых страницах. Если бы страница памяти, в которой хранится этот код, был бы выгружен на диск, то некому было бы загрузить её (или любую другую страницу) обратно. Такие страницы — дефицитный ресурс, но так или иначе, под разные нужды ядро ОС их использует. Поэтому объём физической памяти влияет не только на производительность, но и на количество невыгружаемых страниц, которые может выделить для себя ядро ОС.
- Неправильно думать, что все страницы физпамяти используются под завязку. Если бы это было так, прежде чем загрузить какую-то страницу с диска в физпамять, пришлось бы сначала какую-то выгрузить. А выгрузка (как и загрузка) — это дисковые операции, а они медленные, и это сильно ухудшало бы производительность программ и ОС при работе с памятью. Вместо этого ОС всегда держит какое-то количество свободных страниц про запас. Когда требуется подгрузить какую-то страницу с диска в физ. память, то сразу же выполняется эта подгрузка, и для этого используется свободная страница физ. памяти. Поток, выполнивший обращение к странице, продолжает свою работу, но при этом в фоновом системном потоке будет произведена выгрузка какой-нибудь малоиспользуемой страницы физ. памяти, чтобы поддерживать количество «запасных» свободных страниц физической памяти на прежнем уровне.
- Все мои аналогии с гостиницей и заселением в номера были написаны исходя из предположений, что:
- Все номера — одноместные.
- В гостиницу можно заселиться сразу, не бронируя (не резервируя) номер заранее.
Точно так же обстоят дела в Windows.
Нельзя просто так взять и выделить себе одну или парочку страниц памяти. Сперва нужно зарезервирововать себе регион памяти. Подобно тому, как нельзя разезервировать (но можно занять) отдельное койко-место в гостинице, нельзя в системе зарезервировать отдельную страницу. Разервирование регионов памяти осуществляется блоками по 64 Кб (по 16 страниц в каждом блоке), подобно тому, как в гостиницу резервируются целые номера (по 3 спальных места, а не отдельные койки). После того, как был зарезервирован регион памяти (размер которого кратен 64 кб), в этом регионе можно выделять себе отдельные страницы. Можно выделить все страницы из зарезервированного региона, можно выделить только 1, можно до поры до времени вообще ничего не выделять, а просто держать бронь «на всякий случай».
Резервирование блоков памяти отличается от выделения памяти точно так же, как бронирование номеров отличается от заселения в них людей.
Ограничение на суммарное количество выделенных swap-backed страниц сказывается именно при выделении страниц. При резервировании блоков не может быть никакого «не хватает памяти» по причине исчерпания места в файле подкачки — ошибка может быть только по причине того, что желаемое место уже зарезервировал кто-то другой. Резервирование — это чистая бюрократия, как и бронирование в гостинице, цель этой процедуры состоит только в том, чтобы нудные страницы/номера не оказались хаотично занятыми к моменту, когда они понадобятся (когда потребуется выделить страницы / заселить людей). На резервирование регионов памяти не тратится ни файл подкачки ни физическая память, подобно тому, как на бронируемые в гостинице номера не тратятся комплекты постельного белья (они тратятся в момент заселения конкретных людей).
Файл подкачки тратится лишь тогда, когда из зарезервированного региона выделения новая пустая страница.
Но в зарезервирвоанный регион можно спроецировать содержимое какого-то произвольного файла, тогда файл подкачки не расходуется (это соответствует заселению в заранее забронированный номер с собственными комплектами постельного белья — тогда комплекты, хранящиеся на складе не расходуются). - В норме при проецировании файл в память, если происходит запись в участок памяти, куда был спроецирован файл, и если данные меняются, то изменение отражается и в файле. Но существуте режим copy-on-write, при котором модификация спроецированной страницы приводит к тому, что такая страница перестаёт быть проекцией изначального файла, то есть перестаёт быть image-backed. В момент модификации такой страницы под неё выделяется страница из файла подкачки и с момента модификации изменённая копии страницы начинает жить в файле подкачке, то есть становится swap-backed страницей. Файл, который был спроецирован, при этом не изменяется. Страницы АП, полученные в результате проекции, которые не были изменены с момента проекции, продолжают быть проекцией этого самого файла. Лишь те страницы, которые после проецирования были изменены, преобразуются в страницы, данные которых хранятся в файле-подкачки.
Именно этот режим copy-on-write используется при проецировании исполняемых файлов (EXE/DLL/OCX).
—We separate their smiling faces from the rest of their body, Captain.
—That's right! We decapitate them.
—That's right! We decapitate them.
- tych
- Начинающий
-

- Сообщения: 13
- Зарегистрирован: 03.12.2013 (Вт) 0:16
- Откуда: Russia, Kaliningrad
Re: Как победить "Out of memory"?
![]() tych » 01.03.2016 (Вт) 11:43
tych » 01.03.2016 (Вт) 11:43
kugeod писал(а):к примеру код:
- Код: Выделить всё
dim massive(40000,40000) as byte
выдаст ошибку "Out of memory".
Выдаст. В среде VB6, ибо программе, напару со средой (они будут в одном процессе), памяти в 2 Гб действительно не хватит. В скомпилированном виде отдельно от среды - работать будет.
(P.S. Как выше объяснил Хакер - не всегда и не везде)
kugeod писал(а):Чтобы обрабатывать матрицы 80000 на 80000. Возможно ли это?
Возможно. С помощью шейдеров и более современного ЯП для 64-х разрядных систем.
Ежели принципиален VB6 - забыть про скорость обработки и программно организовывать свой swap файл, или несколько (как в VB6 работать с файлом, размером больше 4-х и даже 2-х гигабайт, я представляю плохо). Но это, как говорится, долго, дорого и ... лучше посмотреть в сторону SQL (Но при этом все равно придется работать с "порциями" данных и пересматривать архитектуру программы). Лет 15 назад встречал серьезную программу-дополнение для DataMine, писанную на VBA, и пользовавшую MSSQL для обработки больших (миллионы 3-х мерных точек) данных. Тужилась, думала, но справлялась.
В остальном, опять-же, выше - Хакер все очень досконально объяснил. Основной упор на "при этом все равно придется работать с "порциями" данных и пересматривать архитектуру программы"
Сообщений: 11
• Страница 1 из 1
Кто сейчас на конференции
Сейчас этот форум просматривают: нет зарегистрированных пользователей и гости: 2